

无监督学习的理论解释与实践教程
电子说
描述
无监督学习是推断描述“未标记”数据的分布与关系的机器学习任务,即给予学习算法的示例是未被标记的,因此没有直接的方法来评估算法产生的准确性。无监督学习根据应用任务的不同的算法也不尽相同,最常用应用的是聚类和降维。本次将为大家揭开无监督学习的面纱,通过和两只猫的故事对无监督学习进行简单易懂的解释,并通过对世界美食的探索之旅,开展对无监督学习的实践教程。
揭开无监督学习的面纱
▌前言
无监督式学习实际上是一种从数据中挖掘灵感与启发的模式发现技术。但是听起来好像在表达“让孩子们自己学会不要去碰热烤箱”这样的事情,其实无监督学习与机器在没有人监督的情况运行,形成对事物的看法没有任何关系。
接下来的内容就是为了帮助大家弄清楚到底什么是无监督机器学习!
如果下面几个概念都觉得有那么一点熟悉,那么后面的内容看的时候就不会觉得很难,无监督学习可能还会成为你的新朋友~
机器学习就是用实例来标记事物
如果你通过输入你所寻找的问题的答案(输入数据及其对应的标签)来训练你的系统,你正在进行监督式学习。
要开始监督学习,你需要知道你想要(给你输入的数据贴上)什么标签。(非监督式学习则不需要。)
标准术语包括实例(样本)、特性、标签、模型和算法。
▌什么是无监督式学习?
上面是六个实例,根据你自己喜欢的方式分成两组。是不是觉得缺了点什么? 这些照片没有任何的分类标签。不过不用担心,其实我们都很擅长这个任务—— 无监督学习。你可以思考一下,你会如何将这些图片分成两组,答案没有对错之分哦。
▌聚类数据
在一个课堂上,Google 的员工给出了一些答案如“坐着或站着”、“能看到木地板或不能看到”、“猫在自拍或猫不是在自拍”等等。让我们来看一下第一个答案。
一种将图像分成两组的方法:坐vs站。嗯,“坐着”和站着。
▌无监督式学习的秘密标签
如果您选择根据猫是否站着来进行聚类,那么系统输出是什么标签? 毕竟,机器学习就是标记事物。
如果你认为“坐着还是站着”是标签的话,这个就是您所用的聚类方法(模型)。其实无监督学习的标签更无趣:类似于“第一组和第二组”或“A或B”或者“0或1”。它们只是简单的表示群体成员,没有其他认为解释的含义。
无监督式学习的标签只是简单的表示聚类的成员。它们没有更高的人类解读的意义,有的只是令人失望的枯燥感。
这一切的完成都是借助算法根据相似性来对事物进行分组。相似度的度量是通过选择算法来指定的,但是为什么不尝试尽可能多的相似度度量呢? 因为你也不知道你在寻找什么,不过可以把非监督式学习看成是数学中的“物以类聚”。就像罗夏墨迹卡一样,其实你不用把你看到的内容看的太重。
▌再来一次
作为这两只猫的主人,我难过的是,在将近 50 次的教学中,只有一个人注意到他们应该被分类为“猫1和猫2”。大多数时候答案都是“坐着和站着”或“有无木地板”,有时甚至是“丑猫对漂亮的猫”。
这是我两只猫的照片! 也许现在你已经注意到了,但大多数人都没有注意到,除非我给他们贴上标签(监督学习)。如果我一开始就给这些数据贴上了名字标签,然后让你给下一张照片分类,我打赌你会发现这个任务很简单。
▌学习感悟
想象一下,假如我是一个刚入门学习数据科学的新手,还是刚开始学习非监督式学习,我对自己的两只猫感兴趣。当我看到这些图片时,我不会对我的猫视若无睹。
十年之前,不能指望计算机与世界上最好的模式查找器—— 人脑去竞争这类任务。这些对人们来说很容易!可又是为什么那么多的 Google 员工看到了这些没有标签的照片并没有得到“猫1与猫2”的答案呢?因为虽然一些东西对我们来说有趣却并不意味着我们的模式查找器会发现它。即使这个模式查找器非常棒,我也没有告诉它我要找的到底是什么。
那为什么我要期望我的学习算法能够实现呢?这又不是魔术!如果我不告诉它正确答案是什么,那么得到什么答案是我不会失望的。我所做的就是查看系统为我计算的聚类,如果我不喜欢这个结果,我就会一遍又一遍地运行另一种无监督式算法(这个过程就像“观众席上的其他人在用其他的方式区分它们”)直到找到我觉得有趣满意的为止。其实这也不能保证在这个过程中会有灵感启发的事情发生,但尝试一下也无妨。毕竟探索未知总是有一点冒险。
▌总结
无监督式学习通过把具有相似的事物分到一组而帮助你从数据中找到启发。有许多不同的方法来定义相似度,所以在直到一个很酷的模式吸引你的眼球之前,要持续不断的尝试算法和设置!
