

Airbnb机器学习和数据科学团队经验分享
电子说
描述
Airbnb资深机器学习科学家Shijing Yao、前Airbnb数据科学负责人Qiang Zhu、Airbnb机器学习工程师Phillippe Siclait分享了在Airbnb产品上大规模应用深度学习技术的经验。
Airbnb在旧金山的新办公室
世界各地的旅行者在Airbnb平台上寻找旅途中的民宿。除了位置和价格之外,展示照片是房客搜索时做出决策的最关键因素之一。然而,直到最近之前,我们对这些重要的照片所知甚少。当房客在交互界面查看展示照片时,我们之前没有办法能够帮助房客找到信息量最大的图像,也无法确保照片传达的信息是精确的,也没法以可伸缩的方式向房主建议如何提高照片的吸引力。
多亏了计算机视觉和深度学习方面的最新进展,我们得以利用技术手段在较大规模上解决这一问题。我们从一个归类展示图片的项目开始。一方面,归类使得同一类房间的照片可以分为一组。另一方面,归类也能帮助检查是否基本的房间信息是正确的(验证房间数)。我们还相信,未来有很多激动人心的机会可以进一步增强Airbnb的图像内容的知识。我们将在本文结尾展示一些例子。
图像分类
能够正确分类给定的展示照片的房间类型,对优化用户体验而言是极有帮助的。从房客的角度来说,这使得Airbnb可以根据不同的房间类型重新排序、重新布局照片,优先展示人们最感兴趣的照片。从房主的角度来说,这可以帮助Airbnb自动审核展示照片,以确保房主遵守了Airbnb的标准。精确的照片归类是这些核心功能的基石。
我们打算分类的第一批房间类型包括卧室、浴室、起居室、厨房、游泳池、景观。我们计划基于产品团队的需求增加其他房间类型。
房间类型分类问题大体上和ImageNet分类问题差不多,只不过我们的模型的输出是定制的房间类型。这意味着VGG、ResNet、Inception之类现成的当前最先进深度神经网络(DNN)模型无法直接应用于我们的案例。网上有很多非常棒的帖子告诉人们如何应对这一问题。基本上,我们应该:1) 修改DNN的最后几层,确保输出维度匹配我们的需求;2) 再训练DNN的部分网络层,直到取得满意的表现。在一些尝试之后,我们选择了ResNet50,因为它在模型表现和计算时间方面平衡得很好。为了让它兼容我们的案例,我们在最后附加了两个额外的全连接层,以及softmax激活。我们也试验了一些训练选项,详见下节。
再训练修改过的ResNet50
修改过的ResNet50架构架构。基础模型图取自Kaiming He
再训练ResNet50可以分为三大场景:
固定基础ResNet50模型,仅仅使用最少的数据再训练增加的两层。这也经常称为微调。
进行第一个场景中的微调,不过使用大量数据。
从头开始重新训练整个修改过的ResNet50模型。
大部分网上的教程使用的都是第一种方法,因为这很快,而且通常能够取得不错的结果。我们尝试过第一种方法,并且确实得到了一些合理的初始结果。然而,为了运行高品质的图像产品,我们需要戏剧性地提升模型的表现——我们的理想是达到95%+准确率,80%+召回。
为了能够同时达到高准确率和高召回,我们意识到使用大规模数据重新训练DNN是不可避免的。然而,我们遇到了两大挑战:1) 尽管我们有很多由房主上传的展示照片,我们没有相应的精确的房间类型标签,实际上很多照片根本没有标签;2) 再训练ResNet50这样的DNN绝非易事——需要训练超过两千五百万参数,需要强力的GPU支持。我们将在接下来的两小节介绍我们是如何应对这两项挑战的。
