

无芯可用,谁将是人脸识别的最佳伴侣?
电子说
描述
高速增长的人脸识别仍面临无芯可用窘境,其中GPU、ASIC、DSP以及万能芯片FPGA是最为活跃的4大类型;只是互有优劣势的它们,谁终将是人脸识别的最佳伴侣?请看机器人文明给您带来的解读。
在过去的几十年间,人工智能一直在默默地发展,期间出现过数次“指日可待”的破发期,但最终都因为算法不成熟而反复沉沦。直到2013-2014年,随着旷视、商汤(这两家企业同根同源)的横空出世,以人脸识别技术为代表的人工智能瞬间引爆资本市场,随之而来的就是捷报频传的AI应用创新。
发展强劲,牵引AI一路狂奔
据科技部火炬中心发布的《2017年中国独角兽企业发展报告》显示,2017年我国164家独角兽企业中,人工智能企业数量有6家,占比3.66%,独角兽企业数量排名第10位;据报告分析,这6家企业总估值120亿美元,在整个独角兽企业估值中占比1.91%,位居全行业第11位。
图表1:2017年人工智能独角兽企业情况(数据来源:前瞻产业研究院)
在这一波AI浪潮中,人脸识别作为爆发点,是目前成长最为迅速的AI应用,据前瞻产业研究院发布的《人脸识别行业市场前瞻与投资战略规划分析报告》数据显示,2017年全球人脸识别市场规模约为31.8亿美元,预计未来一段时间人脸识别市场规模将保持20%左右的增速,预测到2022年,全球人脸识别市场规模将达75.95亿美元。
本土人脸识别企业也随着这一波浪潮成为了中国“万众创新”的一张名片,商汤、旷视、云从、云天励飞、依图这5家企业,放眼全球,它们的技术水平均处于行业领先地位。
前瞻数据库公布的数据显示,我国人脸识别市场规模近几年年均复合增长率达27%。2016年,我国人脸识别行业市场规模约为17.25亿元;2017年其市场规模已超过20亿元,预计未来5年增速仍将保持年均25%的高度,至2022年达到65亿元以上。
当然,其背后与资本的推助离不开,去年11月,旷视科技(Face++)完成了4.6亿美元的C轮融资,本轮融资一举打破了国际范围内人工智能领域融资记录;而不久后,该记录即被商汤打破,今年4月9日,商汤获得6亿美元C轮融资;紧接着5月31日,再次获得6.2亿美元C+轮融资,从2014年创立至今,商汤科技的融资总额可能已超过17亿美元。
芯片:竟是人脸识别发展的最大绊脚石
神经网络卷积深度学习技术令人脸识别瞬间提升到3D多维算法领域,人类这才终于从算法层面解决了人脸识别不精准、实战难的问题,让人脸识别技术从此走向应用。
不过,问题也随之而来:即便融资号令全球,但没有落地,人脸识别就只能飘在天空,落地才是硬道理。于是行业玩家在继续追逐算法极致的同时,开始了一轮又一轮的产品硬件化。
经过几年的实践检验后发现,当下AI三大要素中影响人脸识别推广应用的关键不是算法、也不是大数据,而是主观认为早已解决的算力问题——运行人脸识别深度学习算法的最佳处理器。
人脸识别运算流程主要有4个:视频采集→特征提取→数据比对→识别。
由于目前没有专门用于人脸识别的处理芯片,只能采用通用芯片代为处理。因深度学习算法对算力资源需求高,一般采取核心处理器,如CPU、ARM芯片进行视频采集,把视频中的人脸图像抠取下来,然后把该人脸图像发送给下一处理单元进行结构化处理。
结构化处理是人脸识别的关键。最初方案是在CPU上做处理,但由于CPU负责逻辑算数的部分并不多,在多任务处理时效率低下,有分析认为,12颗NVIDIA GPU可以提供相当于2000颗CPU的深度学习性能;在图像处理,CPU的先天劣势决定了其在人脸识别应用上被弃用的结局,该结论同样适用于应用于Linux系统的ARM处理器。
图表2:CPU与GPU结构对比(图片来源:NVIDIA)
