

Google产品分析Zlatan Kremonic分享了参加Kaggle竞赛的经验
电子说
描述
编者按:Google产品分析Zlatan Kremonic分享了参加Kaggle竞赛的经验。
问题
Kaggle房价竞赛要求参赛者预测2006年至2010年美国爱荷华州埃姆斯市的房价。数据集中包含79个变量,包括许多房屋属性。你可以在Kaggle网站上了解更多细节:https://www.kaggle.com/c/house-prices-advanced-regression-techniques
方法
由于我们的目标变量是连续值(售价),因此这是一个典型的回归问题,让人联想起波斯顿房价数据集。评估标准为预测和实际售价的接近程度(预测值的对数与观测到的售价的对数的均方根误差)。
数据集中包括大量变量,其中许多是类别变量,因此特征选取是这一问题的关键部分。特征选取的两种常用方法:
直接使用scikit-learn中的SelectKBest方法。
LASSO回归。
我在分析中尝试了这两种方法,发现LASSO回归的结果要好一些。
另外,我们将使用XGBoost,并在结果中融合LASSO的输出,以提升模型的精确度。我们的最终结果不错,位于排行榜的前10%(撰写本文时)。
探索性数据分析
因为变量很多,为了节约篇幅,我不会详细演示所有探索性数据分析(我在文末列出了GitHub仓库的链接,如果你对探索性数据分析的细节感兴趣,可以查看其中的EDA.ipynb)。相反,我将直接给出我的主要观察,这些观察给特征工程提供了信息。
我们有大量的类别属性,需要进行独热编码。
一些数值列有null值,需要填充。
许多数值列的分布比较扭曲,需要处理。
如前所述,为了节约篇幅,这里仅仅给出导入库、加载数据的代码,不包括探索性数据分析部分的代码。
import os
import pandas as pd
import numpy as np
from scipy.stats import skew
from sklearn.model_selection importGridSearchCV
from sklearn.linear_model importLasso
from sklearn.metrics import mean_squared_error
from xgboost.sklearn importXGBClassifier
import xgboost as xgb
import matplotlib.pyplot as plt
%matplotlib inline
train = pd.read_csv(os.path.join('data', 'train.csv'))
test = pd.read_csv(os.path.join('data', 'test.csv'))
y = train.iloc[:, -1]
train = train.iloc[:, 1:-1]
test = test.iloc[:, 1:]
submission = test.iloc[:, 0]
特征工程
首先,我们将MSSubClass变量(表示建筑分类编码)从数值转为字符串,因为这些编码只是无序的类别。
def mssubclass(train, test, cols=['MSSubClass']):
for i in (train, test):
for z in cols:
i[z] = i[z].apply(lambda x: str(x))
return train, test
接着,我们将对所有数值特征取对数,包括因变量。由于数值特征包含很多零值,我们使用log1p,在取对数前先加一。
def log(train, test, y):
numeric_feats = train.dtypes[train.dtypes != "object"].index
for i in (train, test):
i[numeric_feats] = np.log1p(i[numeric_feats])
y = np.log1p(y)
return train, test, y
我们将用每列的均值填充null值:
def impute_mean(train, test):
for i in (train, test):