监督学习图像说明
许多公司利用第三方服务商取得图像数据的高品质标签。由于我们有数以百万计的照片需要标注,显然这不是最经济的做法。为了平衡成本和表现,我们以一种混合的方式处理这一标注问题。一方面,我们请服务商标注了相对而言数量较少的照片,通常以千计,或以万计。这部分标注过的数据将作为我们评估模型的金数据集。我们通过随机采样得到了这一金数据集的照片,并确保数据没有偏差。另一方面,我们利用房主创建的图像说明作为房间类型信息的代理,从中提取标签。这一想法对我们而言意义重大,因为它使得昂贵的标注任务基本上变为免费。我们只需要一种明智的方法,确保从图像说明中提取的房间类型标签是精确可靠的。
一个很有吸引力的从图像说明中提取标签的方法是这样的:如果我们在某张图像的说明中找到了特定的关键词,那么这张图像就会被打上该类型的标签。然而,现实世界要比这复杂得多。如果你检查根据这一规则得到的结果,你将大失所望。我们发现由大量情形图像说明和图像的实际内容相差甚远。下面是一些例子。
上图展示了在图像说明中搜寻特定关键词导致的错误标签:(黑体为错误标签)
厨房:通往卧室和厨房的楼梯
起居室:从起居室通往卧室的过道
浴室:主卧包含浴室和特大床
卧室:从卧室往外看的景观
游泳池:由大量空间可以散步,游泳池旁边的花园
景观:从厨房看到的起居室(译者注:view of liing space from Kitchen的view被错误提取为景观标签)
为了过滤这样的例子,我们增加了额外的规则。经过若干回合的过滤和检查,标签的质量大大改善了。下面是一个规则的例子(过滤厨房图像)。
AND LOWER(caption) like '%kitchen%'
AND LENGTH(caption) <= 22
AND LOWER(caption) NOT LIKE '%bed%'
AND LOWER(caption) NOT LIKE '%bath%'
AND LOWER(caption) NOT LIKE '%pool%'
AND LOWER(caption) NOT LIKE '%living%'
AND LOWER(caption) NOT LIKE '%view%'
AND LOWER(caption) NOT LIKE '%door%'
AND LOWER(caption) NOT LIKE '%table%'
AND LOWER(caption) NOT LIKE '%deck%'
AND LOWER(caption) NOT LIKE '%cabinet%'
AND LOWER(caption) NOT LIKE '%entrance%'
由于这些额外的过滤,我们损失了相当可观的图像数据。对于我们而言这不是很大的问题,因为即使经过了如此激进的过滤,我们还是得到了几百万照片,每种房间类型有几十万照片。不仅如此,这些照片的标签质量要好很多。我们假定过滤并没有改变数据分布,我们将在使用金数据集测试模型时验证这一点。
话是这么说,或许我们本可以使用一些NLP技术来动态聚类图像说明,而不是使用基于规则的启发式方法。不过我们决定目前使用启发式方法,在未来再尝试NLP技术。
模型构建、评估、部署
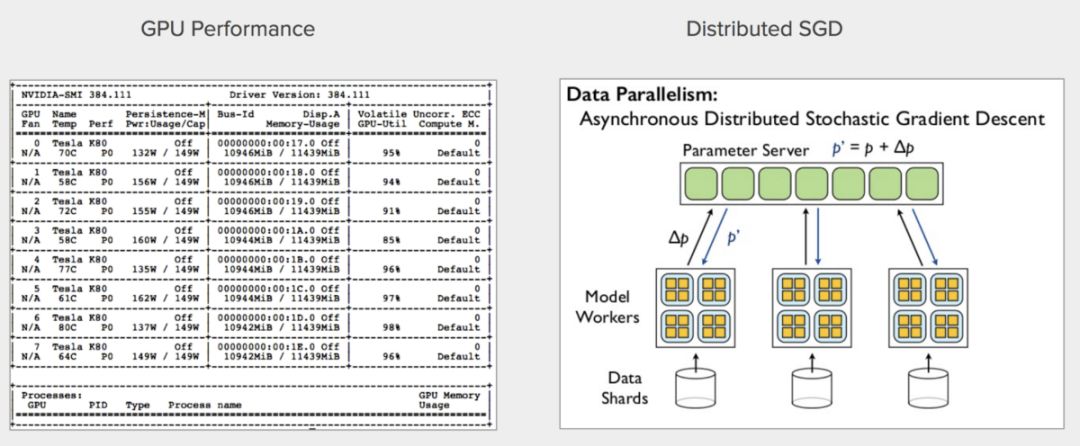
左:8核GPU并行训练;右:分布式SGD(引用自Quoc V. Le)