核心数据处理芯片无法执行人脸识别结构化运算,只能将图像处理的工作交给更合适的专门处理芯片,目前常见的有GPU显示核心、FPGA现场可编程门阵列、ASIC专用集成电路、DSP数字信号处理。
GPU:当下AI的主导者
GPU的优势在于解决浮点运算、数据并行计算问题,在大量数据元素并行程序方面具有极高的计算密度。
GPU的应用现已不再局限于3D图形处理了,而是具备强大计算能力的处理器,其在人工智能、深度学习高速并行运算的优势凸显。
GPU在云计算、AR/VR、AI中的重要性不断被产业界和资本市场验证和认可,其中,全球龙头NVIDIA是GPU领域的绝对领导者,过去几年实现了股票的数倍增长;业绩方面也是处于高速增长态势,在整个2018财年,英伟达营收为97.14亿美元,与2017财年的69.10亿美元相比增长41%;净利润为30.47亿美元,与2017财年的16.66亿美元相比增长83%。
目前全球超级计算机TOP 500上榜的所有超级计算机有96%都使用了配备英伟达GPU的核心加速器,它所占份额为60%。紧随其后的是Xeon Phi,所占份额为21%。
图表3:英伟达近两年股票涨势(数据来源:东方财富网)
无形中,GPU成为了当下人脸识别算力资源的绝对主力,从行业采用情况看,但凡是采用中心集中处理组网架构的人脸识别项目,清一色采用GPU作为人像数据结构化的处理单元,特别是在X86服务器集群中,GPU更是成为唯一选择。
虽然GPU优势凸显,却也存在两个致命硬伤,一是功耗大,需依托X86架构服务器运行,不适用于更为广泛的人脸识别产品方案开发;尤其是人脸识别民用化趋势日渐增强的当下,GPU不适于在小型化项目的采用。二是成本高昂,采用GPU方案,折算单路人脸识别成本在万元以上,相较其他千元级,甚至是百元级的方案,毫无成本优势可言,不利于商业平民化推广。
这两个致命短板,令众人脸识别创业公司不得不寻求新的方案;目前在一些中小型项目中,GPU早已被弃选,如道闸、过道等前景同样广阔的领域。
FPGA:被赋予厚望的替代品
场效可编程逻辑闸阵列FPGA运用硬件语言描述电路,根据所需要的逻辑功能对电路进行快速烧录。一个出厂后的成品FPGA的逻辑块和连接可以按照设计者的需要而改变。
FPGA和GPU内都有大量的计算单元,因此它们的计算能力都很强。不过FPGA的可编程性,让软件与终端应用公司能够提供与其竞争对手不同的解决方案,并且能够灵活地针对自己所用的算法修改电路。其中峰值性能、平均性能与功耗能效比就是决定FPGA与GPU谁能在服务器端占领高地的重要因素。
同样是擅长并行计算的FPGA和GPU,两者性能都较CPU强许多,其中GPU能同时运行成千上万个核心同时跑在GHz的频率上,最新的GPU峰值性能甚至可以达到10TFlops以上。
相对而言,FPGA首先设计资源受到很大的限制,例如GPU如果想多加几个核心只要增加芯片面积就行,但FPGA一旦型号选定了,其逻辑资源上限就确定了。
而且,FPGA里面的逻辑单元是基于SRAM查找表,其性能会比GPU里面的标准逻辑单元差很多。
最后,FPGA的布线资源也受限制,因为有些线必须要绕很远,不像GPU这样走ASIC flow可以随意布线,因此,在峰值性能方面,FPGA要远逊于GPU。
平均性能方面,目前机器学习大多使用SIMD架构,即只需一条指令可以平行处理大量数据,因此用GPU很适合。但是有些应用是MISD,即单一数据需要用许多条指令平行处理,这种情况下用FPGA做一个MISD的架构就会比GPU有优势。对于平均性能,看的就是FPGA加速器架构上的优势是否能弥补运行速度上的劣势。如果FPGA上的架构优化可以带来相比GPU架构两到三个数量级的优势,那么FPGA在平均性能上会好于GPU。