无监督学习的实践:探索世界美食之旅
▌背景
和很多人一样,我也是超级热爱美食的人。我很幸运在我的成长过程中,我们家里都是自己做饭,而我的妈妈负责为我们做出各种美食。因为她是从德国移民来了美国,所以我也接触过很多美味的德国菜,其中我最喜欢的有鸡蛋面, 水煮面粉球和酸味炖肉。虽然我不能说我继承了我妈妈的厨艺天赋,但我也非常喜欢喜欢做饭,喜欢和我的家人们分享这个过程。
出于自己对美食的热爱,我在想如果进行一个涉及世界各地美食的研究项目将会是一件很有趣的事情。我想看看我是否能从中了解到世界各 地不同美食间的关系。为了探索这个主题,我收集了超过12000种不同食谱的数据,这些食谱代表了25种不同的美食。然后,我通过使用自然语言处理技术将文本数据转换为一种可以输入机器学习算法中的格式。最后,我利用主成分分析(PCA)和主题建模来获得数据的更深层面的理解。
▌收集数据
在我的项目中数据均来自于 Yummly,我获得了他们的 API 授权。因此我可以直接从 ipython 上查询和搜索菜谱。Yummly 支持基于菜肴类型进行搜索,以下是他们所支持的菜肴类型的列表:
美式料理,意大利料理,亚洲美食,墨西哥料理,南部和灵魂料理,法式料理,西南部美食,烧烤,印度料理,中国料理,路易斯安娜州和克里奥尔料理,英国料理,地中海部分美食,希腊美食,西班牙料理,德国美食,泰国美食 ,摩洛哥料理,爱尔兰美食,日本料理,古巴美食,夏威夷美食,瑞典美食,匈牙利美食,葡萄牙美食。
我下载了25种菜系,每个菜系都有将近500份的食谱,总共下载了将近12500不同的食谱。关于数据收集, 我使用了 Requests 库进行读取数据,以及内置JSON 编码器将数据转换为 python字典。然后,再将数据转换成PandasDataFrame, 这个就相对简单了。如下面显示,在我的分析中,我只使用了对应于烹饪和配料的列而忽略了其他列。
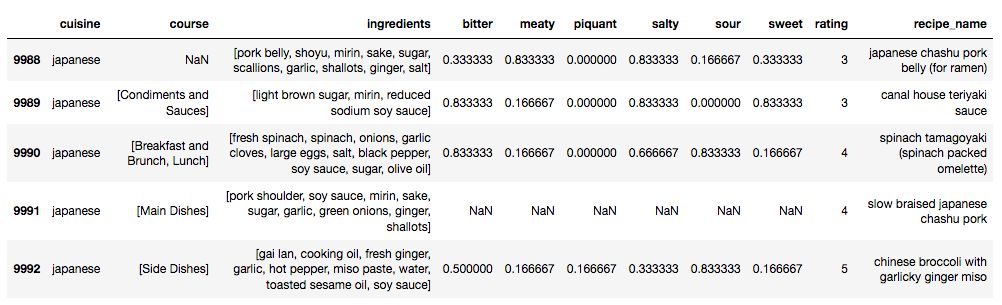
所选的Yummly食谱的数据列
▌文本数据处理和机器学习工作流程
由于数据只包含文本,因此有必要使用自然语言处理技术实现一些预处理步骤。包括的步骤如下:
