

深度学习显卡选型指南:关于GPU选择的一般建议
电子说
描述
深度学习是一个对算力要求很高的领域,GPU的选择将从根本上决定你的深度学习体验。如果没有GPU,可能你完成整个实验需要几个月,甚至当你只想看看参数调整、模型修改后的效果时,那可能也得耗费1天或更久的时间。
凭借性能良好、稳定的GPU,人们可以快速迭代深层神经网络的架构设计和参数,把原本完成实验所需的几个月压缩到几天,或是把几天压缩到几小时,把几小时压缩到几分钟。因此,在选购GPU时做出正确选择至关重要。
下面是华盛顿大学博士Tim Dettmers结合竞赛经验给出的GPU选择建议,有需要的读者可把它可作为参考意见。
当一个人开始涉足深度学习时,拥有一块高速GPU是一件很重要的事,因为它能帮人更高效地积累实践经验,而经验是掌握专业知识的关键,能打开深入学习新问题的大门。如果没有这种快速的反馈,我们从错误中汲取经验的时间成本就太高了,同时,过长的时间也可能会让人感到挫败和沮丧。
以我个人的经验为例。通过配置合理的GPU,我在短时间内就学会把深度学习用于一系列Kaggle竞赛,并在Chaly of Hashtags比赛中取得第二名。当时我构建了一个相当大的两层深层神经网络,里面包含用于整流的线性神经元和用于正则化的损失函数。
像这么深的网络,我手里的6GB GPU是跑不动的。所以之后我入手了一块GTX Titan GPU,这也是最终获得佳绩的主要原因。
终极建议
性能最好的GPU:RTX 2080 Ti
性价比高,但小贵:RTX 2080, GTX 1080
性价比高,同时便宜:GTX 1070, GTX 1070 Ti, GTX 1060
使用的数据集>250GB:RTX 2080 Ti, RTX 2080
预算很少:GTX 1060 (6GB)
几乎没预算:GTX 1050 Ti (4GB)/CPU(建模)+ AWS/TPU(训练)
参加Kaggle竞赛:GTX 1060 (6GB)(建模)+ AWS(最终训练)+ fast ai库
有前途的CV研究员:GTX 2080 Ti; 在2019年升级到RTX Titan
普通研究员:RTX 2080 Ti/GTX 10XX -> RTX Titan,注意内存是否合适
有雄心壮志的深度学习菜鸟:从GTX 1060 (6GB)、GTX 1070、GTX 1070 Ti开始,慢慢进阶
随便玩玩的深度学习菜鸟:GTX 1050 Ti (4或2GB)
我应该多买几块GPU吗?
那时候,看到GPU能为深度学习提供这么多的可能性,我很兴奋,于是钻进了多GPU的“深坑”:我组装了一个IB 40Gbit/s的小型GPU阵列,希望它能产出更好的结果。
但现实很残酷,我很快就被“打脸”了,在多个GPU上并行训练神经网络不仅非常困难,一些常用的加速技巧也收效甚微。诚然,小型神经网络可以通过数据并行性大大降低训练用时,但由于我构建的是个大型神经网络,它的效率并没有多大变化。
面对失败,我深入研究了深度学习中的并行化,并在2016年的ICLR上发表了一篇论文:8-Bit Approximations for Parallelism in Deep Learning。在论文中,我提出了8位近似算法,它能在包含96个GPU的系统上获得50倍以上的加速比。与此同时,我也发现CNN和RNN非常容易实现并行化,尤其是在只用一台计算机或4个GPU的情况下。
所以,虽然现代GPU并没有针对并行训练做过高度优化,但我们仍然可以“花式”提速。
主机内部构造:3个GPU和一个IB卡,这适合深度学习吗?
N卡?A卡?Intel?谷歌?亚马逊?
