

通过Viterbi译码算法实现译码器优化实现方案
描述
1 引 言
由于卷积码优良的性能,被广泛应用于深空通信、卫星通信和2G、3G移动通信中。卷积码有三种译码方法:门限译码、概率译码和Viterbi算法,其中Viterbi算法是一种基于网格图的最大似然译码算法,是卷积码的最佳译码方式,具有效率高、速度快等优点。从工程应用角度看,对Viterbi译码器的性能*价指标主要有译码速度、处理时延和资源占用等。本文通过对Viterbi译码算法及卷积码编码网格图特点的分析,提出一种在FPGA设计中,采用全并行结构、判决信息比特与路径信息向量同步存储以及路径度量最小量化的译码器优化实现方案。测试和试验结果表明,该方案与传统的译码算法相比,具有更高的速度、更低的时延和更简单的结构。
2 卷积编码网格图特点
图1所示为卷积编码网格图结构,图中每一状态有两条输入支路和两条输出支路。
2.1 输入支路的特点
任意一个状态节点Si都有两条输入支路,且这两条输入支路对应的源节点分别为:
此外,i为偶数时,两条输入支路的输入信息都为‘1’;i为奇数时,两条输入支路的输入信息都为‘0’。
2.2 输出支路的特点
任意一个状态节点Si都有两条输出支路,且两条输出支路对应的目的节点分别为:
此外,目的节点是Sj1的输出支路对应的输入信息都为‘0’;目的节点是Sj2的输出支路对应的输入信息都为‘1’。
3 Viterbi译码器的优化算法
3.1 判决信息比特与路径信息向量同步存储算法
由网格图的输入支路特点分析可知,产生任意一个状态节点Si的输入条件mi是确定的,即mi=‘1’,i为偶数;mi=‘0’,i为奇数。输入条件mi表示译码器最终需要输出的比特信息。此外,译码器所要找的留选路径是不同状态的组合。对于(2,1,6)卷积码而言,具有2m=26=64(m为编码存储)个不同状态,可以用6位比特向量来表示所有的状态。将mi作为最高位加在状态向量上,用7位比特向量同时表示每一状态和对应的输入支路的译码信息,这样在译码器回溯时就可以直接输出存储向量的高位作为译码器的输出。采用这种方法大大降低了回溯路径和译码器判决的难度,由此降低了译码器结构的复杂性。
3.2 全并行结构设计
全并行结构Viterbi译码器的特点是所有状态的路径度量计算或路径存储同时进行。其中,路径度量包括两条输出支路和两条输入支路的度量,路径存储包括状态向量存储和译码比特信息存储。因此,在(2,1,6)卷积码的全并行译码器的FPGA设计中,一个时钟周期内需要实现2×n×2m=256次路径度量运算和2m=64次7比特向量存储操作。
全并行结构对每一个状态都具有独立的处理单元,互不影响,同时工作,比起传统的串行结构,大大提高了译码速度。并且由于在FPGA中,有着海量的独立逻辑单元(LCs)和丰富的分布式存储资源(RAM),全并行结构设计正好可以发挥FPGA的这一优势。
3.3 路径度量的最小量化算法
随着网格图的行进,每个状态输出支路的路径度量会不断增加,度量值所需量化位宽越来越大,导致存储资源的增加。为了降低路径度量存储单元的大小,节约存储资源,设计中采用了路径度量的最小量化算法。在每次路径度量运算时,将各状态的度量值减去上一次各状态留选路径度量值的最小值。即需要保存的路径度量值只是各状态度量与最小度量的差值,从而达到减少度量值量化的位宽。
对于(2,1,m)卷积码,每次计算出的路径度量最大值与最小值之差不超过2×m,所以,路径度量的量化宽度为log2(2m)。对于(2,1,6)卷积码,存储路径度量的寄存器位宽为log2(2×6)=4。
4 FPGA实现及验证
4.1 FPGA实现的整体框架
采用Altera公司的QuartusⅡ为开发工具,以EPlS25的FPGA为验证平台,用于设计和验证本文提出的Viterbi优化译码算法,译码器整体设计框架如图2所示。译码器结构主要包括时钟单元、主控单元、全并行ACS单元、回溯单元及译码输出单元。
(1)时钟单元
用于把板级时钟经过锁相环分频获得译码器所需的工作时钟。
(2)主控单元
给出各种控制信号,控制其他各单元的工作时序,保证译码器各模块协调工作。
(3)支路度量与全并行ACS单元