1.连接某些成分(如:橄榄油、玉米淀粉)
2.将成分分解成单词列表
3.删除停止词和其他经常出现的词(如盐、胡椒、水)
4.删除词尾的复数形式和其他后缀
5.词库处理,创建一个稀疏矩阵,包含成分列表中的所有词以及它们出现的频率
用来实现这些步骤的工具包括在sklearn 中找到的 TfidfVectorizer 和 CountVectorizer。其中还有一些步骤,比如连字符和停止字删除,是我自己编写的代码来实现的,可以在 GitHub 上看到相关的代码。
在项目中我使用了机器学习的无监督算法,尝试做 K-Means 聚类,来确定是否可以根据烹饪类型将菜谱组合在一起,但是我发现聚类对我的分析并不是很有帮助,因为不清楚不同的聚类代表了什么。之后我将注意力集中在主成分分析(PCA)和主题生成模型(LDA)上,更多的结果分析接下来和大家一起讨论和分享。
▌结果分析
为了对数据进行可视化,需要先进行降维操作,从1982维的特征空间减少到2维,通过PCA 保留前两个主成分。然后我针对主成分创建了一个散点图,如下所示。
包含关于第一个和第二个主成分分析的所有12492份食谱的散点图
在绘制所有食谱的主成分散点图的过程中,因为许多数据点是重叠的,所以很难在数据中看到任何结构。然而,通过根据菜肴对食谱进行分组,并沿着两个主要成分取中间值,我可以在数据中看到一些有趣的结构。如下图所示。
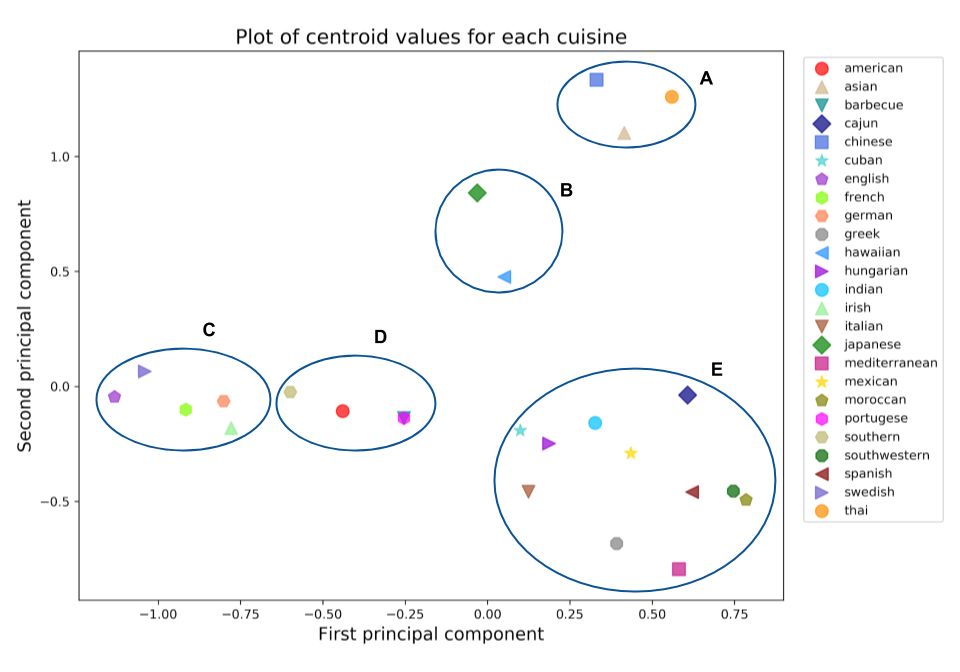
在第一和第二主成分上的每一种不同菜系的中心值的图。(A)组与亚洲菜系相关,(B)组由日本和夏威夷菜系组成,(C)组与(D)组分别是欧美菜系。Group (E)是一种来自世界各地的美食,包括古巴、墨西哥、印度和西班牙。
上面的图提供了一些关于不同菜肴关系的有趣的深层分析。我们可以观察到散点图的中心值往往倾向于类似的美食菜谱类型。例如,图2中的A组包括中国、泰国和亚洲料理,它们都可以归类为亚洲食品。B组由日本和夏威夷料理组成。这两种菜系都非常强调鱼,所以它们被紧密地联系在一起是有道理的。C组完全由欧洲菜组成,如瑞典菜、法国菜和德国菜,不远处的D组主要由北美菜组成。这些包括南美美食,烤肉和传统的美式料理。最后,E组是一个混合了来自世界各地的不同菜系的集合。这包括古巴,墨西哥,印度,西班牙和西南部美食。当我想到这些菜系时,我想到的是大和大胆的味道,所以这些菜系会被紧密地组合在一起,也是完全合理的。