NVIDIA:主导者
在很早的时候,NVIDIA就已经提供了一个标准库,这使得在CUDA中建立深度学习库非常容易。再加上那时AMD的OpenCL没有意识到标准库的前景,NVIDIA结合这个早期优势和强大的社区支持,让CUDA社区规模实现迅速扩张。发展至今,如果你是NVIDIA的用户,你就能在各个地方轻松找到深度学习的教程和资源,大多数库也都对CUDA提供最佳支持。
因此,如果要入手NVIDIA的GPU,强大的社区、丰富的资源和完善的库支持绝对是最重要的因素。
另一方面,考虑到NVIDIA在去年年底不声不响地修改了GeForce系列显卡驱动最终用户许可协议,数据中心只被允许使用Tesla系列GPU,而不能用GTX或RTX卡。虽然他们到现在都没有定义“数据中心”是什么,但考虑到其中的法律隐患,现在不少机构和大学开始购买更贵但效率低的Tesla GPU——即便价格上可能相差10倍,Tesla卡与GTX和RTX卡相比并没有真正优势。
这意味着作为个人买家,当你接受了N卡的便捷性和优势时,你也要做好接受“不平等”条款的心理准备,因为NVIDIA在这一领域占据垄断地位。
AMD:功能强大但缺乏支持
在2015年的国际超算会议上,AMD推出HIP,可以把针对CUDA开发的代码转换成AMD显卡可以运行的代码。这意味着如果我们在HIP中拥有所有GPU代码,这将是个重要的里程碑。但三年过去了,我们还是没能见证A卡在深度学习领域的崛起,因为这实践起来太困难,尤其是移植TensorFlow和PyTorch代码库。
确切来说,TensorFlow是支持AMD显卡的,所有常规网络都可以在AMD GPU上运行,但如果你想构建新网络,它就会出现不少bug,让你怎么都不能如意。此外,ROCm社区也不是很大,没法直接解决这个问题,再加上缺乏深度学习开发的资金支持,AMD比肩NVIDIA遥遥无期。
然而,如果我们对比两家的下一代产品,可以发现AMD的显卡显示出了强劲性能,未来,Vega 20可能会拥有类似Tensor-Core计算单元的计算能力。
总的来说,对于只是希望模型能在GPU上稳稳当当跑完的普通用户,目前我还找不到推荐AMD的理由,选N卡是最合适的。但如果你是GPU开发者或是希望对GPU计算做出贡献的人,你可以支持AMD,打击NVIDIA的垄断地位,因为这将使所有人长期受益。
Intel:努力尝试
用过Intel家的Phi后,我简直要“一生黑”。我认为它们不是NVIDIA或AMD卡的真正竞争对手,所以这里我们长话短说。如果你决定入手Xeon Phi,下面是你可能会遇到的问题:支持很烂、计算代码段比CPU慢、编写优化代码非常困难、不完全支持C++11、编译器不支持一些重要的GPU设计模式、和其他库的兼容性差(NumPy和SciPy)等等。
我真的很期待Intel的Nervana神经网络处理器(NNP),但自提出以来,它就陷入了无休无止的跳票。根据最近的说法,NNP会在2019年第三/第四季度出货,但参考他们家的Xeon Phi,如果我们想买颗技术成熟的NNP,估计至少得等到2020年。
谷歌:按需提供的廉价服务?
