

几种常见的用于回归问题的机器学习算法
电子说
描述
当我们要解决任意一种机器学习问题时,都需要选择合适的算法。在机器学习中存在一种“没有免费的午餐”定律,即没有一款机器学习模型可以解决所有问题。不同的机器学习算法表现取决于数据的大小和结构。所以,除非用传统的试错法实验,否则我们没有明确的方法证明某种选择是对的。
但是,每种机器学习算法都有各自的有缺点,这也能让我们在选择时有所参考。虽然一种算法不能通用,但每个算法都有一些特征,能让人快速选择并调整参数。接下来,我们大致浏览几种常见的用于回归问题的机器学习算法,并根据它们的优点和缺点总结出在什么情况下可以使用。
线性和多项式回归
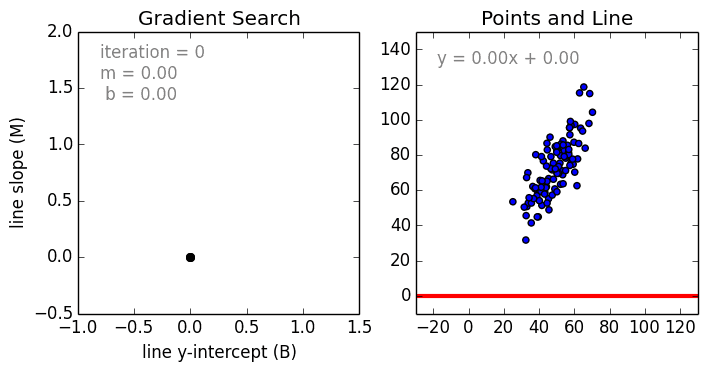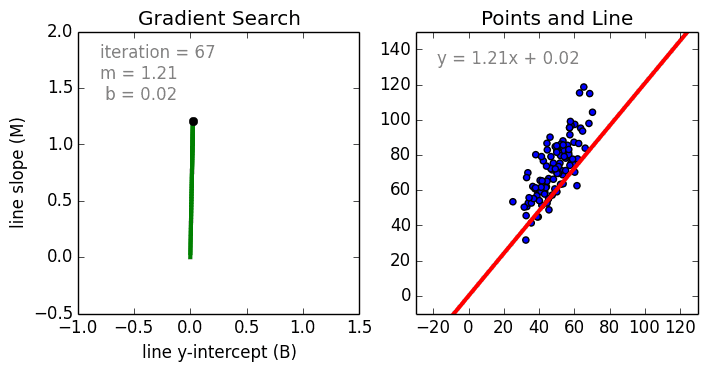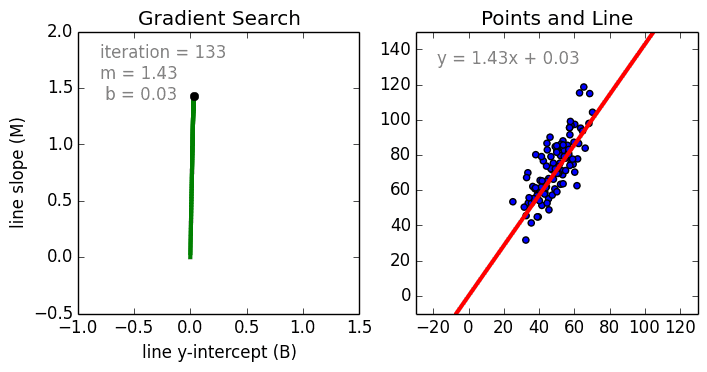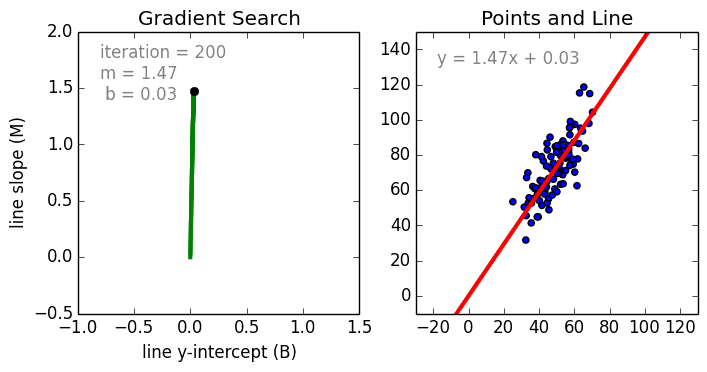
首先是简单的情况,单一变量的线性回归是用于表示单一输入自变量和因变量之间的关系的模型。多变量线性回归更常见,其中模型是表示多个输入自变量和输出因变量之间的关系。模型保持线性是因为输出是输入变量的线性结合。
第三种行间情况称为多项式回归,这里的模型是特征向量的非线性结合,即向量是指数变量,sin、cos等等。这种情况需要考虑数据和输出之间的关系,回归模型可以用随机梯度下降训练。
优点:
建模速度快,在模型结构不复杂并且数据较少的情况下很有用。
线性回归易于理解,在商业决策时很有价值。
缺点:
对非线性数据来说,多项式回归在设计时有难度,因为在这种情况下必须了解数据结构和特征变量之间的关系。
综上,遇到复杂数据时,这些模型的表现就不理想了。
神经网络
