

传统的音频降噪方式!通过AI识别场景,智能降噪
电子说
描述
锤子科技在15日坚果TNT工作站发布之后,表情包们集体炸了。
嘘,你不要讲话,吵到我用TNT了
这个表情包吐槽的是9999元起的TNT工作站的工作场景,因为大部分操作需要用到触控+语音识别功能,在背景嘈杂的办公室,你很难让语音清晰识别到你的声音,在各种干扰下你的操作精度将会大打折扣。所以网上还有个段子表示,如果要用TNT工作站来设计,老板必须给每个设计师安排单独的隔音办公室。其实这种情况在目前普遍搭载人工语音智能的设备如手机、音箱中很难普遍,只要稍微有人声干预就会让你的siri识别率大跌。
不过噪音问题其实比你想象中的容易解决,对于罗永浩和锤子科技来说,或许欠缺的只是一颗小小的降噪芯片。
传统的音频降噪方式
目前智能手机中对于环境噪音的处理主要有两种方式:第一种是通过多MIC实现降噪功能。这种方式需要配备降噪MIC,对于用户的使用手势要求很高。如果降噪MIC刚好压住用户的脸部,或者在耳机模式下都无法获得降噪效果,在使用免提模式的时候也会有影响。
第二种是通过在终端设备内置场景降噪的软件,通过算法来实现降噪。这对于终端计算能力有很高要求,一方面对于环境噪声的样本数量有限,另一方面,噪声样本越多,终端的判断时间就会越长,最终影响用户体验。毕竟用户希望对话是能够迅速反应的。
这两种传统的降噪方式都具有各种缺陷,在具体的降噪效果上也是差强人意。
通过AI识别场景,智能降噪
更好的方式是采用独立的降噪芯片来进行降噪。来自***的意腾科技通过一颗搭载AI算法的降噪芯片来实现降噪功能。这种方式的好处是不再需要多个MIC来处理,只需要单MIC就能保证通话模式中实现清晰的语音。此外,这种方式也不需要对噪声样本进行搜索匹配。
这颗降噪芯片其中的核心是一颗专为语音降噪设计的AI处理器,通过3层深度学习网络(DNN网络)实现对原始声音的处理输出,其中每层网络拥有1028个节点。此外,这颗AI处理器的运算能力可以达到1012 ops/W,可以针对特别压缩的声音信号实现计算处理。
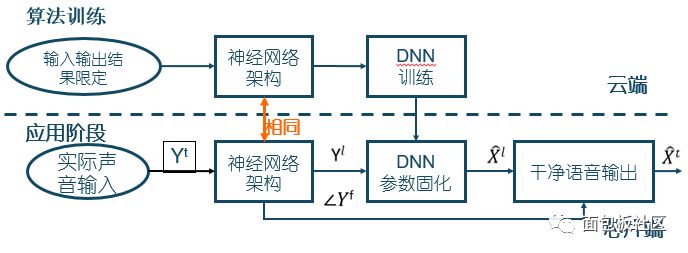
通过这颗降噪芯片,之所以不需要对噪声样本进行搜索匹配。主要是因为这颗AI处理器对超过4亿个语音资料样本(包括2亿外文语音样本)进行了机器学习,可通过DNN网络迅速自行找到每段音频最合适的模型和参数。可实现智能识别包括餐厅/集会场所、公交地铁火车站、风噪、音乐噪声等各个噪声场景。
降噪前后效果对比
通过智能场景识别实现的降噪功能有多牛逼?让我们来通过噪声处理前后的音频来实际对比一下:
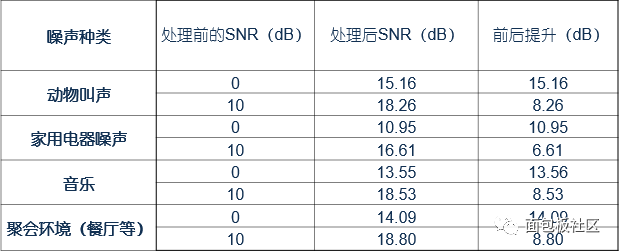
一般来说,业界都采用SNR(信噪比)来判断降噪功能,SNR是按照国际标准ISO 4969-2检测的单值降噪值。设备的信噪比越高表明它产生的杂音越少。从图表对比中可以看到,经过降噪处理后的SNR实现了大幅度的提升。
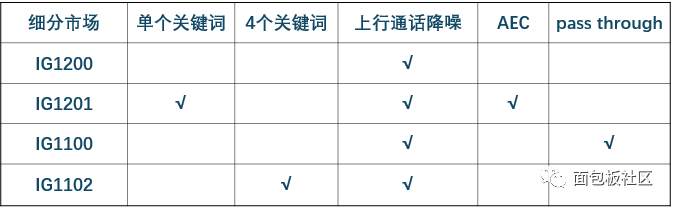
据了解,目前意腾科技的降噪音频芯片一共四个型号,分别对应IG200、IG1201、IG1100、IG1102。目前实现的主要功能还是通话降噪和近距离唤醒。此外,目前实现的本地存储的关键词达到4组,预计到Q3会升到10组,通过是支持立体声AEC以及beamforming功能。预计到Q4会推出带声纹识别功能的降噪芯片,这样的话你就再也不用担心下面这个段子的情况会发生了:
“我悄悄来到卖力工作的设计师小王身后,说一句全部删除,小王的心血付之东流。”
最后介绍一下这颗芯片的供应商意腾科技。这家公司的CEO从事半导体行业30年+,之前创立的耀鹏科技曾是三星手机供应商。主要研发团队从2013年开始就研究AI语音降噪算法,目前意腾科技也获得了MTK的投资。值得注意的是,目前高通是采用将AI降噪算法植入到SOC的方式来实现降噪,但这对于SOC的性能和功耗要求颇高,未来是否会采用单独的AI芯片来进行处理,还有待观察。
最后,笔者认为未来语音交互将会成为一种重要的交互手段,TNT的构想在技术的进步之下未必不能实现。让我们对产品创新保持一定的宽容和好奇心。
-
降噪耳机原理介绍2009-11-24 0
-
骨传导耳机与传统耳机对比详解2016-10-10 0
-
请问adau1452音频降噪处理支持浮点运算吗?2018-09-25 0
-
蓝牙耳机降噪知识2019-09-19 0
-
主动降噪蓝牙耳机怎么选?时下比较火爆的五款耳机产品2020-04-15 0
-
效果还不错的双麦降噪模块PI-36规格书2020-06-07 0
-
主动降噪(ANC),让你静心聆听声音2020-08-18 0
-
怎样去设计一个嵌入式AI数字音频系统2021-12-14 0
-
带波束成型的降噪消回音模块:A-68 双麦回音消除及远场拾音降噪模块2023-02-01 0
-
优异降噪的回音消除模块:A-47 双麦阵列回音消除及降噪模块 A-47说明书2023-02-01 0
-
启英泰伦通话降噪方案,采用深度学习降噪算法,让通话更清晰2023-08-22 0
-
魅族EP63NC无线降噪耳机正式降价该耳机内部搭载了智能降噪芯片2020-01-06 997
-
思必驰携手联想超级电脑,探索降噪之路2022-08-24 1415
-
OPPO Enco Free3真无线降噪耳机携TUV莱茵高性能降噪认证全球首发2023-03-26 411
-
览邦F9BudsPlus多模式降噪耳机评测:智能降噪,更清晰2023-04-24 544
全部0条评论

快来发表一下你的评论吧 !