for s in [k for k in i.dtypes[i.dtypes != "object"].index if sum(pd.isnull(i[k])>0)]:
i[s] = i[s].fillna(i[s].mean())
return train, test
独热编码时,同样需要填充null值:
def dummies(train, test):
columns = [i for i in train.columns if type(train[i].iloc[1]) == str or type(train[i].iloc[1]) == float]
for column in columns:
train[column].fillna('NULL', inplace = True)
good_cols = [column+'_'+i for i in train[column].unique()[1:] if i in test[column].unique()]
train = pd.concat((train, pd.get_dummies(train[column], prefix = column)[good_cols]), axis = 1)
test = pd.concat((test, pd.get_dummies(test[column], prefix = column)[good_cols]), axis = 1)
del train[column]
del test[column]
return train, test
整个特征工程流程:
train, test = mssubclass(train, test)
train, test, y = log(train, test, y)
train, test = lotfrontage(train, test)
train, test = garageyrblt(train, test)
train, test = impute_mean(train, test)
train, test = dummies(train, test)
LASSO回归
LASSO回归同时起到了正则化和特征选取的作用,可以改善模型的预测效果。就我们的情况而言,LASSO回归是完美的算法,因为它有助于降低特征数并缓解过拟合。
LASSO回归中需要调节的超参数主要是正则化因子alpha。我们使用GridSearchCV(网格搜索交叉验证)寻找alpha的最优值。
alpha_ridge = [1e-5, 1e-4, 1e-3, 1e-2, 1, 5, 10, 20]
coeffs = {}
for alpha in alpha_ridge:
r = Lasso(alpha=alpha, normalize=True, max_iter=1000000)
r = r.fit(train, y)
grid_search = GridSearchCV(Lasso(alpha=alpha, normalize=True), scoring='neg_mean_squared_error',
param_grid={'alpha': alpha_ridge}, cv=10, n_jobs=-1)
grid_search.fit(train, y)
最终我们得到alpha的最佳值0.0001。为了更直观地理解alpha的影响,我们可以画出所有alpha值的均方根误差:
alpha = alpha_ridge
rmse = list(np.sqrt(-grid_search.cv_results_['mean_test_score']))
plt.figure(figsize=(6,5))
lasso_cv = pd.Series(rmse, index = alpha)
lasso_cv.plot(title = "Validation - LASSO", logx=True)
plt.xlabel("alpha")
plt.ylabel("rmse")
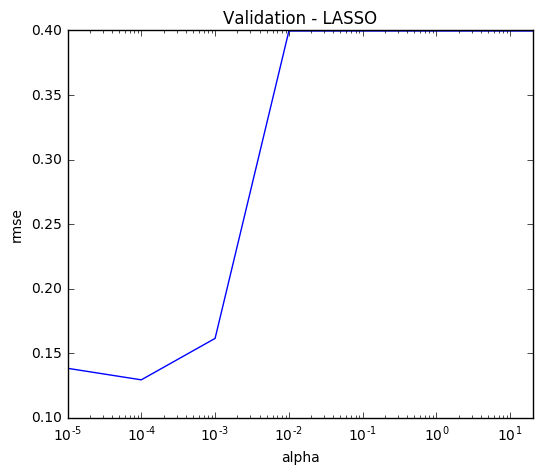
现在用模型拟合训练数据:
lasso = Lasso(alpha=.0001, normalize=True, max_iter=1e6)
lasso = lasso.fit(train, y)
我们的模型有多少列?