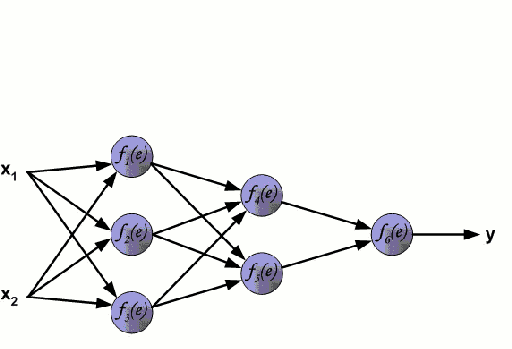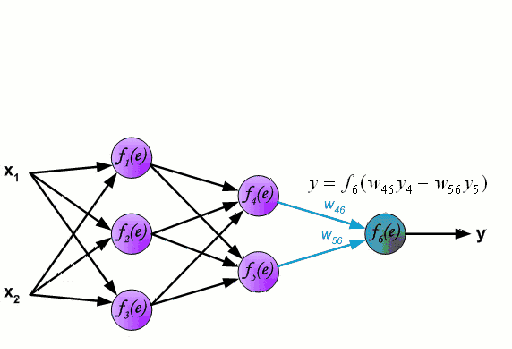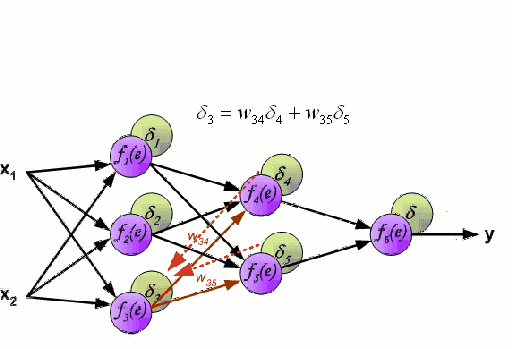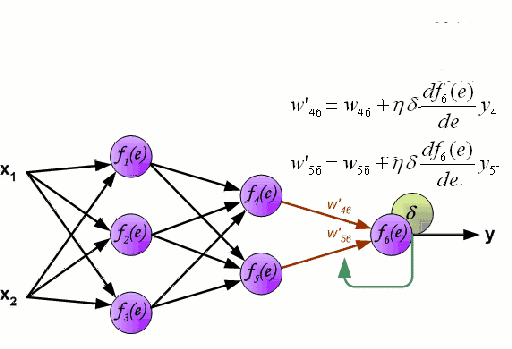
神经网络包含了许多互相连接的节点,称为神经元。输入的特征变量经过这些神经元后变成多变量的线性组合,与各个特征变量相乘的值称为权重。之后在这一线性结合上应用非线性,使得神经网络可以对复杂的非线性关系建模。神经网络可以有多个图层,一层的输出会传递到下一层。在输出时,通常不会应用非线性。神经网络用随机梯度下降和反向传播算法训练。
优点:
由于神经网络有很多层(所以就有很多参数),同时是非线性的,它们能高效地对复杂的非线性关系进行建模。
通常我们不用担心神经网络中的数据,它们在学习任何特征向量关系时都很灵活。
研究表明,单单增加神经网络的训练数据,不论是新数据还是对原始数据进行增强,都会提高网络性能。
缺点:
由于模型的复杂性,它们不容易被理解。
训练时可能有难度,同时需要大量计算力、仔细地调参并且设置好学习速率。
它们需要大量数据才能达到较高的性能,与其他机器学习相比,在小数据集上通常表现更优。
回归树和随机森林
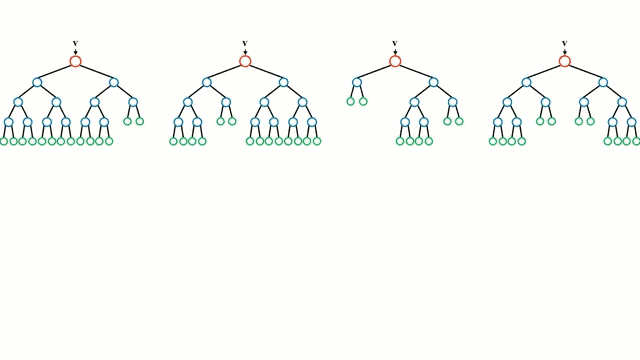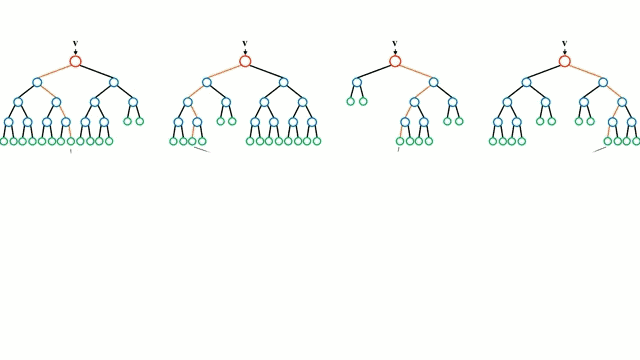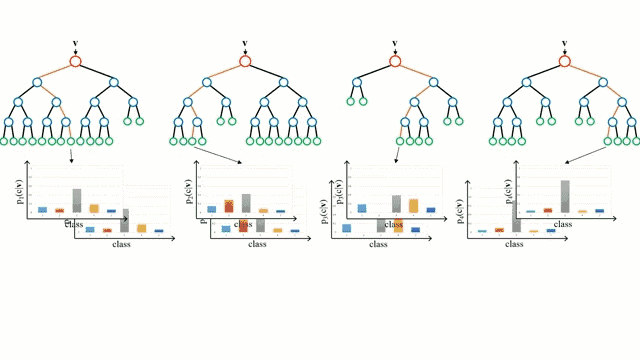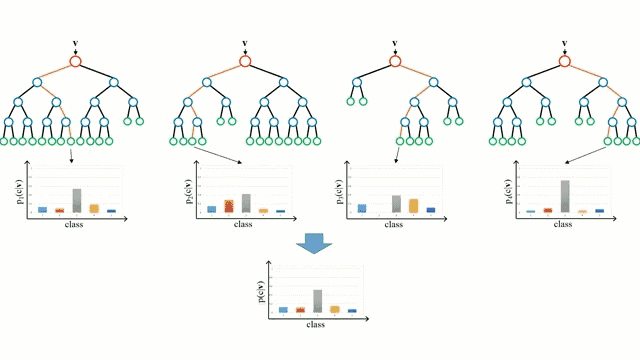
首先从基本情况开始,决策树是一种直观的模型,决策者需要在每个节点进行选择,从而穿过整个“树”。树形归纳是将一组训练样本作为输入,决定哪些从哪些属性分割数据,不断重复这一过程,知道所有训练样本都被归类。在构建树时,我们的目标是用数据分割创建最纯粹的子节点。纯粹性是通过信息增益的概念来衡量的。在实际中,这是通过比较熵或区分当前数据集中的单一样本和所需信息量与当前数据需要进一步区分所需要的信息量。
