

如何让一辆自动驾驶汽车以最完美的速度上路?
电子说
描述
剑桥大学两位博士创办的公司使用强化学习算法,无需密集标注的3D地图,无需人工设计的规则,让汽车在短短20分钟内学会了自动驾驶。公司成立不到50天,已经拿到了优步首席科学家的投资。
今天的自动驾驶汽车虽然已经性能不错,但大多数自动驾驶汽车都使用大量的摄像头和传感器、地图工具和大量的计算机程序,比较不完美。
如何让一辆自动驾驶汽车以最完美的速度上路?有一种做法是增加操作系统的智能而不是传感器。
剑桥大学工程系的两位博士创办的Wayve团队使用强化学习算法,第一次实现让计算机学会像人一样,通过练习来完成自动驾驶。该算法与人类安全驾驶员一起教会了汽车如何在“15-20分钟”的时间内保持在一条车道内。
Wayve团队认为,自动驾驶需要的是一台更智能的电脑,而不是更多的传感器或程序,他们的研究也证明了自己的理论。
DeepMind玩Atari游戏需要数百万次试验,但深度强化学习让汽车20分钟内学会自动驾驶
DeepMind已经证明,深度强化学习方法可以在许多游戏中实现超越人类的表现,包括围棋、象棋和许多电脑游戏,而且几乎总是胜过任何基于规则的系统。
Wayve团队深得DeepMind和OpenAI经常使用的强化学习算法精髓,并且巧妙的用在了自动驾驶车上。
为了证明强化学习+自动驾驶这种方法可行,Wayve团队配置了一辆雷诺Twizy,它很简单,只配备了一个摄像头和油箱、刹车和转向控制等装置。算法使用“深度卷积神经网络”的模型,该模型接收仅使用一个GPU处理的单个图像的输入。
在视频中,最初,汽车就像婴儿迈出了第一步,步履蹒跚。但当汽车开始转向车道外时,一名安全驾驶员介入,重新把车转向车道内。算法了解到每次修正行驶过程时都是在纠错,并根据它在没有任何干预的情况下行进了多远而得到“奖励”。
通过这种方式,计算机能够在大约20分钟内学会如何防止汽车从路上跑偏。在那之后,它可以无限期地行驶下去。
Wayve团队的这项研究表明,类似的哲学在现实世界中也是可能的,特别是在自动驾驶汽车中。而且,DeepMind玩Atari游戏的算法需要数百万次试验才能解决一个任务。而Wayve的团队在不到20次的试验中就学会了让车始终“沿着单行道行驶”。
无需密集标注的3D地图,无需人工设计的规则
大型科技公司做自动驾驶通常采用工程思维方法,即设计一种基于规则的系统,处理每一个边缘问题,同时使用更多的传感器,获取更多的数据。这可能会在特定的、狭义的环境中产生令人鼓舞的结果,但并不能真正解决自动驾驶问题。
Wayve的团队是第一个自动驾驶汽车在线学习的例子,每一次尝试都会使它变得更好。那么,具体是怎么做到的呢?
他们给出了技术细节:
他们采用了一种流行的无模型深度强化学习算法——深度确定性策略梯度(deep deterministic policy gradients,DDPG)来解决车道跟踪任务。模型输入是来自单目摄像机的图像。系统迭代了3个过程:探索,优化和评估。
网络架构是一个深度网络,有4个卷积层和3个完全连接层,总共只有不到10k个参数。相比之下,目前表现最优的图像分类架构有数百万个参数。
所有的处理都在汽车的一个图形处理单元(GPU)上进行。
将机器人放到危险的真实环境中工作会带来很多新问题。为了更好地理解手头的任务,找到合适的模型架构和超参数,他们在模拟环境中进行了大量的测试。
上图是一个例子,从不同角度展示了车辆在模拟环境中如何沿着道路行驶。该算法仅看到驾驶员的视角,即上图中间。在每个episode,随机生成一条弯曲的车道,以及道路的纹理和车道标记。agent一直在探索,直到偏离了车道,此时一个episode结束。然后根据搜集到的数据进行策略优化,一直重复这个过程。
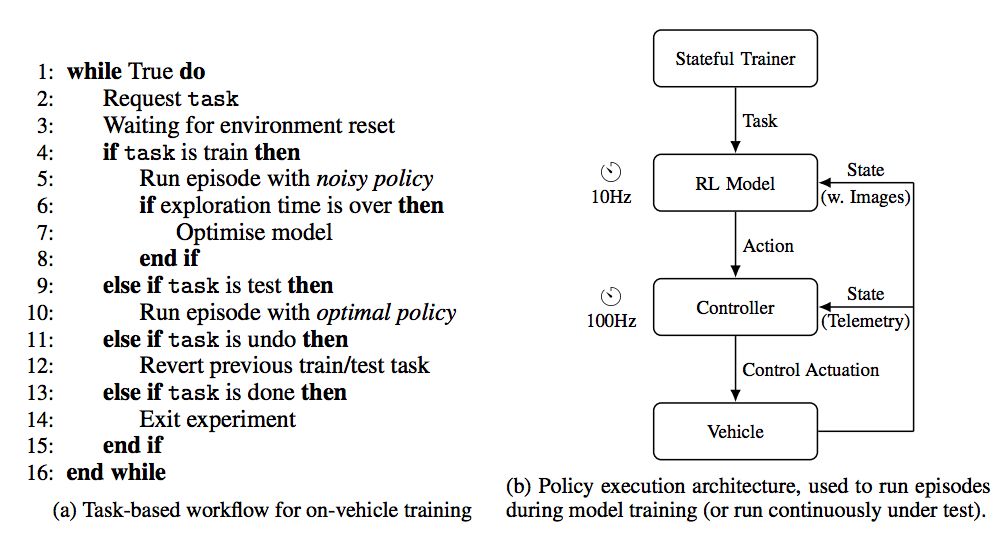
基于任务的workflow和训练算法的架构
团队使用模拟测试来尝试不同的神经网络架构和超参数,直到找到仅需很少的训练次数(也就是在只有很少数据的情况下),始终能解决车道跟踪任务的设置。例如,一个发现是,使用自动编码器重建损失来训练卷积层,这大大提高了训练的稳定性和数据效率。
使用DDPG+VAE,极大地提高了从原始像素进行DDPG训练的数据效率,这表明在实际系统上应用强化学习时,state representation是一个重要的考虑因素。实验使用的250米行驶路线如右图所示。
下表是在250米道路上实现自动驾驶车辆的强化学习结果。