coef = pd.Series(lasso.coef_, index = train.columns)
print("Lasso选中了" + str(sum(coef != 0)) + "个变量,并移除了其他" + str(sum(coef == 0)) + "个变量")
Lasso选中了103个变量,并移除了其他142个变量
此外,我们可以看到,根据我们的模型,房龄、面积、房屋状况是最重要的变量。这很符合直觉——在创建模型时检查模型是否符合常理总是不错的。
imp_coef = pd.concat([coef.sort_values().head(10),
coef.sort_values().tail(10)])
plt.rcParams['figure.figsize'] = (5.0, 5.0)
imp_coef.plot(kind = "barh")
plt.title("Coefficients in the Lasso Model")
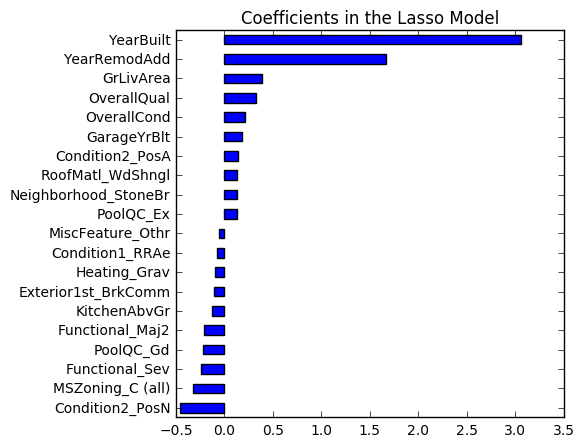
用LASSO模型预测测试数据,我们得到的均方根误差为0.1209,这已经足以在排行榜上取得前25%的名次了。
XGBoost模型
由于XGBoost在数据科学竞赛中的强力表现,从2016年起,这一算法变得家喻户晓了。这一算法的挑战之一是处理大数据集时,调整超参数耗时很久。然而,因为我们的数据集包含不到1500项观测,所以我觉得这是一个尝试XGBoost的好机会。为了节约篇幅,我这里不会披露超参数调整的细节。我主要使用的方法是每次交叉验证一到两个参数,以免给我的机器太大的负担,同时在调整会话的间隔重新计算n_estimators的最优值。
下面是我实现的最终模型。它的得分是0.12278,事实上这比LASSO模型要差。
regr = xgb.XGBRegressor(
colsample_bytree=0.3,
gamma=0.0,
learning_rate=0.01,
max_depth=4,
min_child_weight=1.5,
n_estimators=1668,
reg_alpha=1,
reg_lambda=0.6,
subsample=0.2,
seed=42,
silent=1)
regr.fit(train, y)
y_pred_xgb = regr.predict(test)
融合模型结果
最后我们需要组合两个模型的结果。我对两个模型的预测取了加权平均。最终的得分是0.11765,明显比两个模型单独预测的结果要好。这确认了集成学习的首要原则,假定误差率互不相关,集成的误差率低于单个模型。
predictions = np.expm1(.6*lasso_pred + .4*y_pred_xgb)
之前在特征工程时使用了log1p,所以现在用expm1还原原数值。注意这里给LASSO更大的权重(0.6),并不是因为在测试数据上LASSO的表现优于XGBoost,而是因为在训练数据上LASSO的表现优于XGBoost(因为建模的时候不能“偷看”测试数据)。
结语
这项竞赛是一个练习标准回归技术的好机会。我只进行了最少的特征工程就取得了前10%的排名。
除了上面的模型,我也尝试了SelectKBest(搭配Pipeline和网格搜索),将列数缩减至138,并得到了0.13215的分数。然而,将其与其他模型融合时,效果不佳。后来我又试了随机森林回归,得分是0.14377,这不算差,但要在我们的集成中加入这个模型,这个分数显然还不够高。
-
致正在参加电子竞赛的你们2015-07-28 0
-
要参加“电子产品设计与制作”比赛了,谁有经验?求助。2012-03-29 0
-
Altera SOPC专题竞赛-经验总结2012-08-10 0
-
我准备参加和泰杯单片机应用竞赛,无经验,请求高人注解2012-12-10 0
-
有指导学生参加技能竞赛的教师吗?2013-03-04 0
-
全国大学生电子设计竞赛2013-07-09 0
-
参加ti电子竞赛2014-06-29 0
-
kaggle住宅价格预测2019-08-13 0
-
kaggle泰坦尼克生存预测实施步骤2019-09-05 0
-
全国电子设计竞赛_经验之谈2016-05-04 472
-
Kaggle机器学习/数据科学现状调查2018-06-29 9631
-
不用写一行就带就可以参加 Kaggle,这个真香!2019-07-18 2787
-
腾讯宣布其人工智能球队获首届谷歌足球Kaggle竞赛冠军2020-12-30 1715
-
如何从13个Kaggle比赛中挑选出的最好的Kaggle kernel2021-06-27 1840
-
18年参加合泰杯单片机竞赛时候的程序2021-12-02 424
全部0条评论

快来发表一下你的评论吧 !