随机森林是决策树的简单集成,即是输入向量经过多个决策树的过程。对于回归,所有树的输出值是平均的;对于分类,最终要用投票策略决定。
优点:
对复杂、高度非线性的关系非常实用。它们通常能达到非常高的表现性能,比多项式回归更好。
易于使用理解。虽然最后的训练模型会学会很多复杂的关系,但是训练过程中的决策边界易于理解。
缺点:
由于训练决策树的本质,它们更易于过度拟合。一个完整的决策树模型会非常复杂,并包含很多不必要的结构。虽然有时通过“修剪”和与更大的随机森林结合可以减轻这一状况。
利用更大的随机森林,可以达到更好地效果,但同时会拖慢速度,需要更多内存。
这就是三种算法的优缺点总结。希望你觉得有用!
-
【下载】《机器学习》+《机器学习实战》2017-06-01 0
-
【阿里云大学免费精品课】机器学习入门:概念原理及常用算法2017-06-23 0
-
分享一个自己写的机器学习线性回归梯度下降算法2018-10-02 0
-
干货 | 这些机器学习算法,你了解几个?2019-09-22 0
-
机器学习的回归任务2019-10-29 0
-
机器学习100天之多元线性回归2020-05-12 0
-
回归算法有哪些,常用回归算法(3种)详解2020-07-28 0
-
机器学习算法如何用于制造无人驾驶汽车?2021-03-18 0
-
人工智能基本概念机器学习算法2021-09-06 0
-
细数几种常见的自动驾驶中的机器学习算法2017-09-22 1247
-
人工智能之机器学习常见算法2018-02-02 1574
-
如何帮你的回归问题选择最合适的机器学习算法2019-05-03 2617
-
机器学习算法汇总 机器学习算法分类 机器学习算法模型2023-08-17 734
-
机器学习算法总结 机器学习算法是什么 机器学习算法优缺点2023-08-17 1103
-
机器学习有哪些算法?机器学习分类算法有哪些?机器学习预判有哪些算法?2023-08-17 1413
全部0条评论

快来发表一下你的评论吧 !
