

Web使用挖掘中的数据预处理模块、实现方法及发展前景
描述
1 Web挖掘
Web挖掘是指运用数据挖掘技术从Web页面中发现和抽取信息的过程。Web挖掘又分为3种类型:Web使用挖掘、Web结构挖掘和Web内容挖掘。Web使用挖掘的数据源主要是Web日志文件,通过挖掘Web日志可以了解用户的访问模式。基于用户的访问模式,可以对网站的链接进行相应的修正;了解用户兴趣,为用户定制个性化的页面;进行用户分类,对不同的用户实行不同的促销策略,提高投资回报率;向用户推荐Web页面等。
2 数据预处理
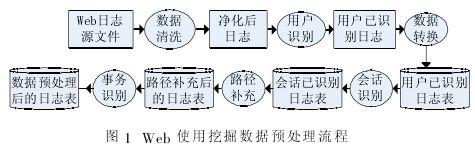
数据预处理是Web使用挖掘的第一个环节。预处理的对象是Web 日志文件。由于Web 日志文件的格式是半结构化的,且日志中的数据不够完整,因此需要对Web日志文件进行预处理,将其转化为易于挖掘的、具有良好格式的数据。数据预处理结果的好坏将直接影响后面所进行的事务识别、路径分析、关联规则挖掘和序列模式发现等环节的效果。Web使用的挖掘流程如图1所示,包括预处理、模式挖掘、模式分析和可视化。本文将重点研究其中的数据预处理模块。
数据预处理主要包括数据清理、用户识别和会话识别等几个步骤。
2.1 数据清理
数据清理的任务就是删除那些和挖掘目的无关的数据,避免无关数据对后续步骤的影响。由于网页中存在大量的图片(如GIF、JPEG、JPG等),当用户访问网页时,其中的图片都会作为单独的记录存在于日志文件中。对于大多数挖掘任务来说它们都是可以忽略的(但如果网站是专门提供图片的则要另外考虑)。删除这些记录可以减少后续步骤所要处理的数据量,提高处理速度,同时还可以减少无效数据对挖掘过程的影响。
例如,取自天津大学网站003年3月1日至3月7日一周的日志文件,共105MB,进行数据清理之前共有记录1 174 093条,按照上述方法清理之后剩余记录为378 747条,由此可以充分说明数据清理的作用。
2.2 用户识别
用户识别就是从日志文件中识别出有哪些用户访问了网站,以及每个用户访问了哪些网页。下面给出关于用户(User)的定义。
定义1 用户
用户的定义为User=〈UserID,User_IP,User_Referer_Page,User_Agent〉。UserID是识别出的用户的标识,User_IP、User_Referer_Page和User_Agent分别代表用户的IP地址、访问过的页面以及用户所用电脑的操作系统、浏览器版本信息。通过以上各项可以惟一确定用户。
已经注册的用户可以很容易被识别出来。而事实上,有许多用户未经注册,还有大量用户使用代理服务器上网,或多个用户共用一台电脑。此外防火墙的存在以及一个用户使用不同的浏览器等,都增加了用户识别难度。当然可以采用Cookies来追踪用户的行为,但是考虑到个人隐私问题,许多用户的浏览器是禁用Cookies的,因此有必要考虑其他方法解决该问题。
