

低功耗目标检测系统设计挑战赛:中科院、清华分获GPU与FPGA组冠军
电子说
描述
2018 年 6 月 28 日,由电子自动化设计顶级会议 DAC' 2018 主办的「低功耗目标检测系统设计挑战赛」于加州旧金山于落下帷幕。来自中科院计算所的 ICT-CAS 团队和来自清华大学的 TGIIF 团队在全球 114 支参赛队伍中脱颖而出,分获 GPU 组和 FPGA 组的冠军。本届比赛旨在为无人机设计高精度且高能效的物体检测系统,以满足实际复杂场景的需要。比赛任务极具挑战性,参赛设计需要考虑小物体及被遮蔽物体检测,需要区分同场景多个相似目标,也需要考虑检测速度及功耗等多方面因素。参赛队伍来自清华大学、北京大学、中科院、UIUC、CMU、IBM、Cadence 等全球多个优秀科研机构。
转自机器之心
无人机在工业、农业、军事及消费级市场均有如土地测绘、巡检监测、物资配送、灾后救援等重要作用。其中,实现高精度且高能效物体检测是开展所有无人机任务的基本要素,也是本领域急需提高的方向。由于航拍数据集(无人机视角)的缺失,进一步提升无人机物体检测系统变得更加困难。
在这样的背景下,圣母大学的史弋宇教授,匹兹堡大学的胡京通教授,香港城市大学的余备教授和 Cognite Ventures 公司的 CEO Christopher Rowen 发起「低功耗目标检测系统设计挑战赛」,并在 DAC' 2018 成功举办。该比赛由 Nvidia、Xilinx 和 DJI 大疆创新赞助,由圣母大学博士后徐小维和匹兹堡大学博士生张鑫燚进行评测。Nvidia 和 Xilinx 分别为 GPU 和 FPGA 组的参赛队伍提供免费的嵌入式计算设备 TX2 GPU 和 PYNQ Z-1 FPGA。大疆创新为比赛提供了高达 150k 份由无人机在实际环境中采集的数据并提供了准确标注。
比赛中使用到的两种硬件平台: TX2 GPU(左)和 PYNQ Z-1 FPGA(右)
比赛从 2017 年 10 月 16 日正式开始,于 2018 年 5 月 28 日结束,共吸引 114 支来自全球多个科研机构的队伍参加。其中,53 支队伍参与 GPU 组比赛,61 支队伍参与 FPGA 组比赛。最终,两个组别前三名的队伍将被邀请至旧金山,在DAC' 2018 上接受颁奖。同时,获奖队伍将能在大会上分享他们的设计并进行现场展示。
