

基于乘法的运算来体现体征交叉的DNN网络结构
电子说
描述
1、原理
PNN,全称为Product-based Neural Network,认为在embedding输入到MLP之后学习的交叉特征表达并不充分,提出了一种product layer的思想,既基于乘法的运算来体现体征交叉的DNN网络结构,如下图:
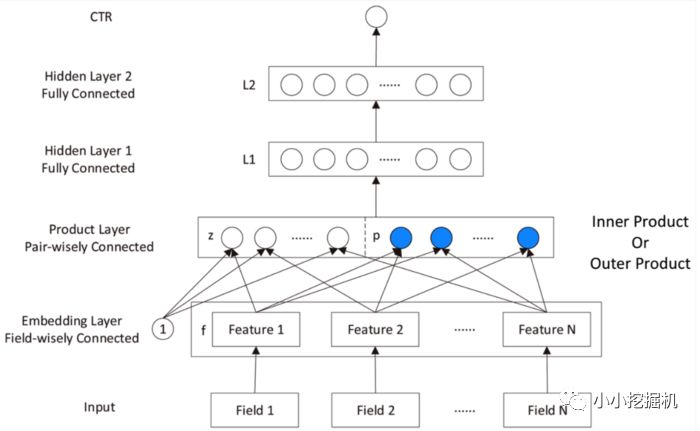
按照论文的思路,我们也从上往下来看这个网络结构:
输出层输出层很简单,将上一层的网络输出通过一个全链接层,经过sigmoid函数转换后映射到(0,1)的区间中,得到我们的点击率的预测值:
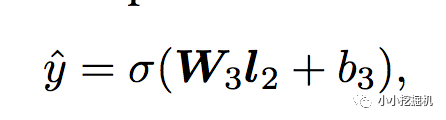
l2层根据l1层的输出,经一个全链接层 ,并使用relu进行激活,得到我们l2的输出结果:
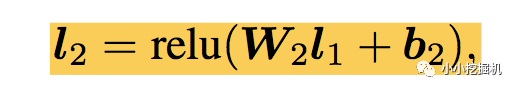
l1层l1层的输出由如下的公式计算:
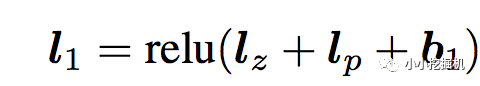
重点马上就要来了,我们可以看到在得到l1层输出时,我们输入了三部分,分别是lz,lp 和 b1,b1是我们的偏置项,这里可以先不管。lz和lp的计算就是PNN的精华所在了。我们慢慢道来
Product Layer
product思想来源于,在ctr预估中,认为特征之间的关系更多是一种and“且”的关系,而非add"加”的关系。例如,性别为男且喜欢游戏的人群,比起性别男和喜欢游戏的人群,前者的组合比后者更能体现特征交叉的意义。
product layer可以分成两个部分,一部分是线性部分lz,一部分是非线性部分lp。二者的形式如下:
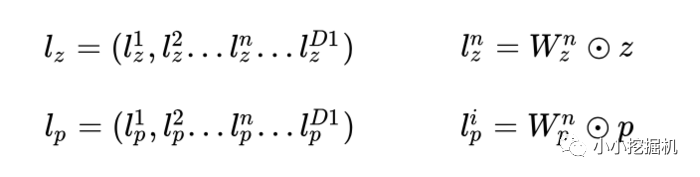
在这里,我们要使用到论文中所定义的一种运算方式,其实就是矩阵的点乘啦:
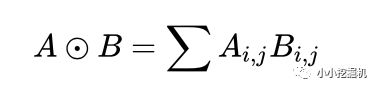
我们先继续介绍网络结构,有关Product Layer的更详细的介绍,我们在下一章中介绍。
Embedding Layer
Embedding Layer跟DeepFM中相同,将每一个field的特征转换成同样长度的向量,这里用f来表示。
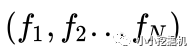
损失函数使用和逻辑回归同样的损失函数,如下:
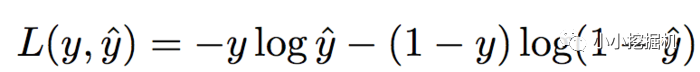
2、Product Layer详细介绍
前面提到了,product layer可以分成两个部分,一部分是线性部分lz,一部分是非线性部分lp。
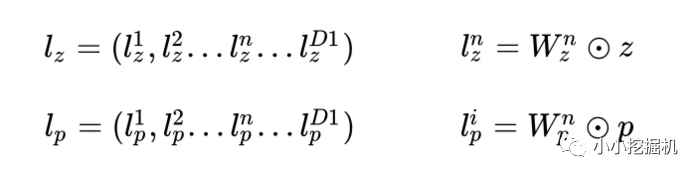
看上面的公式,我们首先需要知道z和p,这都是由我们的embedding层得到的,其中z是线性信号向量,因此我们直接用embedding层得到:
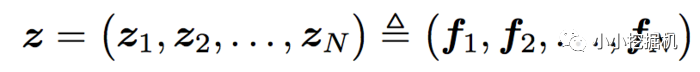