到现在为止,Google TPU已经发展成为非常成熟的云产品,性价比超高。要理解TPU,我们可以把它简单看做是打包在一起的多个GPU。如果你曾对比过Tensor-Core-enabled V100和TPUv2在ResNet50上的性能差距,如下图所示,可以发现,两者的准确率差不多,但TPU更便宜。
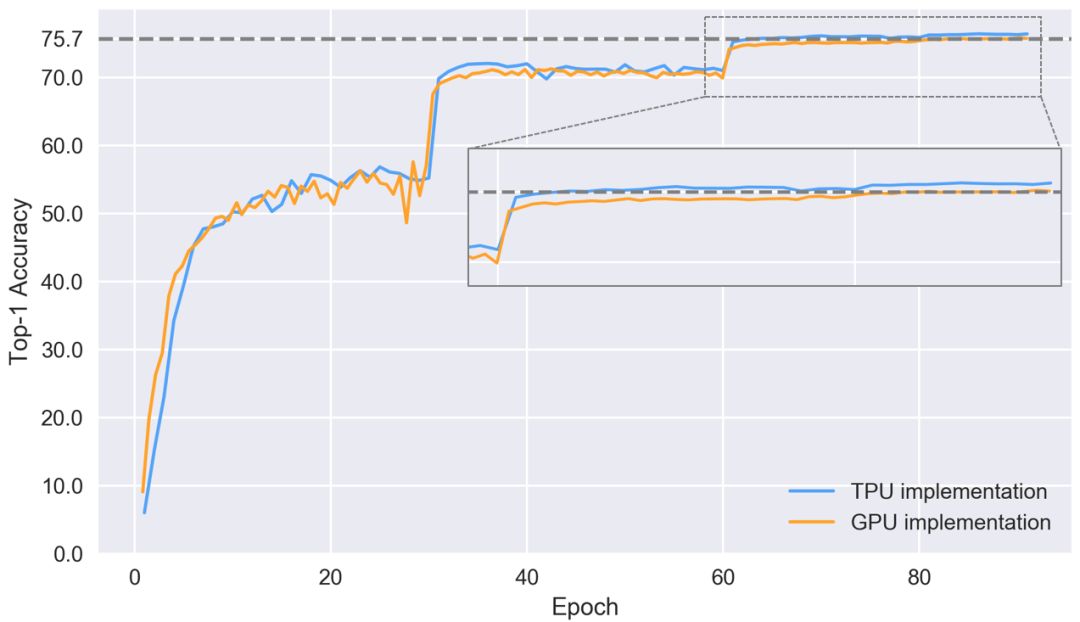
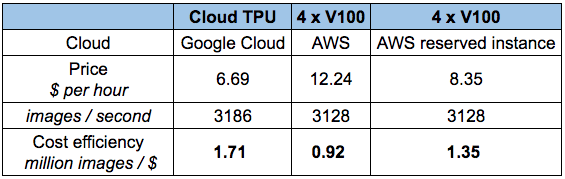
那么如果手头紧又期望高性能,是不是就选TPU呢?是,也不是。如果你要做论文研究,或是会频繁用到它,TPU确实是个经济实惠的选择。但是,如果你上过fast ai的课,用过fast ai库,你就会发现自己可以用更低的价格实现更快的收敛——至少对于CNN目标识别来说是这样的。
此外,虽然相比其他同类产品,TPU性价比更高,但它也存在不少问题:(1)TPU不能用于fast ai库,即PyTorch;(2)TPU算法主要依赖谷歌内部团队;(3)没有统一的高级库,无法为TensorFlow提供良好的标准。
以上三点都是TPU的痛点,因为它需要单独的软件才能跟上深度学习算法的更新迭代。我相信谷歌团队已经完成了一些列工作,但它们对某些任务的支持效果还是个未知数。因此,目前的TPU更适合计算机视觉任务,并作为其他计算资源的补充,我不建议开发者把它当做自己的主要深度学习资源。
亚马逊:可靠但昂贵
AWS的GPU很丰富,价格也有点高。如果突然需要额外的计算,AWS GPU可能是一个非常有用的解决方案,比如论文deadline快到了。
经济起见,如果要购买亚马逊服务,你最好只跑一部分网络,而且确切知道哪些参数最接近最佳选择。否则,这些因为自己失误多出来的花费可能会让你的钱包见底。所以,即便亚马逊的云GPU很快,我们还是自己买一块专用的实体显卡吧,GTX 1070很贵,但它至少也能用个一两年啊。
是什么决定了GPU的快慢?
是什么让这个GPU比那个GPU更快?面对这个问题,可能你最先想到的是看和深度学习有关的显卡特征:是CUDA核心吗?主频多少?RAM多大?
