

异构计算的软硬件分割没有最好,只有更好的详细资料概述
描述
我们有飞机、汽车、轮船、自行车、地铁、高铁、公交车、双腿等各种交通工具,各自有优缺点,举个例子,阿呆从上海出差去北京卖书,整个流程是:
1. 打车到虹桥高铁站:灵活机动,运量小,24小时运营,经常堵车;
2. 坐高铁到北京南站:高速,运量大,路线、时间和起始站点有限制,建设周期长;
3. 从北京南站坐地铁到奥林匹克公园地铁站:市内速度稳定,运量大,时间和起始站点有限制,建设周期长;
4. 从地铁站走路到国家会议中心新书签售:慢,但是方便,两条腿,没有路都能走出一条路。
可以看出,一次旅行,其实结合了各种交通工具的优点。随着摩尔定律的失效和CPU在AI等并行计算方面的缺陷,目前数据中心的计算机,已经不仅仅是CPU一种计算芯片,还要结合GPU和FPGA做异构计算体系。
CPU是出租车,方便灵活,但是要等红绿灯,市区内道路多,有限速,运量小,车多了还堵车;FPGA是高铁和地铁,运量大,但是建设周期长,只能部署在人流量最大的线路上。
我们做异构计算的软硬件分割也是遵循同样的思想,普通的控制程序还是交给CPU执行,把计算量最大、最耗时间的任务转移到FPGA上执行,达到硬件加速的目标。
软硬件最佳分割方案:理论上无解
如下图,一个程序,通过对程序进行分割,把任务分解到CPU和FPGA、GPU、AI芯片等加速器执行。如果我们把程序分成N段,那么每一段都有两个选择:软件或者硬件,最后N段程序有2^N种分割方案,所以,最终要分段程序,寻找分配到软硬件的最佳方案是一个数学上有名的NP难题,解不出来。。。
我们没办法算出一个理论上的最佳方案,只能是不断逼近,没有最好,只有更好。
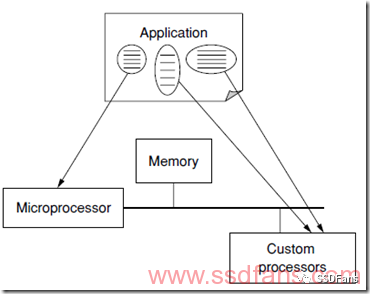
我们希望有一天能做到像下面这张图一样,我们写好的C/C++/Java等代码,编译后,自动分解成软硬件执行的程序,软件的交给CPU执行,硬件的让FPGA执行。尽管很难,但是还是要有梦想,万一实现了呢?
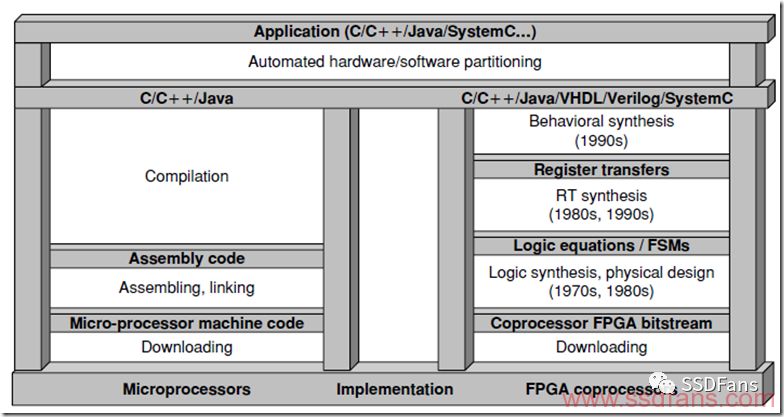
阿姆达尔定律
现在有很大一批人,对新的产品和技术比较排斥,觉得很low,没有技术含量。可是,任何一个新东西,刚出来的时候就是很简单,慢慢才变得复杂。比如区块链、深度学习、量子通信这些热门的技术,一开始实践的时候并不是很复杂。
1967年,有一位IBM的计算机科学家叫做阿姆达尔(Amdahl),他写了一个很简单的公式,却成了并行计算领域的基本定律。阿姆达尔定律说,一个程序能被硬件加速多少倍,其实取决于不能被硬件加速的那段程序。比如四分之三的程序可以通过并行计算、流水线等技术被硬件加速,但是有四分之一的程序还是得顺序执行,那么加速最大的倍数就是四分之三的程序几乎不花时间就算完了,用了四分之一的时间执行剩下不能加速的程序,最终可以加速4倍。