使用几百万张图像再训练像ResNet50这样的DNN需要大量的计算资源。我们的实现使用了一个AWS P2.8xlarge实例(Nvidia 8核K80 GPU),训练的每一步传送128张图像至8个GPU核心。我们使用Tensorflow作为并行训练的后端。我们在并行化模型之后编译了模型,否则训练无法进行。为了进一步加速训练,我们使用预训练的imagenet权重初始化模型权重(imagenet权重来自keras.applications.resnet50.ResNet50)。经过3个epoch的训练(花了6小时)之后,我们得到了最佳模型。在此之后模型开始过拟合,验证集上的表现停止提升。
我们在生产环境部署的是多个二元分类模型(对应于不同的房间类型),而不是覆盖所有房间类型的多类模型。这并不理想,不过由于我们的模型服务基本上是离线的,因此多模型调用导致的额外延迟对我们的影响并不大。我们很快将在生产环境部署多类模型。
我们基于准确率和召回评估模型。我们也同时监控F1评分和精确度之类的测度。下面我们将要重述这些测度的定义。简单概括一下,准确率描述了我们对阳性预测的精确度的自信程度,而召回描述了阳性预测在所有实际阳性值上的覆盖率。准确率和召回通常彼此冲突。在我们的场景中,我们给准确率定了一个很高的标准(95%),因为当我们声称照片属于特定房间类型时,我们应该对此高度自信。

TP 真阳性;TN 真阴性;FP 假阳性;FN 假阴性
混淆矩阵是计算这些测度的关键。我们模型的原始输出是每个图像0到1之间的概率。为了计算混淆矩阵,我们需要首先设定一个特定的阈值,将预测的概率转换为0和1. 接着,以召回为x轴,以准确率为y轴,可以生成准确率-召回(P-R)曲线。原则上,P-R曲线的AUC(曲线下面积)越接近1,模型就越精确。
为了评估模型,我们使用了之间提到的金数据集,其中的标准答案标签由人类提供。有趣的是,我们发现不同房间类型的精确程度不同。卧室模型和浴室模型是最精确的房间类型,而其他模型就不那么精确了。为了节省篇幅,我们将仅仅展示卧室和起居室的P-R曲线。虚线的十字交汇点代表给定特定阈值后的最终表现。我们在图形中加上了测度总结。
卧室的P-R曲线
起居室的P-R曲线
两点重要的观察:
卧室模型的总体表现要比起居室模型好很多。可能的解释为:1) 卧室比起居室更容易分类,因为卧室的布局相对标准,而起居室的变化较多。2) 从卧室照片中提取的标签质量高于从起居室照片中提取的标签,因为起居室偶尔也包括饭厅甚至厨房。
对每种房间类型而言,完全再训练的模型(红色曲线)表现优于部分再训练的模型(蓝色曲线)。同时,相比卧室模型,起居室模型上两者之间的差距更大。这暗示了再训练完整的ResNet50模型在不同房间类型上的影响不同。
我们交付的6个模型,准确率一般高于95%,召回一般高于50%。通过设定不同的阈值,可以折衷准确率和召回。模型支撑了Airbnb的多个产品团队的不同产品。
用户比较了我们的结果和知名的第三方图像识别API。据报告我们的内部模型总体而言超越了第三方的通用模型。这暗示了利用你自己的数据的优势,你有机会在你感兴趣的特定任务上超过业界的当前最先进模型的表现。
我们想要展示一些具体的例子,作为本小节的结束。
分类之外
在进行这个项目的时候,我们也尝试了房间类型分类以外的一些有趣的想法。我们想在这里展示两个例子,让读者大致了解这些问题多么让人激动。
无监督场景分类