由64个具有相同结构和功能的支路度量与全并行ACS构成,用于计算和比较每条支路的度量,选出并保存度量值最小的路径供回溯单元使用,存储路径包括表示状态的6位信息向量和对应的译码信息比特mi。由于(2,1,6)卷积码的译码深度D=5(m+1)=35,为保证存储单元写操作与回溯单元读操作同步进行,将存储单元分为两个部分做流水线处理,因此存储单元大小应有2×D×(m+1)×2m=31 360 b。
(4)回溯单元
用于在译码深度到达时刻,根据各状态ACS单元选出的留选路径,判断度量最小的留选路径,并从这条路径对应的状态开始向前寻找,直到找完前面所有状态,同时把从存储单元中读出的译码信息比特mi送给译码输出单元。
(5)译码输出单元
将回溯单元送出的反序译码信息按正序输出,用RAM实现。即先将比特信息按顺序写入RAM,待一段信息写完后再按反序读出。为了保证本段反序读操作与下一段顺序写操作同时进行,将RAM分为两部分做流水线处理。每段信息流的长度为译码深度,因此流水线RAM的大小为2×D=70 b。
4.2 设计验证
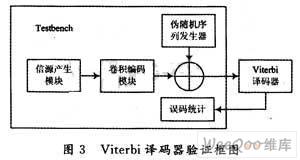
为了验证本文提出的Viterbi优化译码算法,编写了图3所示的验证框图。包括一个信源产生模块、一个卷积码编码模块、一个伪随机序列发生模块以及误码统计模块。在编码器输出中加上伪随机序列模拟的噪声构成有扰译码输入信息,用于验证译码器的纠错性能。
通过QuartusⅡ软件内嵌的signalTap及JTAG下载线在EPlS25的FPGA上的在线测试,得到时序图如图4所示。
图中,信号量BER是误码统计模块统计的误码数,在Viterbi译码能力范围内,其值始终为0,这就验证了译码器的译码功能。通过测试与比较性能指标得到以下结果:
(1)译码器速度
通过在FPGA开发板中的实际运行,译码器输出的比特速率可达90 Mb/s。这与QuartusⅡ提供的Viterbi译码器IP核的parallel结构相当,而比其hybrid结构的译码速度快十几倍。
(2)译码器时延
本方案的译码器时延大小主要取决于译码深度D。(2,1,6)卷积码的译码深度为D=35,回溯单元处理时间和D相同;同时,回溯前最小度量的判断时间为(m-1),所以从译码输入到译码输出的总延时为2×D+(m-1)=75,这比起采用QuartusⅡ提供的Viterbi译码器IP核(延时为170)缩短了一半以上。
(3)译码器资源
QuartusⅡ软件的资源分析综合报告如图5所示,主要消耗的资源为LEs:2 339,占整个芯片逻辑资源的9%;RAM:31 430,占整个芯片RAM资源的2%。因此,本方案对资源的需求是很少的。这与QuartusⅡ提供的3.2版本的Viterbi译码器IP核相当,而比4.2版本的Viterbi节省1 000多个逻辑资源。
5 结 语
通过对Viterbi译码算法及卷积码编码网格图特点的深入分析,提出一种采用全并行结构、判决信息比特与路径信息向量同步存储以及路径度量最小量化算法的译码器优化实现方案。测试和试验结果表明,在不降低译码器性能的前提下,能提高译码速度、降低译码器的资源消耗和时延、简化译码器结构。
-
什么是硬判决和软判决Viterbi 译码算法 ?2008-05-30 0
-
应用于LTE-OFDM系统的Viterbi译码在FPGA中的实现2009-09-19 0
-
基于IP核的Viterbi译码器实现2010-04-26 0
-
基于FPGA的Viterbi译码器算法该怎么优化?2019-11-01 0
-
基于FPGA的Viterbi译码器该怎样去设计?2021-05-07 0
-
基带芯片中Viterbi译码器的研究与实现2009-08-13 774
-
从FPGA实现的角度对大约束度Viterbi译码器中路径存储2007-08-15 888
-
Viterbi译码原理2009-11-13 7420
-
Viterbi译码器的低功耗设计2011-05-16 701
-
Viterbi译码器回溯算法实现2011-05-28 934
-
通信系统中Viterbi译码的Matlab仿真与实现2012-03-22 905
-
基于ASIC的高速Viterbi译码器设计2017-11-11 806
-
译码器如何实现扩展2017-11-23 33479
-
通过采用FPGA器件设计一个Viterbi译码器2019-04-24 2680
-
采用可编程逻辑器件的译码器优化实现方案2020-08-11 772
全部0条评论

快来发表一下你的评论吧 !