论文中使用的等号加一个三角形,其实就是相等的意思,你可以认为z就是embedding层的复制。
对于p来说,这里需要一个公式进行映射:
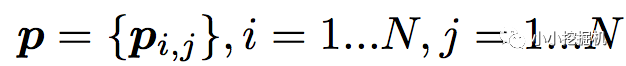
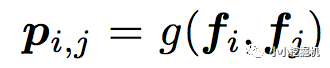
不同的g的选择使得我们有了两种PNN的计算方法,一种叫做Inner PNN,简称IPNN,一种叫做Outer PNN,简称OPNN。
接下来,我们分别来具体介绍这两种形式的PNN模型,由于涉及到复杂度的分析,所以我们这里先定义Embedding的大小为M,field的大小为N,而lz和lp的长度为D1。
2.1 IPNN
IPNN的示意图如下:
IPNN中p的计算方式如下,即使用内积来代表pij:
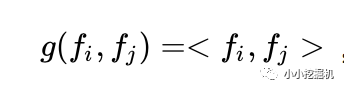
所以,pij其实是一个数,得到一个pij的时间复杂度为M,p的大小为N*N,因此计算得到p的时间复杂度为N*N*M。而再由p得到lp的时间复杂度是N*N*D1。因此 对于IPNN来说,总的时间复杂度为N*N(D1+M)。文章对这一结构进行了优化,可以看到,我们的p是一个对称矩阵,因此我们的权重也可以是一个对称矩阵,对称矩阵就可以进行如下的分解:
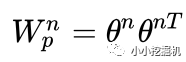
因此:
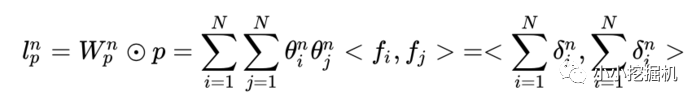
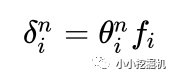
因此:
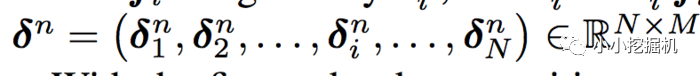
从而得到:
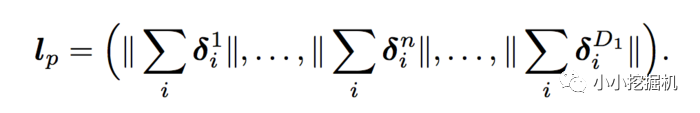
可以看到,我们的权重只需要D1 * N就可以了,时间复杂度也变为了D1*M*N。
2.2 OPNN
OPNN的示意图如下:
OPNN中p的计算方式如下:
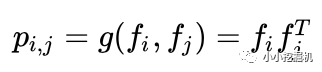
此时pij为M*M的矩阵,计算一个pij的时间复杂度为M*M,而p是N*N*M*M的矩阵,因此计算p的事件复杂度为N*N*M*M。从而计算lp的时间复杂度变为D1 * N*N*M*M。这个显然代价很高的。为了减少负责度,论文使用了叠加的思想,它重新定义了p矩阵:
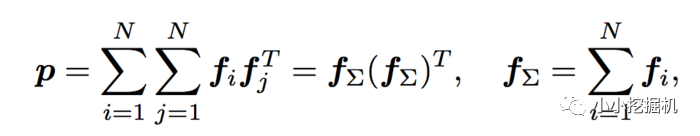
这里计算p的时间复杂度变为了D1*M*(M+N)
3、代码实战
终于到了激动人心的代码实战环节了,一直想找一个实现比较好的代码,找来找去tensorflow没有什么合适的,倒是pytorch有一个不错的。没办法,只能自己来实现啦,因此本文的代码严格根据论文得到,有不对的的地方或者改进之处还望大家多多指正。
本文的github地址为:https://github.com/princewen/tensorflow_practice/tree/master/Basic-PNN-Demo.