团队报告了每个模型的最佳性能。他们观察到baseline RL智能体可以从头开始学习车道跟踪,但VAE变体更有效率,仅在11次训练后就成功学会沿着车道驾驶。
想象一下,部署一个自动驾驶汽车的车队,一开始自动驾驶算法是人类驾驶员表现的95%。这样一个系统不会像视频中随机初始化的模型那样摇摇晃晃,而是几乎能够处理交通信号灯、环形路、十字路口等等各种情况。
经过一天的驾驶和人类安全驾驶员接管提供的反馈,系统能够在线提升,也许能提升到96%。一个星期后,提高到98%;一个月后,达到人类表现的99%。几个月后,这个系统的表现可能以及超过了人类,因为它能从多名安全驾驶员的反馈中获益。
在20分钟内就学会了从零开始沿着车道行驶,那么,想象一下,一整天的话可以学到什么?
两位剑桥博士创办,公司成立不到50天已获优步首席科学家投资
Wayve于今年5月22日刚刚创立,创始人是两位来自英国剑桥大学的博士Amar Shah和Alex Kendall。
Wayve团队现有约10名成员,由来自剑桥大学和牛津大学的机器人、计算机视觉和人工智能专家组成,他们之前曾在NASA、谷歌、Facebook、Skydio和微软等公司工作过。他们专注于利用深度学习解决视觉场景理解、不确定环境中的自主决策等问题。
值得一提的是,剑桥大学教授、Uber首席科学家Zoubin Ghahramani是Wayve的投资人之一。
不同于大部分自动驾驶车辆的传统思维,Wayve团队号称要构建“端到端的机器学习算法”,将强化学习方法用于自动驾驶汽车。他们认为制造真正的自动驾驶汽车的关键在于软件的自学能力,它需要的是更好的协调,这能够使自主驾驶成为现实。
-
福特利用机器人开发能"远距遥控"的半自动驾驶系统2015-03-04 0
-
能自动驾驶难道还要人工充电?2016-03-03 0
-
【话题】特斯拉首起自动驾驶致命车祸,自动驾驶的冬天来了?2016-07-05 0
-
[科普] 谷歌自动驾驶汽车发展简史,都来了解下吧!2016-10-25 0
-
因为「不够安全」,我们就必须拒绝自动驾驶汽车上路?2017-04-08 0
-
自动驾驶的到来2017-06-08 0
-
【威雅利 汽车】苹果最新专利曝光,要把VR和AR带进自动驾驶汽车2018-04-24 0
-
自动驾驶零排放汽车让世界更加绿色2019-03-11 0
-
车联网对自动驾驶的影响2019-03-19 0
-
如何让自动驾驶更加安全?2019-05-13 0
-
自动驾驶汽车的处理能力怎么样?2019-08-07 0
-
自动驾驶的五大传感器各有千秋2020-05-13 0
-
如何保证自动驾驶的安全?2020-10-22 0
-
边缘计算在自动驾驶汽车的应用2021-07-12 0
-
如何从无到有打造一辆自动驾驶车?(硬件篇)精选资料分享2021-07-27 0
全部0条评论

快来发表一下你的评论吧 !