读者可能会问的一个问题是,哪些特性(成分)与第一和第二主成分的联系最为紧密? 这可以在下图中看到。
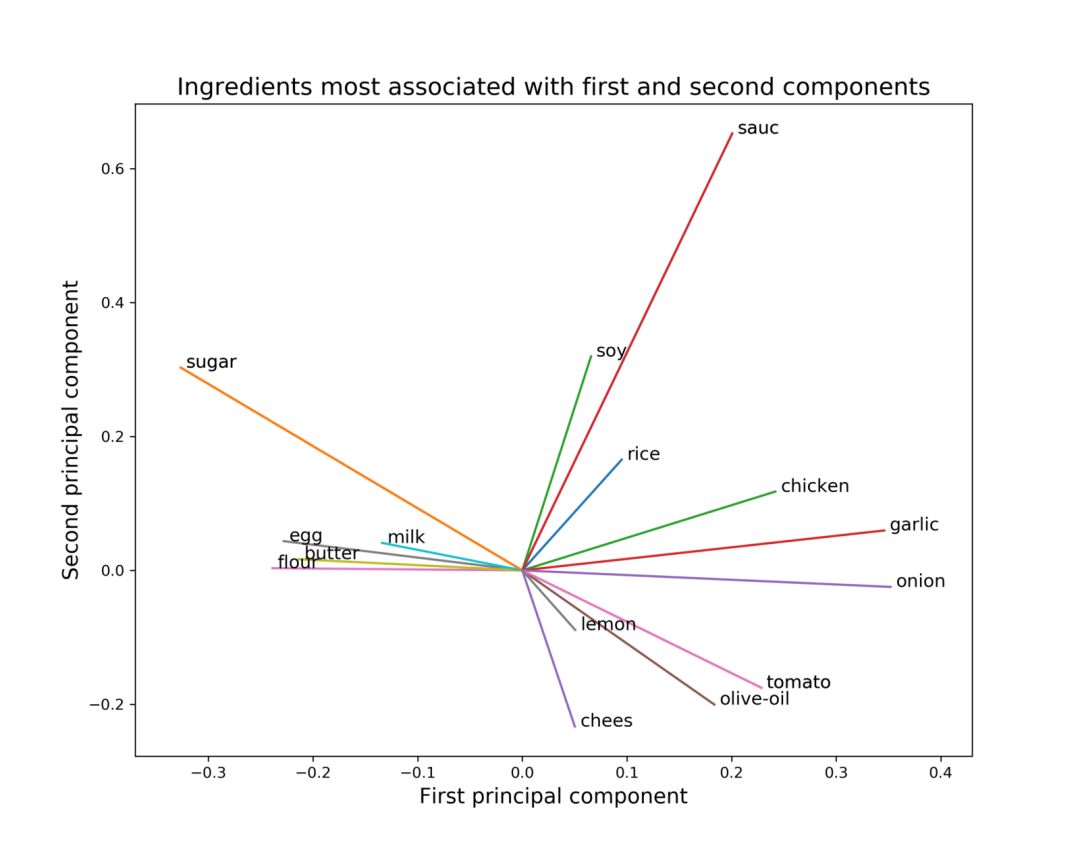
显示了与第一和第二主要成分联系最紧密的成分
这个图提供另两个主成分中每一个主要特征的直观表示。鸡肉、大蒜、洋葱和西红柿等原料在成分一的正方向上有很强的联系。这些口味与西班牙或印度的菜肴有着紧密的联系。另一方面,鸡蛋、黄油、面粉、牛奶和糖在成分一的反方向上有很强的联系。这些都是法国或英国菜肴中常见的配料。同样,大豆、酱油和大米与第二主成分的正方向有着很强的联系。这些食材在亚洲菜系中很常见。最后,芝士、柠檬、橄榄油和番茄与成分二的负极有很强的联系。这些味道在意大利和希腊菜中很常见。这个图有助于解读前一个图,即为什么在沿着第一个和第二个主成分绘制散点图时,某些菜系会聚集在特定的区域。
最后,我还运行了一个主题生成模型来进行主题建模。我很好奇是否能够根据不同的菜肴来区分不同的食材。我指定主题的数量为 25,因为在我的数据集中共有 25 种不同的菜系。然而,主题生成模型给出的的结果有点混乱。在某些情况下,LDA 给出的主题是特定的菜系,如意大利菜或泰国菜。然而,有些主题却是不同种类的菜品,如甜点、酱汁,甚至是鸡尾酒。虽然这个结果不是我想要的,但回想起来,它还是很有意义的。LDA 是一种机器学习技术,可以识别经常出现在一起的单词组。所以,在超过12000个食谱的语料库中,菜品的类型(如甜点、汤、沙拉或酱料)可能比菜系的类型会有更强的关联。

主题生成模型 LDA 给出的结果
▌实践感悟
在探索食谱数据集的过程中我得到了很多乐趣,因为我喜欢将我对食物的热爱与我学习的新技能结合起来。另外我们还可以根据这种分析提供一个优秀的商业案例,这些信息可以用来为Yummly平台的用户提供美食建议。例如,一个非常喜欢烧烤的人可能也会很喜欢葡萄牙美食,因为这两种不同的美食的第一和第二主成分的散点图中心重叠。类似这样的关系如果没有对这些数据进行深入的探索是无法得知的。