我们也知道这叫短板效应,木桶的容积是最短的那块板决定的。我们中国现在高铁、电视、冰箱、移动支付、共享单车、轮船都能做到世界第一,但就是芯片不能造,导致国家还是受制于人(美帝)。
当然,这个程序的占比不是按照代码的长短算的,而是按照程序执行的时间划分。为了达到最好的硬件加速效果,我们要把最占时间的程序都放到FPGA去。
关于这个定律的详细解释请参考科大陈国良院士的《并行计算机体系结构》一书2.3.1节。
90%/10%定律
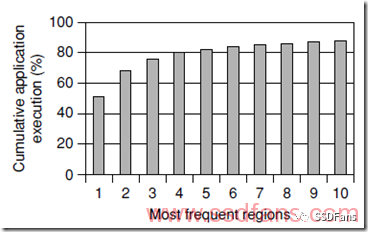
上面这张图是对一个程序中执行最多的的10段代码占用时间的累计,符合90%/10%定律:10%的代码执行占用了90%的程序运行时间。
所以我们很幸运,不需要操心那么多软件代码,只需要把最关键的10%代码转移到FPGA就可以了。
软硬分割的考虑因素
我们在对一个程序做软硬分割时,需要回答以下几个问题:
1. 程序分段粒度多大?
2. 分割方案的评估
3. 每段分区有哪些实现方案?
4. 软硬件如何交互?
5. 计算占用的面积。
程序分段粒度多大?
其实就是要把程序里的哪几段代码下放到硬件去,开小灶。这个代码段要分到多细?如果太粗,那么操作比较简单,花的时间少,但是最终效果可能没那么好。分的太细,又太花时间,每一段都要分析和推算,考虑软硬件交互,甚至需要专门的工具去做。
最简单的办法就是挑几个关键的函数、算法或者for/while循环放到硬件去加速。
分割方案的评估
如果我们要确定软件和硬件分工的方案,就需要评估和对比几个方案,从性能、成本、功耗等几个方面来评价。项目一开始,其实做不了太精确的评估,只能是粗糙的做一个估算,看看到底要用到多少LUT、RAM和乘法器、硬件IP等资源,再估算性能和延迟。
等到大体确定了一个目标方案,就可以写代码,用综合工具做一个综合,就能得到比较精确的资源占用情况。
不同的实现方案怎么选择?
对于每一段要硬件加速的软件程序,硬件上都有不同的实现方案。如下图,是100个乘法的例子,有三个方案:
(a)方案用了100个乘法器,性能最强,用的资源也最多;
(b)方案用了1个乘法器,要排队乘100次才能算完,性能最差,用的资源最少;
(c)方案用了10个乘法器,每个用10次,性能和资源都比较折中。
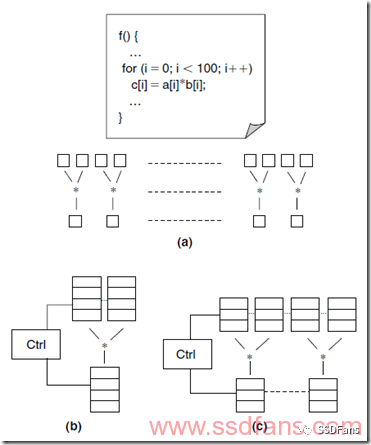
所以,最终采用什么方案要根据实际的需求和FPGA的大小来确定,FPGA不是ASIC,资源没有那么多,能省则省。
软硬件如何交互?