功耗方面,GPU的功耗远大于FPGA的功耗,单一比对中,FPGA无疑是分布式部署人脸识别网络的最佳选择。但如果要比较功耗的同时再比较同等执行效率的功耗,FPGA则没有优势。不过在GPU无法改变的当下,FPGA给予了行业无限的希望,如果FPGA的架构优化能做到很好以致于一块FPGA的平均性能能够接近一块GPU,那么FPGA方案的总功耗远小于GPU,那么FPGA取代GPU将成为人脸图像结构化的不二选择。
FPGA器件的行业集中度同样很高,全球前四大产商均来自美国,分别为:Xilinx(赛灵思)、Altera(阿尔特拉)、Lattice(莱迪思)和Microsemi(美高森美), 总共占据了98%以上的市场份额。其中第一的Xilinx占49%,第二的Altera占39%,二者合计占比达88%市场份额,形成了双寡头的竞争格局。
ASIC、DSP:小型项目高性价比选配方案
ASIC、DSP都属于串行计算。ASIC芯片的优势是运算能力强、规模量产成本低,但开发周期长、单次流片成本高,主要适用于量大、对运算能力要求较高、开发周期较长的领域,比如大部分消费电子芯片和实验。
DSP内包括有控制单元、运算单元、各种寄存器以及一定数量的存储单元等等,在其外围还可以连接若干存储器,并可以与一定数量的外部设备互相通信,有软、硬件的全面功能,本身就是一个微型计算机。它不仅具有可编程性,而且其实时运行速度可达每秒数以千万条复杂指令程序,远远超过通用微处理器,是数字化电子世界中日益重要的电脑芯片。它的强大数据处理能力和高运行速度,是最值得称道的两大特色。
由于它运算能力很强、速度很快、体积很小,而且采用软件编程具有高度的灵活性,因此为从事各种复杂的应用提供了一条有效途径。当然,与通用微处理器相比,DSP芯片的其他通用功能相对弱些。但到目前为止,DSP 并没能真正提供任何有用的性能或是可以与 GPU 相匹敌的器件,其主要原因就是核数量,导致不少 DSP 被FPGA取代。
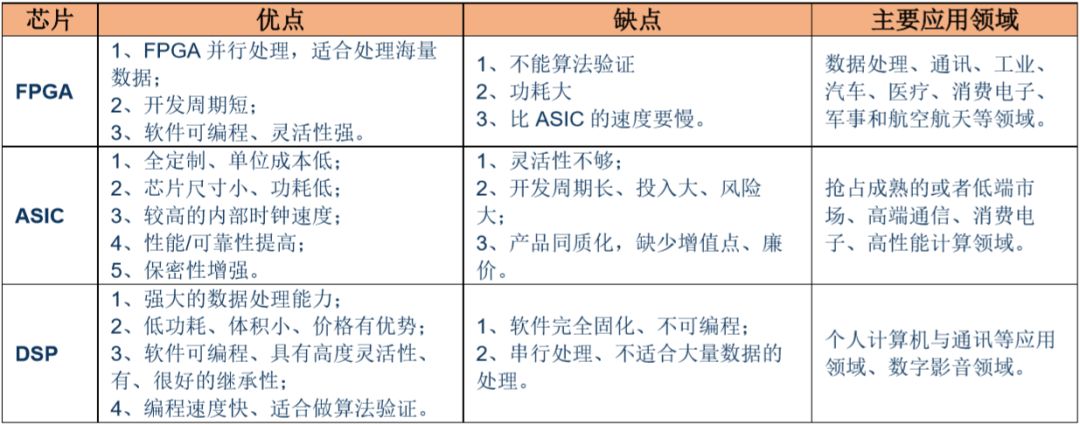
图表4:FPGA、ASIC、DSP优缺点比较、应用领域(数据来源:华创证券)
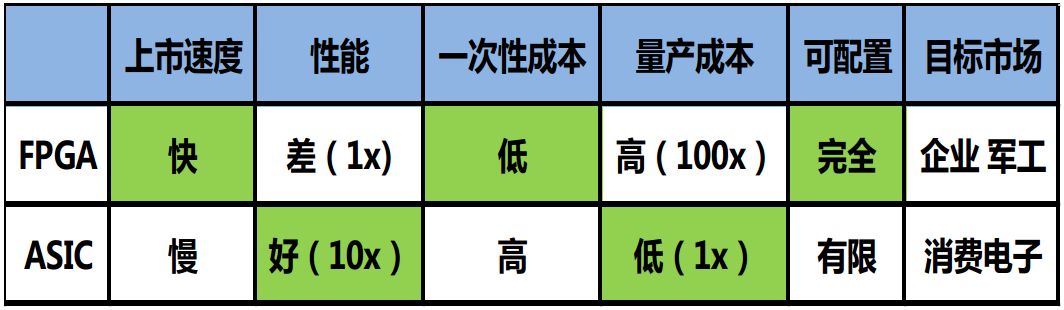
图表5:FPGA VS ASIC(数据来源:机器之心)
相较ASIC、DSP来说,FPGA的功耗仍比较大,成本优势也不足以支撑高性价比的人脸识别方案设计,因此,目前针对边缘云计算的最新应用方案,ASIC、DSP的选用性更强。
而当下人脸识别算法基本都得到了充分的大数据训练,算法成熟度已经较高,其应用也不再一味追求极限,对一些准确率不是极度变态的场合,ASIC、DSP成为了首选,比如监控的AI赋能。
其中,又因DSP更具开发周期优势,我们已经看到,ARM+DSP的处理方案已经成为人脸识别超低性价比首选,目前的百元级、千元级人脸识别产品正是基于该方案实现;当然,受限于DSP的大量数据处理性能,可在小型化服务器中同时采用多颗DSP共同组建方案,如一部分资源负责人像分析,另一部分DSP资源用于特征提取。
目前TI和海思的方案采用最为广泛。
TI的达芬奇解决方案中,DM644X系统内嵌DSP,可将人脸检测置于其中便能达到实时处理,适用于DVS解决方案设计,当然,因为该方案系统架构较为复杂,软件设计困难度要相对高些。
而海思的351X系统为ARM+ASIC结构,编码算法运行于ASIC中,其他功能则运行于内嵌的ARM中。这两个方案中,TI的解决方案处理能力最好,但价格也略高;海思则在系统简洁化、开发成本上有优势。
为满足当下人脸识别等人工智能的发展需求,行业也推出了各种针对深度学习芯片,如TPU、NPU、DPU、BPU等。
相比GPU,TPU更加类似于DSP,尽管计算能力略有逊色,可其功耗大大降低,当然,TPU的应用还是要受到CPU的控制;