挑战 1: 小物体及遮蔽物检测
由于所有图片均在无人机视角下拍摄,大量图片中的待检测物体都非常小,且有很大的概率被树木和建筑物遮挡。这些物体本身的特征在如此小的尺度下会大大提升检测的难度。
小物体检测:绿色框对应行驶中的汽车为检测目标
挑战 2: 同一物体检测
与传统的物体检测不一样,本次比赛需要参赛队伍检测同一个物体。在无人机跟随应用中,无人机需要准确地检测出指定物体(如无人机操控者、车辆、动物等)并进行跟随飞行。当场景出现多个相似物体时,无人机也不能跟丢或跟错对象。此应用给物体检测带来了新的挑战。
特定行人检测:绿色框对应的是正确的检测目标,蓝色和红色狂均对应错误的行人。
挑战 3:高精度 vs 低功耗
比赛采用的评价指标是精度,速度和能耗的结合(评分细则详见 1)。考虑到 GPU 组及 FPGA 组使用了不同的计算能力硬件设备,比赛对检测速度提出了不同的要求。其中 GPU 设计需运行至 20 FPS,FPGA 设计需达到 5 FPS。
GPU 组前三强
GPU 组的前三名分别是中科院计算所的 ICT-CAS 团队,浙江大学的 DeepZ 团队和山东大学的 SDU-Legend 团队。三个队伍均采用了深度学习完成比赛,也都采用 Yolo 神经网络作为他们的基础设计。

GPU 组第一名: ICT-CAS
ICT-CAS 团队使用了 feature extractor, tucker decomposition and precision scaling 相关技术。在每一种具体的方案中尝试了多种技术记忆组合以减少计算和内存消耗。在计算中采用了半精度(16bits)进行计算并使用 TensorRT 来提高计算速度。

GPU 组第二名: DeepZ
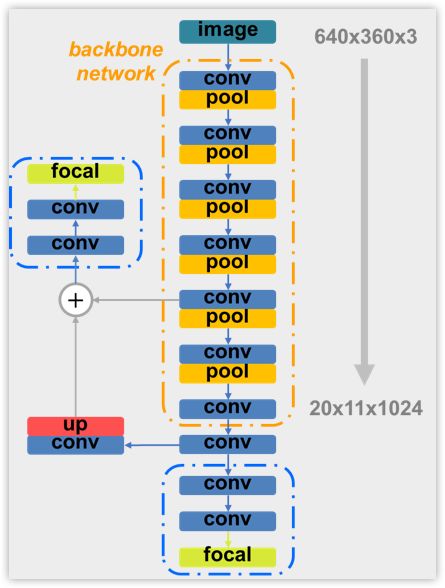
