

一种具有混合精度的高度可扩展的深度学习训练系统
电子说
描述
编者按:昨天,腾讯和香港浸会大学的研究人员在arxiv上发表了一篇文章,介绍了一种具有混合精度的高度可扩展的深度学习训练系统。或许是觉得这个名字不够吸引人,他们又在后面加了一个颇具标题党意味的后缀——“4分钟训练ImageNet”。那么这样的措辞是否夸大其词了呢?让我们来读读他们的论文。

现状
现如今,随着数据集和大型深度神经网络规模不断扩大,研究人员训练模型使用的时间也在不断延长,短则几天,长则几周,但过长的训练时间会给研发进度带来阻碍。由于计算资源有限,针对这个问题,现在一种常见解决方案是使用分布式同步随机梯度下降(SGD),它可以跨硬件作业,前提是必须给每个GPU分配合理的样本数量。
虽然这种做法可以利用系统的总吞吐量和较少的模型更新来加速训练,但它也存在两个不可忽视的问题:
较大的mini-batch由于存在泛化误差,会导致较低的测试精度:
如果增加mini-batch里的样本个数,我们确实可以通过计算平均值来减少梯度变化,从而提供更准确的梯度估计,此时模型采用的步长更大,优化算法速度也更快。但正如ImageNet training in minutes这篇论文所论证的,一旦mini-batch的大小增加到64K,ResNet-50在测试集上的准确率会从75.4%下降到73.2%,这达不到基线模型的精度要求。
当使用大型GPU集群时,训练速度并不会随着GPU数量的增加而呈线性上升趋势,尤其是对于计算通信比较高的模型:
训练模型时,分布式训练系统会为每个GPU分配训练任务,然后在每个训练步之间插入一个梯度聚合步骤,GPU数量越多,这个梯度聚合步就越容易成为系统瓶颈。假设GPU数量N固定,如果要提升系统总吞吐量T,我们就要同时提高单个GPU的吞吐量S和它的缩放效率e,但这两者提升需要额外的算力资源,这就和N固定有矛盾。
实验结果
在介绍研究成果前,我们先来看看最引人注意的“4分钟训练ImageNet”。
根据论文实验部分的内容,研究人员选取的模型是AlexNet和ResNet-50,它们各自代表一种典型的CNN。AlexNet的参数数量是ResNet-50的2.5倍,而ResNet-50的计算却是前者的5.6倍。因此它们的瓶颈分别是通信和计算,这正代表上节提出的两个问题。
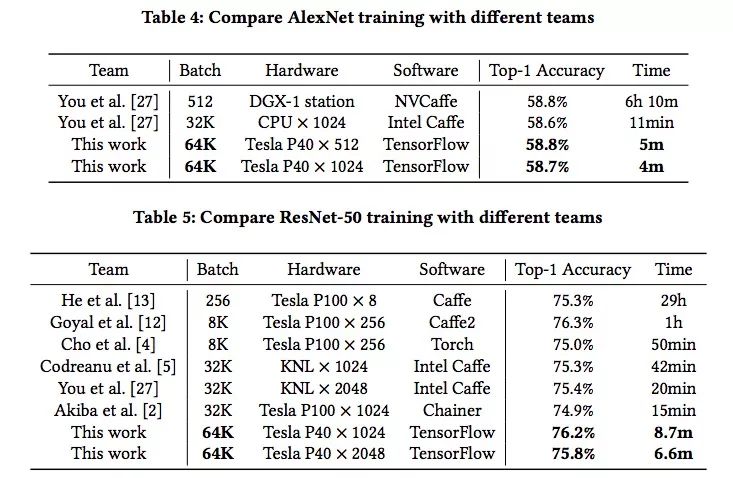
上表是两个模型的训练结果和对比,可以发现,在ImageNet数据集上,研究人员用4分钟训练好AlexNet,又用6.6分钟训练好ResNet-50,batch size非常大,但精度却和其他模型没什么区别。从数据角度看,这确实是个历史性的突破。
而根据腾讯机智团队自己的介绍,在这之前,业界最好的水平来自:日本Perferred Network公司Chainer团队,他们用15分钟就训练好了ResNet-50;UC Berkely等高校的团队,他们用11分钟训练好AlexNet。相较之下,腾讯和香港浸会大学的这个成果创造了AI训练的世界新纪录。
但显然,他们在写论文标题的时候也漏掉了重要内容,就是这个速度背后是2000多块GPU,相信这个真相会让一些研究人员兴奋,也会让大批学者和实验室感到内心拔凉。
研究成果概述
关于论文技术的详细细节,腾讯技术工程官方已经有长文分析,所以这里只根据论文内容的一点简介(才不说是写完才发现人家已经发了呢)。
这篇论文为为密集GPU集群构建了一个高度可扩展的深度学习训练系统,它很好地解决了上述两个问题,下图是它结构概览:
从图中我们可以看到,这个系统可以大致分为三个模块:输入管道模块、训练模块和通信模块。
输入管道负责在当前步骤完成之前就为下一步提供数据,它使用pipelining来最小化CPU和GPU的闲置时间。
训练模块包括模型构建和变量管理。在这个模块中,研究人员结合了各类优化方法,如使用混合精度训练前向/反向传播和用LARS更新模型。
通信模块使用tensor fusion和论文提出的混合Allreduce,根据张量大小和GPU集群大小优化缩放效率。
1. 提出了一种混合精度训练方法,可以显着提高单个GPU的训练吞吐量而不会降低精度。
之前,Micikevicius等人已经在研究中提出过在训练阶段使用半精度(FP16)有助于降低内存压力并增加计算吞吐量的想法,前者可以通过把相同数量的值储存进更少的bit来实现,后者则可以降低数学精度,让处理器提供更高的吞吐量。
