

Softmax如何把CNN的输出转变成概率?交叉熵如何为优化过程提供度量?
电子说
描述
如果你稍微了解一点深度学习的知识或者看过深度学习的在线课程,你就一定知道最基础的多分类问题。当中,老师一定会告诉你在全连接层后面应该加上 Softmax 函数,如果正常情况下(不正常情况指的是类别超级多的时候)用交叉熵函数作为损失函数,你就一定可以得到一个让你基本满意的结果。而且,现在很多开源的深度学习框架,直接就把各种损失函数写好了(甚至在 Pytorch中 CrossEntropyLoss 已经把 Softmax函数集合进去了),你根本不用操心怎么去实现他们,但是你真的理解为什么要这么做吗?这篇小文就将告诉你:Softmax 是如何把 CNN 的输出转变成概率,以及交叉熵是如何为优化过程提供度量。为了让读者能够深入理解,我们将会用 Python 一一实现他们。
▌Softmax函数
Softmax 函数接收一个 这N维向量作为输入,然后把每一维的值转换成(0,1)之间的一个实数,它的公式如下面所示:
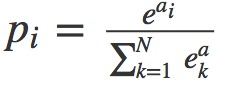
正如它的名字一样,Softmax 函数是一个“软”的最大值函数,它不是直接取输出的最大值那一类作为分类结果,同时也会考虑到其它相对来说较小的一类的输出。
说白了,Softmax 可以将全连接层的输出映射成一个概率的分布,我们训练的目标就是让属于第k类的样本经过 Softmax 以后,第 k 类的概率越大越好。这就使得分类问题能更好的用统计学方法去解释了。
使用 Python,我们可以这么去实现 Softmax 函数:

我们需要注意的是,在 numpy 中浮点类型是有数值上的限制的,对于float64,它的上限是 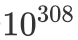 。对于指数函数来说,这个限制很容易就会被打破,如果这种情况发生了 python 便会返回 nan。
。对于指数函数来说,这个限制很容易就会被打破,如果这种情况发生了 python 便会返回 nan。
为了让 Softmax 函数在数值计算层面更加稳定,避免它的输出出现 nan这种情况,一个很简单的方法就是对输入向量做一步归一化操作,仅仅需要在分子和分母上同乘一个常数 C,如下面的式子所示
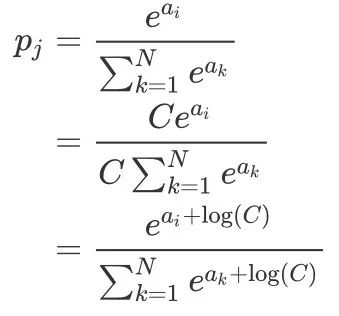
理论上来说,我们可以选择任意一个值作为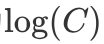 ,但是一般我们会选择
,但是一般我们会选择
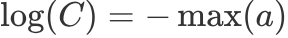 通过这种方法就使得原本非常大的指数结果变成0,避免出现 nan的情况。
通过这种方法就使得原本非常大的指数结果变成0,避免出现 nan的情况。
同样使用 Python,改进以后的 Softmax 函数可以这样写:

▌Softmax 函数的导数推倒过程
通过上文我们了解到,Softmax 函数可以将样本的输出转变成概率密度函数,由于这一很好的特性,我们就可以把它加装在神经网络的最后一层,随着迭代过程的不断深入,它最理想的输出就是样本类别的 One-hot 表示形式。进一步我们来了解一下如何去计算 Softmax 函数的梯度(虽然有了深度学习框架这些都不需要你去一步步推导,但为了将来能设计出新的层,理解反向传播的原理还是很重要的),对 Softmax 的参数求导:
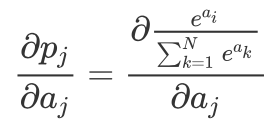
根据商的求导法则,对于 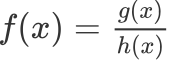 其导数为
其导数为
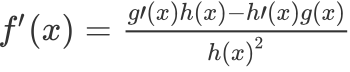
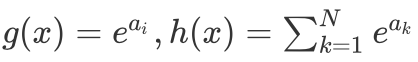
。在 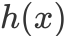 中,
中,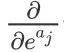 一直都是
一直都是 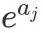 但是在
但是在 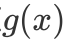 中,当且仅当
中,当且仅当 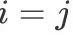 的时候,
的时候,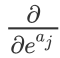 才为
才为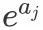 。具体的过程,我们看一下下面的步骤:
。具体的过程,我们看一下下面的步骤:
如果 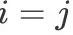
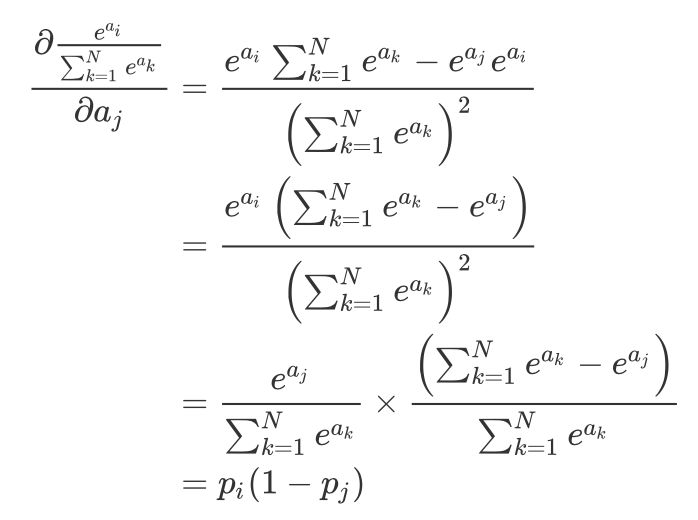
如果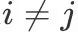
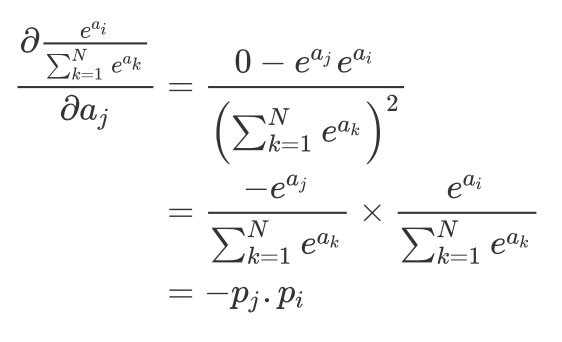
所以 Softmax 函数的导数如下面所示:
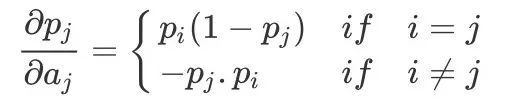
▌交叉熵损失函数
下面我们来看一下对模型优化真正起到作用的损失函数——交叉熵损失函数。交叉熵函数体现了模型输出的概率分布和真实样本的概率分布的相似程度。它的定义式就是这样:
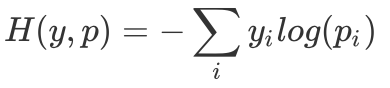
在分类问题中,交叉熵函数已经大范围的代替了均方误差函数。也就是说,在输出为概率分布的情况下,就可以使用交叉熵函数作为理想与现实的度量。这也就是为什么它可以作为有 Softmax 函数激活的神经网络的损失函数。
我们来看一下,在 Python 中是如何实现交叉熵函数的:

▌交叉熵损失函数的求导过程
就像我们之前所说的,Softmax 函数和交叉熵损失函数是一对好兄弟,我们用上之前推导 Softmax 函数导数的结论,配合求导交叉熵函数的导数:
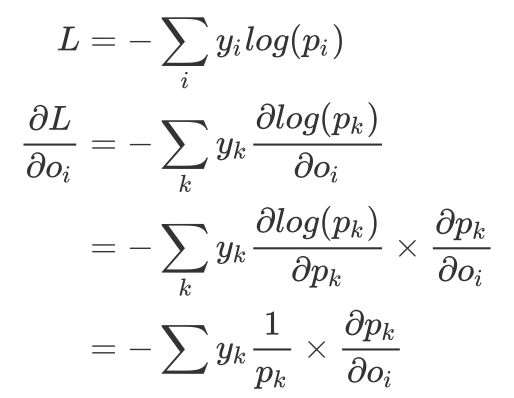
加上 Softmax 函数的导数:
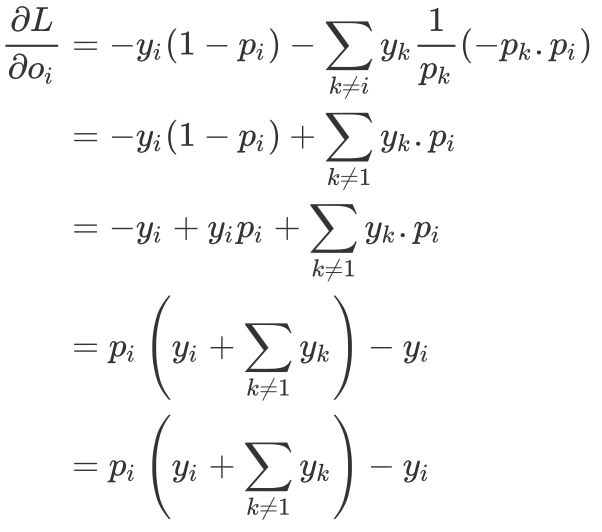
y 代表标签的 One-hot 编码,因此 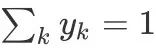
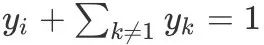 因此我们就可以得到:
因此我们就可以得到:
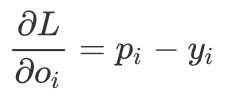
可以看到,这个结果真的太简单了,不得不佩服发明它的大神们!最后,我们把它转换成代码:

▌小结
需要注意的是,正如我之前提到过的,在许多开源的深度学习框架中,Softmax 函数被集成到所谓的 CrossEntropyLoss 函数中。比如 Pytorch 的说明文档,就明确地告诉读者 CrossEntropyLoss 这个损失函数是 Log-Softmax 函数和负对数似然函数(NLLoss)的组合,也就是说当你使用它的时候,没有必要再在全连接层后面加入 Softmax 函数。还有许多文章中会提到 SoftmaxLoss,其实它就是 Softmax 函数和交叉熵函数的组合,跟我们说的 CrossEntropyLoss 函数是一个意思,这点需要读者自行分辨即可。
-
在Quartus II中能否把电路图输入转变成Verilog语句2013-11-27 0
-
代码:利用STM32将一串ASCII码转变成周期固定占空比不同PWM波2014-03-17 0
-
TF之CNN:CNN实现mnist数据集预测2018-12-19 0
-
什么是交叉熵?2019-03-21 0
-
交叉熵的作用原理2019-06-03 0
-
交流电变成直流电的转变过程2021-09-17 0
-
如何将开关的开/断状态转变成Arduino能够读取的高/低电平2022-01-17 0
-
模拟输入信号转变成数字比特流的过程2022-11-16 0
-
光纤传输是把电信号转变成光信号传输的吗?2023-05-16 0
-
自己写的c代码怎么转变成sigmastudio识别的图像语言?2023-11-30 0
-
安迅士网络喇叭转变成公共广播系统 无需使用中央电子设备2018-01-22 1199
-
使用Softmax的信息来教学 —— 知识蒸馏2020-10-10 1927
-
基于CNN与约束概率矩阵分解的推荐算法2021-06-17 529
-
lm317能把不稳定的输出电压转变成稳定的电压吗?2023-10-26 422
全部0条评论

快来发表一下你的评论吧 !