深鉴科技基于Xilinx可重构特性FPGA芯片开发的DPU属于半定制化的FPGA,作为专用的深度学习处理单元使用;
NPU相比于CPU中采取的存储与计算相分离的冯诺伊曼结构,NPU通过突触权重实现存储和计算一体化,从而大大提高运行效率,其典型代表有国内的寒武纪芯片和IBM的TrueNorth,另外,中星微电子的“星光智能一号”虽说对外号称是NPU,但其实只是DSP,仅支持网络正向运算,无法支持神经网络训练;
BPU主要是用来支撑深度神经网络,比如图像、语音、文字、控制等方面的任务,而不是去做所有的事情,用BPU来实现会比在CPU上用软件实现要高效,一般来说会提高2-3个数量级,然而,BPU一旦生产,不可再编程,且必须在CPU控制下使用。
此外,算法企业也在积极与芯片企业合作,加速推出符合需求的人脸识别芯片产品。
如近日商汤就与中国芯片研发企业Rockchip瑞芯微展开了深度合作,瑞芯微将在旗下芯片平台全线预装商汤人脸识别SDK软件包,首批芯片包括瑞芯微RK3399Pro、RK3399、RK3288三大主力平台。其中RK3399ProAI芯片首次采用了CPU+GPU+NPU硬件结构设计。
而英特尔作为一代芯片巨头,也在发力GPU以期稳固其龙头地位,接连收购了Altera、Mobileye等企业,欲在搭载强大CPU核心的多核异构处理器方面大展宏图,虽然目前该梦想还没有得到很好实现,不过也被认为是未来解决人工智能算力瓶颈的有效方案之一。
小结
目前人脸识别的最佳芯片方案仍是GPU,实际落地的小型项目则可以采用DSP等能耗低的高性价比方案;而FPGA的优势,也让它具备取代GPU的可能,只是受制于专利墙及技术,更多的希望只能寄托于FPGA四大家族发展进度。
当然,人脸识别的应用万万千,场景应用创新也还在持续开发中,概括起来主要有三种场景方案需求。
一是终端一体化集成图像采集、人脸采集、特征提取、数据比对、识别全流程,如手机解锁、移动支付等,该场景主要是1:1识别方式,其对安全性要求最为严苛,一般都会通过红外技术辅助建立3D人像模型以确保真人识别;
二是云边应用,此时图像采集与人脸识别AI应用独立,对分析处理模块性能要求较高,一般有1:N、N:N两种识别方式,而需要红外辅助建模还是平台虚拟建模,根据场景安全等级抉择,如人脸道闸以支持真人识别为佳;
三是中心处理,该模式基本不用做图像采集,主要是识别认证和大数据碰撞研判,动辄百亿、千亿量级,对处理芯片要求非常高,目前基本可以说只有GPU才是最佳选择。
三种场景,需求不一样,方案也将不一样,以目前的芯片技术水平,还很难下结论说谁是最好的芯片,只有最适合、最容易落地的方案才是王道,人脸识别作为AI创新的引领者,活下去,才能推助性能更优芯片面世。
-
人脸识别的研究范围和优势2017-06-29 0
-
LabVIEW人脸识别设计2019-04-28 0
-
人脸识别的三大模式2019-08-06 0
-
S32V视觉处理平台怎么实现人脸识别的应用?2020-11-26 0
-
人脸识别的全部源代码2021-08-06 0
-
基于瑞芯微高性能核心板的人脸识别方案2023-01-05 0
-
基于瑞芯微RV1109的酒店人脸识别应用2023-01-29 0
-
人脸识别的好处与坏处2019-03-04 29190
-
人脸识别的手机有哪些2019-03-04 11038
-
人脸识别的原理2019-03-04 11386
-
人脸识别的原理说明2020-06-17 3048
-
何为人脸识别_人脸识别的应用场景2020-10-30 2755
-
人脸识别的优点和识别方法2023-02-06 527
-
人脸识别的算法有哪些2023-08-09 3282
-
生物识别和人脸识别的区别2023-08-28 846
全部0条评论

快来发表一下你的评论吧 !