虽然“看内存带宽”是个“万金油”的说法,但我不建议这么做,因为随着GPU硬件和软件的多年开发,现在带宽已经不再是性能的唯一代名词。尤其是消费级GPU中Tensor Cores的引入,这个问题就更复杂了。
现在,如果要判断显卡性能好不好,它的指标应该是带宽、FLOPS和Tensor Cores三合一。要理解这一点,我们可以看看矩阵乘积和卷积这两个最重要的张量操作是在哪里被加速的。
提到矩阵乘积,最简单有效的一个理念是它受带宽限制。如果你想用LSTM和其他需要经常进行大量矩阵乘积运算的RNN,那么内存带宽是GPU最重要的特性。类似地,卷积受计算速度约束,因此对于ResNets和其他CNN,GPU上的TFLOP是性能的最佳指标。
Tensor Cores的出现稍稍改变了上述平衡。它们是非常简单的专用计算单元,可以加速计算——但不是内存带宽 ——因此对CNN来说,如果GPU里有Tensor Core,它们带来的最大改善就是速度提高约30%到100%。
虽然Tensor Cores只能提高计算速度,但它们也可以使用16bit数进行计算。这对矩阵乘法也是一个巨大优势,因为在具有相同存储器带宽的矩阵中,16bit数的信息传输量是32bit数的两倍。数字存储器大小的削减对于在L1高速缓存中存储更多数字特别重要,实现了这一点,矩阵就越大,计算效率也更高。所以如果用了Tensor Cores,它对LSTM的提速效果约为20%至60%。
请注意,这种加速不是来自Tensor Cores本身,而是来自它们进行16bit数计算的能力。AMD GPU也支持16bit数计算,这意味着在进行乘积运算时,它们其实和具有Tensor Cores的NVIDIA显卡一样快。
Tensor Cores的一个大问题是它们需要16位浮点输入数据,这可能会引入一些软件支持问题,因为网络通常使用32位。如果没有16位输入,Tensor Cores将毫无用处。但是,我认为这些问题将很快得到解决,因为Tensor Cores太强大了,现在它们已经出现在消费级GPU中,未来,使用它的人只会越来越多。请注意,随着16bit数被引入深度学习,GPU内存其实也相当于翻倍了,因为现在我们可以在同样大小的内存中存储比之前多一倍的参数。
总的来说,最好的经验法则是:如果用RNN,请看带宽;如果用卷积,请看FLOPS;如果有钱,上Tensor Cores(除非你必须购买Tesla)。
GPU和TPU的标准化原始性能数据,越高越好
成本效益分析
GPU的成本效益可能是选择GPU最重要的标准。我围绕带宽、TFLOP和Tensor Cores做了一项新的性价比分析。首先,显卡的销售价格来自亚马逊和eBay,两个平台的权重是50:50;其次,我查看了有无Tensor Cores的显卡在LSTM和CNN上的性能指标,对这些指标做归一化处理后进行加权,获得平均性能得分;最后,我计算得到了下面这个性能/成本比率:
围绕带宽、TFLOP和Tensor Cores的性价比,越高越好
根据初步数据,我们可以发现RTX 2080比RTX 2080 Ti更实惠。虽然后者在Tensor Cores和带宽上提升了40%,在价格上提高了50%,但这不意味着它能在深度学习性能上提升40%。对于LSTM和其他RNN,GTX 10系列和RTX 20系列带给它们的性能提升主要来自支持16bit数计算,而不是Tensor Cores;对于CNN,虽然Tensor Cores带来的计算速度提升效果明显,但它对卷积体系结构的其他部分也不存在辅助作用。
因此,相比GTX 10系列,RTX 2080在性能上实现了巨大提升;相比RTX 2080 Ti,它在价格上又占尽优势。所以RTX 2080性价比最高是可以理解的。
此外,图中的数据不可迷信,这个分析也存在一些问题:
如果你买了性价比更高但速度很慢的显卡,那么之后你的计算机可能就装不下更多显卡了,这是一种资源浪费。所以为了抵消这种偏差,上图会偏向更贵的GPU。
这个图假设我们用的是带Tensor Cores和16bit数计算的显卡,这意味着对于支持32bit数计算的RTX卡,它们的性价比会被统计得偏低。