本文的代码根据之前DeepFM的代码进行改进,我们只介绍模型的实现部分,其他数据处理的细节大家可以参考我的github上的代码.
模型输入
模型的输入主要有下面几个部分:
self.feat_index = tf.placeholder(tf.int32, shape=[None,None], name='feat_index')self.feat_value = tf.placeholder(tf.float32, shape=[None,None], name='feat_value')self.label = tf.placeholder(tf.float32,shape=[None,1],name='label')self.dropout_keep_deep = tf.placeholder(tf.float32,shape=[None],name='dropout_deep_deep')
feat_index是特征的一个序号,主要用于通过embedding_lookup选择我们的embedding。feat_value是对应的特征值,如果是离散特征的话,就是1,如果不是离散特征的话,就保留原来的特征值。label是实际值。还定义了dropout来防止过拟合。
权重构建
权重由四部分构成,首先是embedding层的权重,然后是product层的权重,有线性信号权重,还有平方信号权重,根据IPNN和OPNN分别定义。最后是Deep Layer各层的权重以及输出层的权重。
对线性信号权重来说,大小为D1 * N * M对平方信号权重来说,IPNN 的大小为D1 * N,OPNN为D1 * M * M。
def _initialize_weights(self): weights = dict() #embeddings weights['feature_embeddings'] = tf.Variable( tf.random_normal([self.feature_size,self.embedding_size],0.0,0.01), name='feature_embeddings') weights['feature_bias'] = tf.Variable(tf.random_normal([self.feature_size,1],0.0,1.0),name='feature_bias') #Product Layers ifself.use_inner: weights['product-quadratic-inner'] = tf.Variable(tf.random_normal([self.deep_init_size,self.field_size],0.0,0.01)) else: weights['product-quadratic-outer'] = tf.Variable( tf.random_normal([self.deep_init_size, self.embedding_size,self.embedding_size], 0.0, 0.01)) weights['product-linear'] = tf.Variable(tf.random_normal([self.deep_init_size,self.field_size,self.embedding_size],0.0,0.01)) weights['product-bias'] = tf.Variable(tf.random_normal([self.deep_init_size,],0,0,1.0)) #deep layers num_layer = len(self.deep_layers) input_size = self.deep_init_size glorot = np.sqrt(2.0/(input_size + self.deep_layers[0])) weights['layer_0'] = tf.Variable( np.random.normal(loc=0,scale=glorot,size=(input_size,self.deep_layers[0])),dtype=np.float32 ) weights['bias_0'] = tf.Variable( np.random.normal(loc=0,scale=glorot,size=(1,self.deep_layers[0])),dtype=np.float32 ) for i in range(1,num_layer): glorot = np.sqrt(2.0 / (self.deep_layers[i - 1] + self.deep_layers[i])) weights["layer_%d" % i] = tf.Variable( np.random.normal(loc=0, scale=glorot, size=(self.deep_layers[i - 1], self.deep_layers[i])), dtype=np.float32) # layers[i-1] * layers[i] weights["bias_%d" % i] = tf.Variable( np.random.normal(loc=0, scale=glorot, size=(1, self.deep_layers[i])), dtype=np.float32) # 1 * layer[i] glorot = np.sqrt(2.0/(input_size + 1)) weights['output'] = tf.Variable(np.random.normal(loc=0,scale=glorot,size=(self.deep_layers[-1],1)),dtype=np.float32) weights['output_bias'] = tf.Variable(tf.constant(0.01),dtype=np.float32) return weights