DeepZ 团队使用 Yolo-v2 作为骨干网络进行特征提取和检测。为了应对较小物体检测的问题,该团队使用了 Feature Pyramid Network 来获得上下文相关的特征。同时,focal loss function 的引入来缓解单一物体检测与多个候选框的不平衡问题。该团队 对 Yolo-v2 网络进行了一定的改进,改进后的网络结构如下图所示。
GPU 组第三名: SDU-Legend
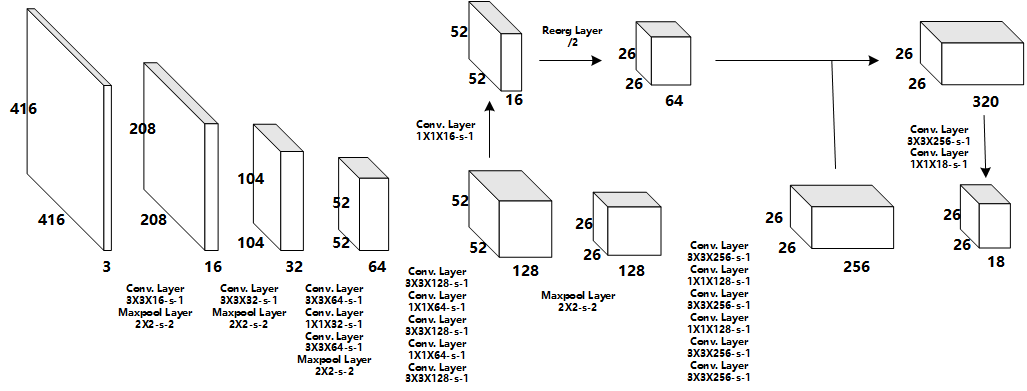
SDU-Legend 团队基于 Yolo v-2 进行优化。首先,该团队将 Yolo v-2 网络由 32 层删减为 27 层。其次,为了满足检测小目标的要求,该团队降低了下采样率。在体系层次,该团队也做了一些优化:将网络最后两层的计算放在 CPU 上进行。该团队实现了 16bits 的半精度计算来进一步提升计算速度。
FPGA 组前三强
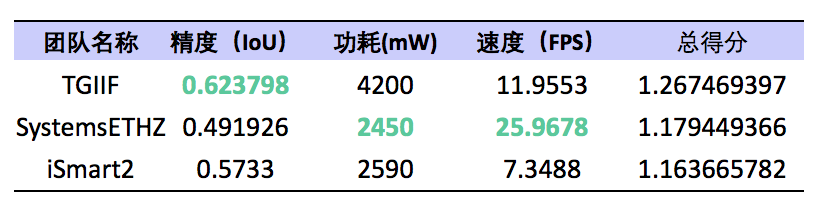
FPGA 组的冠军是来自清华大学的 TGIIF 团队,亚军是苏黎世联邦理工大学的 SystemsETHZ,季军来自 UIUC 的 iSmart2 团队。这三支参赛队伍分别在 FPGA 上部署了 SSD,SqueezeNet 和 MobileNet 神经网络,完成了比赛要求的物体检测任务。
FPGA 组第一名: TGIIF
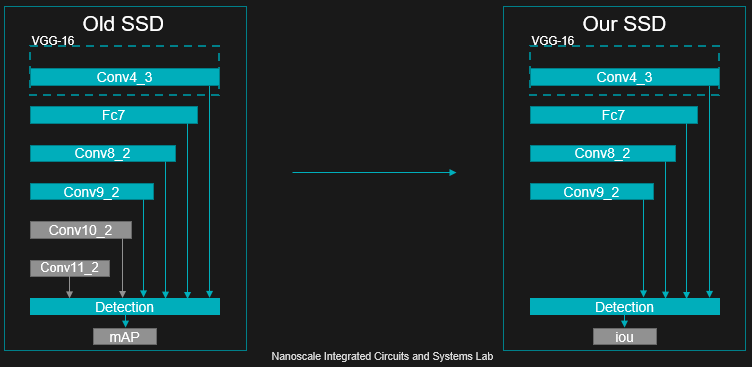
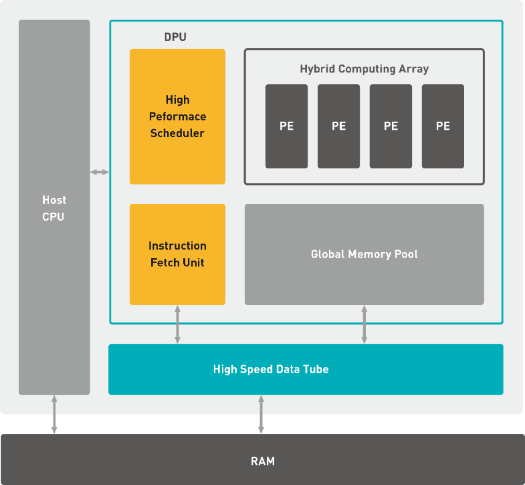
TGIIF 团队在采用了深鉴科技的硬件加速器架构 DPU、全栈式工具链 DNNDK 和深度压缩技术的基础上,从算法、软件和硬件对整个目标检测系统进行了全栈式的协同优化。通过采用硬件友好的 SSD 网络和多线程优化技术,结合深度压缩和定点训练,在保证识别精度的前提下,满足了低功耗和实时性的要求。
FPGA 组第二名: SystemsETHZ
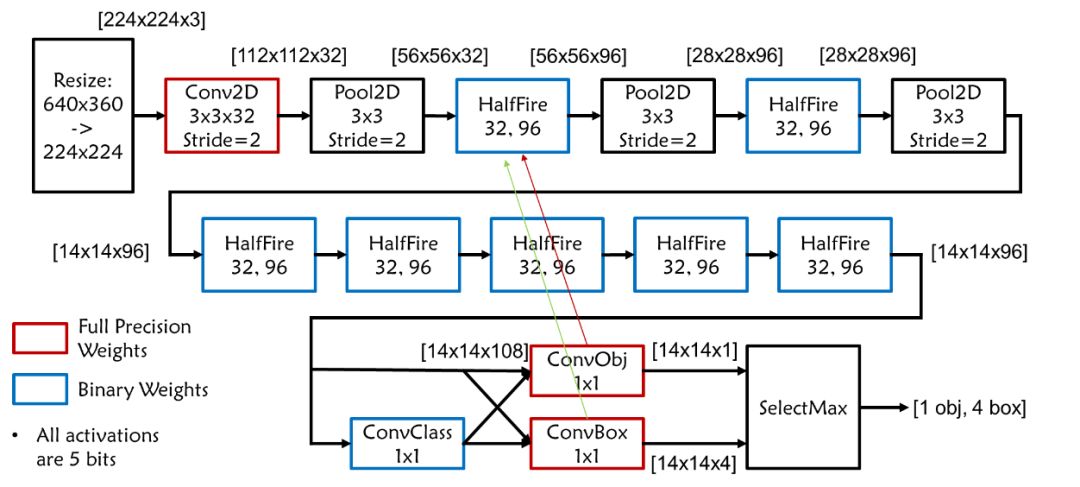