本来是一个顺序执行的软件程序,我们拆出了一部分放到FPGA去执行,所以就涉及到软硬件交互的问题。如下图(a),
左边是同步方案,软件干完,就让FPGA干,软件在旁边等,这样交替干活。这种方案比较傻瓜式,简单易行。而且性能不一定差,因为硬件计算快,软件可能等一会儿就好了。
右边是异步方案,软件和硬件各干各的,同时工作,效率高,但是控制比较复杂,毕竟涉及到一些共享的数据,处理起来比较麻烦。如果硬件计算时间长,软件等得久,就可以考虑这种模式。
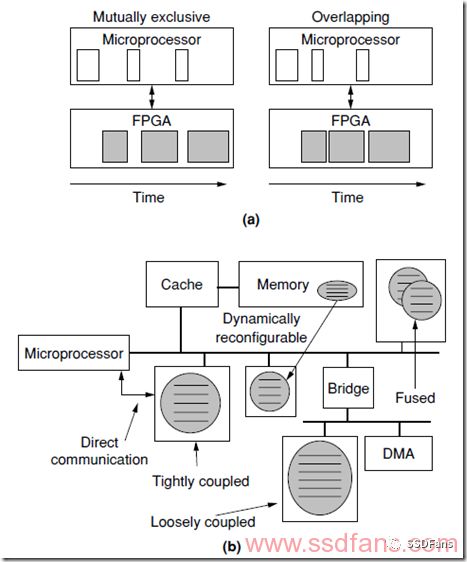
另外,还要考虑软硬件的通信方式,如上图(b),是各种通信方案,有的通过共享内存,有的是通过CPU直连、共享缓存,还有像牛郎织女一样搭一座桥互联。还有几个硬件加速器之间绑定在一起和CPU通信,还是分开,都需要考虑到。
用AI辅助软硬件划分
传统的硬件加速项目流程如下:
1. 确定要加速的软件程序;
2. 架构师通过评估和统计数据、性能计算确定软硬件分离方案和硬件架构;
3. 工程师开始写代码、仿真、验证、测试。
但是,也有一些自动化工具来智能评估软硬件分割方案。前面说过,理论上是找不到最佳方案的,因为计算量是个天文数字,我们只能不断逼近。逼近的方法如下:
1. 把程序切分成几段,给出软件和硬件时间、硬件资源,算出一个评估结果。
2. 再随机把程序分段,算出一个评估结果,看看是不是更好,如果更好,就用这个方案。
3. 继续迭代。
上面的方法采用了随机数的方法,不断找到更优解。但是,如今随着AI的日渐成熟,我们相信,也会有人会用AI技术来寻找更好的自动化软硬件分离方案。
-
异构计算在人工智能什么作用?2019-08-07 0
-
什么是异构并行计算2021-07-19 0
-
TSC峰会回顾04 | 异构计算场景下构建可信执行环境2023-04-19 0
-
异构计算场景下构建可信执行环境2023-08-15 0
-
异构计算芯片的机遇与挑战2017-09-27 985
-
异构计算的两大派别 为什么需要异构计算?2018-04-28 22698
-
KeyStone处理器的硬件系统设计详细资料概述2018-04-28 1259
-
蓝牙无线数据传输软硬件和测试程序的详细资料概述2018-06-19 834
-
异构计算,你准备好了么?2018-09-25 355
-
ARM9教程之软硬件设计的详细资料说明2019-03-13 1318
-
赛灵思解读异构计算2019-07-30 3466
-
嵌入式系统设计教程之软硬件功能划分的详细资料说明2019-07-26 1169
-
三菱PLC FX5U的硬件手册详细资料概述2019-11-18 1897
-
异构计算的前世今生2021-12-17 3915
全部0条评论

快来发表一下你的评论吧 !