而Yang You等人提出了一种为分布式培训提供更大mini-batch的算法——LARS(自适应速率缩放),它会为每一层引入局部学习率,也就是用系数η加权的L2正则化权重和梯度权重的比率,能大幅度提高大batch size场景下的训练精度。
这两个成果非常互补,但它们不能直接结合使用,因为会导致梯度消失。为了融合两种思想,研究人员做出的改进是用LARS进行混合精确训练,如下图所示,当进行前向传播和反向传播时,系统先把参数和数据转成半精度浮点数,然后再做训练,而训练权重和梯度时,参数和数据则是单精度浮点数。
2. 提出了一种针对超大型mini-batch(最大64k)的优化方法,可以在ImageNet数据集上训练CNN模型而不会降低精度。
模型架构改进是提高模型性能的一种常见手段,在论文中,研究人员从以下两个方面改进了模型架构:1)消除偏差和batch normalization的权重衰减;2)为AlexNet增加了一个batch normalization层。
除了这一点,深度学习中耗时占比较重的还有超参数调整。为了优化这一过程,研究人员的思路是:
参数步长由粗到细:调优参数值先以较大步长进行划分,可以减少参数组合数量,当确定大的最优范围之后再逐渐细化调整。
低精度调参:分析相关数据,放大低精度表示边缘数值,保证参数的有效性。
初始化数据的调参:根据输入输出通道数的范围来初始化初始值,一般以输入通道数较为常见;对于全连接网络层则采用高斯分布即可;对于shortcut的batch norm,参数gamma初始化为零(也可以先训练一个浅层网络,再通过参数递进初始化深层网络参数)。
3. 提出了一种高度优化的allreduce算法,使用这种算法后,相比NCCL计算框架,AlexNet和ResNet-50在包含1024个Tesla P40 GPU的集群上的训练速度分别提高了3倍和11倍。
在张量足够多的情况下,Ring Allreduce可以最大化利用网络,但工作效率和速度都不如张量少的情况。针对这种现象,研究人员利用分层同步和梯度分段融合优化Ring Allreduce
分层同步与Ring Allreduce有机结合:对集群内GPU节点进行分组,减少GPU数量对整体训练用时的影响。
梯度融合,多次梯度传输合并为一次:根据具体模型设置合适的Tensor size阈值,将多次梯度传输合并为一次,同时超过阈值大小的Tensor不再参与融合;这样可以防止Tensor过度碎片化,从而提升了带宽利用率,降低了传输耗时。
GDR技术加速Ring Allreduce:在前述方案的基础上,将GDR技术应用于跨节点Ring,这减少了主存和显存之间的Copy操作,同时为GPU执行规约计算提供了便利。
这三大成果的直接效果是在不降低分类准确率的同时,把AlexNet和ResNet-50训练时所用的mini-batch size扩大至64K。同时,通过优化All-reduce算法,并让系统支持半精度训练,研究人员最后构建了一个高吞吐量分布式深度学习训练系统,可以在GPU数量N不变的情况下,提高单个GPU性能S和缩放效率e。
-
Nanopi深度学习之路(1)深度学习框架分析2018-06-04 4241
-
【HarmonyOS HiSpark AI Camera】基于深度学习的目标检测系统设计2020-09-25 1043
-
labview深度学习检测药品两类缺陷2021-05-27 20372
-
探索一种降低ViT模型训练成本的方法2022-11-24 1411
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2024
-
基于一种航资系统综合训练装置设计2017-11-01 592
-
一种高精度自然人机交互认知训练系统2017-11-10 938
-
一种新的目标分类特征深度学习模型2018-03-20 1182
-
混合精度训练的优势!将自动混合精度用于主流深度学习框架2019-04-03 8068
-
谷歌深度学习如何处理人类语言?2021-03-01 1692
-
一种基于深度学习的地下浅层震源定位方法2021-03-22 898
-
超详细配置教程:用Windows电脑训练深度学习模型2022-11-08 2262
-
深度解析可扩展且保密的深度学习2023-06-28 515
-
深度学习框架区分训练还是推理吗2023-08-17 2156
-
深度学习模型训练过程详解2024-07-01 3885
全部0条评论

快来发表一下你的评论吧 !