Embedding Layer这个部分很简单啦,是根据feat_index选择对应的weights['feature_embeddings']中的embedding值,然后再与对应的feat_value相乘就可以了:
# Embeddingsself.embeddings = tf.nn.embedding_lookup(self.weights['feature_embeddings'],self.feat_index) # N * F * Kfeat_value = tf.reshape(self.feat_value,shape=[-1,self.field_size,1])self.embeddings = tf.multiply(self.embeddings,feat_value) # N * F * K
Product Layer根据之前的介绍,我们分别计算线性信号向量,二次信号向量,以及偏置项,三者相加同时经过relu激活得到深度网络部分的输入。
# Linear Singallinear_output = []for i in range(self.deep_init_size): linear_output.append(tf.reshape( tf.reduce_sum(tf.multiply(self.embeddings,self.weights['product-linear'][i]),axis=[1,2]),shape=(-1,1)))# N * 1self.lz = tf.concat(linear_output,axis=1) # N * init_deep_size# Quardatic Singalquadratic_output = []if self.use_inner: for i in range(self.deep_init_size): theta = tf.multiply(self.embeddings,tf.reshape(self.weights['product-quadratic-inner'][i],(1,-1,1))) # N * F * K quadratic_output.append(tf.reshape(tf.norm(tf.reduce_sum(theta,axis=1),axis=1),shape=(-1,1))) # N * 1else: embedding_sum = tf.reduce_sum(self.embeddings,axis=1) p = tf.matmul(tf.expand_dims(embedding_sum,2),tf.expand_dims(embedding_sum,1)) # N * K * K for i in range(self.deep_init_size): theta = tf.multiply(p,tf.expand_dims(self.weights['product-quadratic-outer'][i],0)) # N * K * K quadratic_output.append(tf.reshape(tf.reduce_sum(theta,axis=[1,2]),shape=(-1,1))) # N * 1self.lp = tf.concat(quadratic_output,axis=1) # N * init_deep_sizeself.y_deep = tf.nn.relu(tf.add(tf.add(self.lz, self.lp), self.weights['product-bias']))self.y_deep = tf.nn.dropout(self.y_deep, self.dropout_keep_deep[0])
Deep Part论文中的Deep Part实际上只有一层,不过我们可以随意设置,最后得到输出:
# Deep componentfor i in range(0,len(self.deep_layers)): self.y_deep = tf.add(tf.matmul(self.y_deep,self.weights["layer_%d" %i]), self.weights["bias_%d"%i]) self.y_deep = self.deep_layers_activation(self.y_deep) self.y_deep = tf.nn.dropout(self.y_deep,self.dropout_keep_deep[i+1])self.out = tf.add(tf.matmul(self.y_deep,self.weights['output']),self.weights['output_bias'])
剩下的代码就不介绍啦!好啦,本文只是提供一个引子,有关PNN的知识大家可以更多的进行学习呦。
-
求助。我国市级电话网络结构2013-11-09 0
-
【我是电子发烧友】如何加速DNN运算?2017-06-14 0
-
linux不同网络结构的不同IP设法2019-07-05 0
-
神经网络结构搜索有什么优势?2019-09-11 0
-
手绘网络结构图2019-10-25 0
-
网络结构与IP分组交换技术2021-12-23 0
-
TD-SCDMA网络结构2009-06-19 2245
-
TD-SCDMA R4网络结构和技术要求2009-07-30 401
-
DeviceNet 网络结构2010-03-22 759
-
HFC网络,HFC网络结构组成是什么?2010-03-20 9554
-
环形网络,环形网络结构是什么?2010-03-22 5831
-
ATM网络结构和接口2010-06-10 1975
-
4G网络结构及关键技术2011-11-10 1408
-
一种改进的深度神经网络结构搜索方法2021-03-16 672
-
如何优化PLC的网络结构?2023-12-23 354
全部0条评论

快来发表一下你的评论吧 !