考虑到“矿工”的存在,RTX 20系列开售后,GTX 1080和GTX 1070可能会迅速降价,这会影响性价比排名。
因为产品还未发布,表中RTX 2080和RTX 2080 Ti的数字存在水分,不可尽信。
综上可得,如果只从性价比角度看,选择最好的GPU是不容易的。所以如果你想根据自身条件选一款中庸的GPU,下面的建议是合理的。
关于GPU选择的一般建议
目前,我会推荐两种主要的选择方法:(1)购买RTX系列,然后用上两年;(2)等新品发布后,购买降价的GTX 1080/1070/1060或GTX 1080Ti / GTX 1070Ti。
很长一段时间内,我们一直在等GPU升级,所以对于很多人来说,第一种方法最立竿见影,现在就可以获得最好的性能。虽然RTX 2080更具成本效益,但RTX 2080 Ti内存更大,这对CV研究人员是个不小的诱惑。所以如果你是追求一步到位的人,买这两种显卡都是明智的选择,至于选择哪种,除了预算,它们的主要区别就是你究竟要不要RTX 2080 Ti的额外内存。
如果你想用16bit计算,选Ti,因为内存会翻倍;如果没这方面的需要,2080足矣。
至于第二种方法,它对那些想要追求更大的升级、想买RTX Titan的人来说是个不错的选择,因为GTX 10系列显卡可能会降价。请注意,GTX 1060有时会缺少某些型号,因此当你发现便宜的GTX 1060时,首先要考虑它的速度和内存是否真正满足自己的需求。否则,便宜的GTX 1070、GTX 1070 Ti、GTX 1080和GTX 1080 Ti也是绝佳的选择。
对于创业公司、Kaggle竞赛参赛者和想要学习深度学习的新手,我的推荐是价格便宜的GTX 10系列显卡,其中GTX 1060是非常经济的入门解决方案。
如果是想在深度学习上有所建树的新手,一下子买几个GTX 1060组装成阵列也不错,一旦技术纯熟,你可以在2019年把显卡升级到RTX Titan。
如果你缺钱,我会推荐4GB内存的GTX 1050 Ti,当然如果买得起,还是尽量上1060。请注意,GTX 1050 Ti的优势在于它不需要连接到PSU的额外PCIe,所以你可以把它直接插进现有计算机,节省额外资金。
如果缺钱又看重内存,eBay的GTX Titan X也值得入手。
我个人会买一块RTX 2080 Ti,因为我的GTX Titan X早该升级了,而且考虑到研究需要的内存比较大,加上我打算自己开发一个Tensor Core算法,这是唯一的选择。
小结
看到这里,相信现在的你应该知道哪种GPU更适合自己。总的来说,我提的建议就是两个:一步到位上RTX 20系列,或是买便宜的GTX 10系列GPU,具体参考文章开头的“终极建议”。性能和内存,只要你真正了解自己要的是什么,你就能挑出属于自己的最合适的显卡。
-
相比GPU和GPP,FPGA是深度学习的未来?2016-07-28 7657
-
FPGA在深度学习应用中或将取代GPU2024-03-21 1168
-
刚开始进行深度学习的同学怎么选择合适的机器配置2018-09-19 3548
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2025
-
关于AD的一般性介绍2017-10-18 891
-
关于AD的工具一般性介绍2017-11-01 822
-
深度学习之GPU硬件选型2018-01-06 4186
-
GPU和GPP相比谁才是深度学习的未来2019-10-18 1791
-
GPU 引领的深度学习2023-01-04 1179
-
深度学习如何让Turing 显卡如虎添翼2023-08-01 1113
-
深度学习算法的选择建议2023-08-17 1286
-
低压断路器选型的一般原则2023-11-06 6798
-
GPU在深度学习中的应用与优势2023-12-06 2367
-
深度学习GPU加速效果如何2024-10-17 972
-
GPU深度学习应用案例2024-10-27 2162
全部0条评论

快来发表一下你的评论吧 !