SystemsETHZ 团队使用低量化网络进行物体检测。特别的该团队采用 squeezenet 为基础进行设计,并将网络层数修改为 18 层。在具体的实现中,该团队采用了 folded computing 的方式来配置多路复用器和多路输出选择器进而实现神经网络不同阶段的计算。该团队使用一个 DMA 引擎实现 CPU 和 FPGA 间的数据传输。
FPGA 组第三名: iSmart2
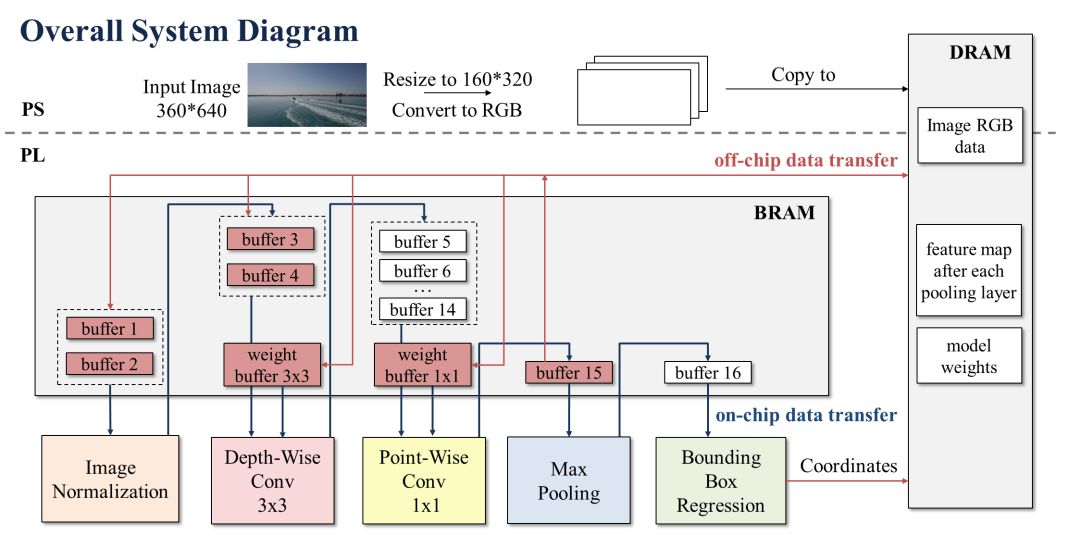
iSmart2 组采用以 Mobilenet 为基础的轻量化网络设计,共 12 层。网络包含 depth-wise 3x3 卷积层,传统 1x1 卷积层和 max pooling 层,并采用简化的 Yolo 后端进行物体检测。在硬件实现上,该团队采用基于模块(IP)复用的结构,让相同种类的网络层复用同一个模块以节约硬件资源。此外,该团队将每层特征图分割成大小相同的数据块,以数据块为单位进行计算,实现了数据块之间的细粒度流水线结构,以缩短图片的处理延时。
-
中科院电子技术考研真题2011-08-07 0
-
中科院剖析 LED怎样克服困难2012-07-18 0
-
LabVIEW挑战赛正式开赛,台北总决赛等着你!2014-05-23 0
-
Banana PI开源项目与中科院先研院举行开源硬件介绍交流活动2014-08-09 0
-
LabVIEW 挑战赛冠军选手代码分享2014-12-04 0
-
中科院深耕网络摄像机领域2015-02-05 0
-
【DIGILENT挑战赛】+电子相框2017-05-03 0
-
等个有“源”人|OpenHarmony 成长计划学生挑战赛报名启动2022-06-13 0
-
【PCB多层板设计挑战赛】+FPGA控制器2022-11-09 0
-
【获奖公示】华秋PCB多层板设计挑战赛获奖名单2022-11-22 0
-
【RA4M2设计挑战赛】低功耗远距离无线温度监控项目2023-02-23 0
-
【精品合集】瑞萨RA4M2物联网网关设计挑战赛作品合集2023-03-07 0
-
【获奖名单】瑞萨RA4M2物联网网关设计挑战赛获奖名单公布!2023-03-13 0
-
中科院发布“香山”与“傲来”两项开源处理器芯片2023-05-28 0
全部0条评论

快来发表一下你的评论吧 !