对于使用同一台电脑或者使用相同代理上网的多名用户的区分,可以借助于网站的拓扑图检测是否此次访问的页面可以从上次访问的页面直接到达,如果不能,则很有可能是多名用户共用一台电脑或者一个代理。但是该方法主要涉及的是网页拓扑结构的问题,没有考虑单个用户使用多个代理或者多台电脑的情况。此外,还可以通过基于导航模式(Navigation Patterns)的用户会话自动生成技术来识别用户。这种方法所侧重的是网页的分类和彼此之间的链接关系。所以上面二种方法在用户识别的过程中只是考虑了个别的影响因素,只能部分解决用户不确定的问题,没有充分考虑所有可能出现的情况。本文给出了一种新的用户及会话识别算法(User and Session IdentifICation Algorithm,USIA)。该算法综合考虑用户IP(User_IP)、网站的拓扑图、参考网页(Referer)和Agent来识别出单个用户。在考虑算法的精度和效率的前提下尽可能用更多的影响因素来识别用户,具有较好的准确性和可扩展性。
2.3 会话识别
一个会话就是指用户在一次访问过程中所访问的Web页面序列。下面给出了关于会话的定义。
定义2 会话
会话的定义为Session=〈Si,UserID,Times,Timee,[(url1,time1),(url2,time2)……(urlk,timek)]〉。Si是Session标识,UserID是用户识别过程所识别出的用户的标识,Times是会话的初始时间,Timee是会话的结束时间,urlk是此次会话所访问的页面urls,timek是页面urlk被访问的时间。
一个日志文件的时间跨度是不确定的,一名用户可能多次访问同一站点。会话识别的目的就是将用户每次的访问页面划分到不同的会话当中,这样以会话为基本单元将有助于模式的挖掘和分析。
区分一个用户的2个不同会话的最常用的方法是:规定一个超时值(常用的是30分钟),如果对2个页面的请求时间间隔超过了这个预先设定的阈值,则可以看作用户又开始了一次新的会话。由于将超时值预置为30分钟,并且经过了大量实际应用的检验,证明该方法简单易行,因此本文采用了该方法。
对于识别出的用户和会话需要存储起来,以备后续步骤进行挖掘时使用。此处定义了Cube作为用户和会话的数据存储格式。
定义3 Cube
Cube是算法USIA识别出的用户和会话的存储方式,定义为Cube=〈Si,UserID,User_IP,[(url1,time1), (url2,time2)……(urlk,timek)]〉。其中Si和UserID的含义同定义2,User_IP是用户的IP地址,urlk是此次会话所访问的页面Urls,timek是页面urlk被访问的时间。
2.4 USIA算法
2.4.1 USIA算法过程
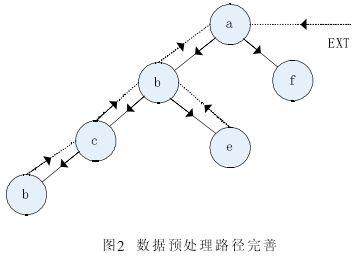
2.4.2 USIA算法的优点如下:
(1)准确度高:克服了传统方法中只采用IP地址区分访问者所导致的识别精度不高的缺点。该算法综合考虑用户IP、网站的拓扑图、参考网页和Agent来识别单个用户。在考虑算法的精度和效率的前提下尽可能用更多的影响因素来识别用户,具有较好的准确性和可扩展性。
(2)效率高:在一个算法中实现了用户识别和会话识别,克服了将用户识别和会话识别分开单独进行所引起的效率低的缺点。
(3)良好的数据存储格式:对于识别出的用户和会话,算法USIA构造出动态数据立方体存放用户ID、用户IP、用户Url、用户访问时间,避免了大量存储空间的浪费。
用户和会话的存储方式示意图如图3所示,纵轴表示识别出的用户和会话,其中n表示总的用户数,k表示某用户的第k个会话,不同的用户会话采用不同的UserID来表示,如1-1,2-1,3-1,……n-k.同一用户可能有多个不同的会话,如图中用户3有2个会话3-1和3-2.