但是在这里我还要另外声明一件重要的事,在这个项目研究中使用的数据也是存在一定缺点的。例如,Yummly基本上是一个汇集了许多其它菜谱网站或博客的英语网站。因此,这些食谱中很多可能是美国人对其他美食类型的看法。我敢肯定我的意大利朋友们会说,把鸡肉和香蒜酱混合在一起的美食“不是意大利菜!”但Yummly还是把这道菜谱标记为了意大利菜。解决这个问题的一个很好的办法是利用他们的母语食谱,使用一些高级的翻译算法将它们翻译成英语。然而,由于某些成分可能对特定的地理位置具有特定性,也可能也会导致一些其他的问题。例如,某些配料在英语中可能没有对应的名称(例如,意大利熏火腿、帕尔玛干酪),因此这些配料将永远与意大利美食联系在一起,这可能会减少不同菜系之间的相似点,但我仍然认为这是值得探索的。
-
深非监督学习-Hierarchical clustering 层次聚类python的实现2020-04-28 0
-
如何用卷积神经网络方法去解决机器监督学习下面的分类问题?2021-06-16 0
-
基于半监督学习的跌倒检测系统设计_李仲年2017-03-19 767
-
基于半监督学习框架的识别算法2018-01-21 725
-
你想要的机器学习课程笔记在这:主要讨论监督学习和无监督学习2018-12-03 422
-
如何用Python进行无监督学习2019-01-21 3967
-
机器学习算法中有监督和无监督学习的区别2020-07-07 5380
-
最基础的半监督学习2020-11-02 2388
-
半监督学习最基础的3个概念2020-11-02 2685
-
为什么半监督学习是机器学习的未来?2020-11-27 3653
-
半监督学习:比监督学习做的更好2020-12-08 1146
-
基于人工智能的自监督学习详解2021-03-30 5651
-
机器学习中的无监督学习应用在哪些领域2022-01-20 4600
-
自监督学习的一些思考2022-01-26 290
-
半监督学习代码库存在的问题与挑战2022-10-18 997
全部0条评论

快来发表一下你的评论吧 !