当我们首次尝试使用预训练的ResNet50模型分类房间类型时,我们生成了图像嵌入(2048x1向量)以展示题图。为了解释这些嵌入的含义,我们使用PCA技术将这些长向量投影至二维平面。出乎我们的意料,投影数据自然而然地聚类为两组:其中一个聚类几乎全是室内场景,另一个聚类则几乎全是室外场景。这意味着,在没有进行任何再训练的情况下,仅仅通过图像嵌入的主成分,我们就能判定室内场景和室外场景。这一发现开启了通向某个非常有趣的领域——迁移学习(嵌入)与非监督学习——的大门。
目标检测
我们尝试追寻的另一个领域是目标检测。在Open Images Dataset上预训练的Faster R-CNN模型已经能提供酷炫的结果。如你在下面的例子中所见,模型已经能够检测出窗、门、饭桌及其位置。我们使用Tensorflow目标检测API对展示照片做了一些快速评估。大量家用设施可以通过现成的模型检测到。未来我们计划使用Airbnb定制的设施标签再训练Faster R-CNN模型。由于开源数据中没有包含部分Airbnb定制标签,我们想要创建自行创建标签。有了这些算法检测到的设施,我们能够验证房主发布房源的质量,让有特定设施需要的房客更容易找到心仪的房屋。这将把Airbnb的照片智能的前沿推进至下一等级。
成功检测出窗、门、饭桌
结论
让我们总结一些可能对其他深度学习开发者有帮助的关键点:
深度学习不过是一种特定的监督学习方法。因此再怎么强调数据的高质量标签的重要性也不为过。由于深度学习通常需要大量训练数据以达到当前最先进的表现,找到标注的有效方式非常关键。幸运的是,我们找到了一个经济、可伸缩、可靠的混合方法。
从头训练像ResNet50这样的DNN可能需要费很大的力气。尝试从简单快速的方式开始——使用小数据集训练顶上几层。如果你确实有一个大型的可训练数据集,从头再训练DNN可能提供当前最先进的表现。
如果可以的话,并行化训练。在我们的案例中,我们通过使用8核GPU获得了大约6倍(拟线性)速度提升。这使构建一个复杂的DNN模型在算力上变得可行,迭代超参数和模型结构也容易许多。
-
【下载】《机器学习》+《机器学习实战》2017-06-01 0
-
前百度深度学习研究院科学家分享:机器视觉开发实战经验2018-07-20 0
-
5月份Github上最热门的数据科学和机器学习项目榜单概述2019-07-29 0
-
机器学习经验总结2019-08-16 0
-
如何完成机器学习的项目流程和数据清洗2020-04-26 0
-
什么是机器学习? 机器学习基础入门2022-06-21 0
-
分析、数据科学和机器学习平台最热语言_Python2018-06-28 1609
-
十大机器学习工具及数据科学工具2018-05-29 3609
-
2018年数据科学和机器学习工具调查2018-06-07 4035
-
Python网页爬虫,文本处理,科学计算,机器学习和数据挖掘工具集2018-09-07 1038
-
仔细研究用于机器学习和数据科学的十大Python工具2019-02-15 2409
-
机器学习与数据科学的区别2020-07-21 1095
-
机器学习的成功应用需要具备哪些能力和技能?2020-08-12 958
-
20个必知的自动化机器学习库(Python)2023-05-26 686
-
机器学习与数据挖掘的区别 机器学习与数据挖掘的关系2023-08-17 1519
全部0条评论

快来发表一下你的评论吧 !