IPn表示第n个用户的IP地址。横轴表示在一次单独的会话中用户所访问的页面Url序列,该序列按时间先后顺序排列,如图中的字母A、B、C、D、E、F等表示页面的Url.时间轴存放用户访问某个页面时的时间,如用户1访问页面A的时间为2003-03-01 10:21:36.这样存放对于数据预处理之后的序列模式挖掘很有益。图中的数字“12”表示用户1在一次单独的会话中总共访问了12个页面。这样便于用动态数据立方体存储用户识别和会话识别的结果,为下一步提高模式挖掘的效率和准确性奠定了基础。
USIA算法存在的不足:在判定当前用户和已经识别出的用户是否为同一个访问者的过程中,需要考虑的因素较多,导致算法的运算速度降低。但是考虑到对于Web日志文件的挖掘分析并不是实时的,运算速度并不是首要考虑的因素,因此权衡识别精度和运算速度是值得的。
3 试验结果
以天津大学网站(http://www.tju.edu.cn/)2003-03-01至2003-03-07一周的Web日志文件作为试验的对象。该日志文件共105MB,经数据清理后剩余有效记录为378 747条。
为了对比不同的用户识别方法对用户识别精度的影响,针对数据清理后剩余的378 747条有效记录分别进行了4组试验,每组试验采用不同的识别方法。其中方法4为算法USIA.
方法1:只根据IP地址识别用户,识别出18 706名用户。
方法2:根据IP地址和参考网页识别出19 528名用户。
方法3:根据IP地址、参考网页和Agent识别用户,识别出21 655名用户。
方法4:根据IP地址、参考网页、Agent和网站拓扑结构识别用户,识别出22 173名用户。
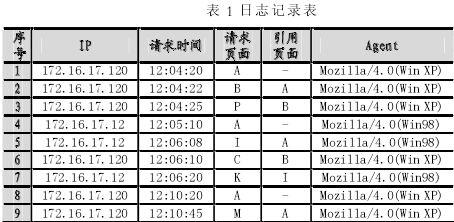
由实验结果可以看出,采用USIA算法共识别出用户22 173名,如果仅用IP地址来识别用户则只能识别出18 706名用户,而会有22173-18706=3467名用户被忽略,可见USIA算法拥有更高的用户识别精度。从营销以及客户服务的角度看,如果这3 467名用户被精确地识别出来,对每个用户实行个性化定制,有可能使其中相当比例的用户转化为网站的忠诚顾客,从而给公司带来更多收益。
4 总结
本文讨论了Web使用挖掘中的数据预处理模块,侧重于预处理的具体实现,提出的USIA算法能够很好地同步识别出用户和会话,比一般的识别算法有更好的识别精度。目前国外针对Web使用挖掘的研究有很多,国内也有一些院校及研究机构在进行这方面的研究工作,但是有影响的并不多。考虑到Web使用挖掘所具有的极大的商业价值和广阔的应用前景以及相关技术还具有很大的提升空间。
Web挖掘是一个有着巨大发展前景的研究领域。Web使用挖掘能够从Web服务器日志中抽取用户感兴趣的潜在的有用模式和隐藏的信息,优化站点结构,以使得教育资源合理配置,并能根据用户的个性特征主动推送感兴趣内容,提高个性化水平。因此将会有更多的研究力量投入到这个领域,研究的重点将会在继续关注模式发现的基础上更多地趋向于模式分析、分析结果的可视化以及人机交互等方面。
-
嵌入式系统发展前景?2024-02-22 0
-
RISC-V在服务器方面应用与发展前景2024-04-28 0
-
数据挖掘在电子商务推荐系统中的应用研究2010-04-24 0
-
网络电话的发展前景?2012-07-05 0
-
嵌入式发展前景2012-08-20 0
-
labview的发展前景2012-11-18 0
-
STATCOM发展前景怎么样啊?2013-05-12 0
-
计算机数字图像图像处理技术的发展前景2013-09-24 0
-
ARM的发展前景怎么样2013-11-20 0
-
DSP的发展前景怎么样2013-11-20 0
-
无线电发展前景怎样2014-09-13 0
-
嵌入式人才发展前景2019-01-21 0
-
嵌入式的发展前景2021-01-13 0
-
车载设备GPS的发展前景如何?2021-05-13 0
-
嵌入式工程师的薪资和发展前景2022-08-31 0
全部0条评论

快来发表一下你的评论吧 !
