

GAN原理及其在半监督学习中的意义
电子说
描述
编者按:《GANs in Action》作者Jakub Langr简述了对抗生成网络原理及其在半监督学习中的意义。
在许多研究人员和我的朋友看来,对抗生成学习/网络(Generative Adverserial Learning/Networks,GANs)很可能是AI的未来发展方向之一。GAN在商业上有很清晰的吸引力:可以基于较少的数据训练,可以创建迷人的应用(例如3D模型生成),有大量研究潜力。
本文包括一定的技术内容,也有一些高层的伪代码,但我将尽力让这篇文章容易理解,也希望这篇文章不会太枯燥。
你想挤上AI这趟车吗?
GAN这一切都是最前沿的内容,本文提到的一些内容甚至是一两年前刚在学术期刊上发布的内容。所以,除非你是这方面的博后,初次接触GAN可能会让你觉得不同寻常(至少对我来说是这样的)。同时这也意味着其中有一些研究没有对应的理论,你需要应对一些超奇怪的bug. 不过因为我最近完成了(好吧,我真的很喜欢上MOOC)Parag Mital开设的非常棒的Creative Applications of Deep Learning with TensorFlow(基于TensorFlow的深度学习创意应用)课程,我决定分享一些我学到的东西。
半监督学习大致上指在训练中同时使用标注过的(监督)和未标注过的(无监督)样本,这是一个比较老的概念了。它的核心思想意义很大:在典型的监督设定下,我们有大量没有使用的数据。例如,在房价(标注)数据上的线性回归。我们都明白线性回归可以生成房价,但大多数房子没有出售,然而我们也许仍然能取得相关数据,比如从城市规划数据中获取。这些数据可以给我们提供更多的信息,例如对比不同区域,哪里的房子相对而言供不应求,哪里大面积的房子更多。不以某种形式利用这些数据很蠢,但传统的算法没法使用它们。
因此,半监督学习(SSL)意味着使用不同技术以某种方式在机器学习(ML)模型的训练中添加这些数据。这并非微不足道:如果把训练ML想象出创建一棵决策树,接着通过检查是否得出正确答案评估决策树的表现。那么,很不幸,在未标注数据上,没有正确答案(因为在数据收集期间房子未曾出售),所以没法进行学习,因为ML算法无法连接正确答案(因此无法计算损失)。在这篇文章中,我希望集中讨论其中一种称为对抗生成网络的SSL技术。
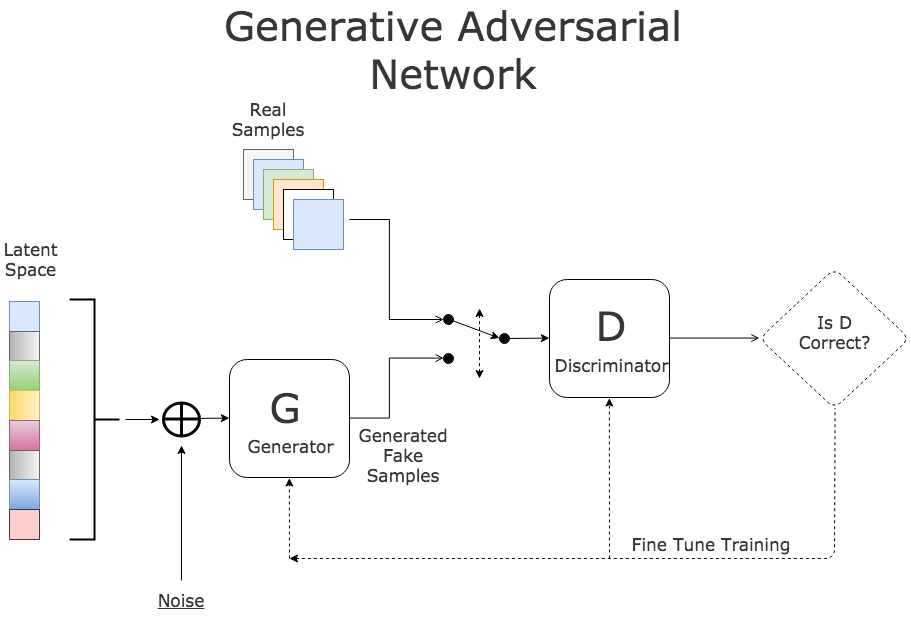
GAN有两个网络组成。第一个网络创建世界的内在版本(即通常房子是什么样的):这称为生成模型(G),基本上它基于一切数据学习,因为它不需要标签,只需要数据集中典型房屋的所有特征。第二个网络,称为判别器(D),和G对抗,同时从真实数据集和生成器生成的房屋样本中取样,决定数据看起来是不是真的。
换句话说,想象我们正在尝试标注猫或狗,在这一情形下,G将学习如何生成图像,并逐渐使生成的图像越来越像猫或狗。
接着,我们大致上让G和D互相竞争,以产生最好的结果:我们希望每次G变得更好时,D也能变得更好,相互匹配(我们需要确保G或D没有胜出对方太多)。这也正是驱动AlphaGo的核心原则之一。基本上,我们让G生成图像,让D对此加以评判。所以G会传递一组图像给D,而D会输出0或1(代表真假)并传回G。接着G会根据哪些图像骗过了D、哪些没骗过而努力生成更好的样本。
来源:KDNuggets.com
所以我希望你明白了上面的过程,我们可以基于大量未标注数据构建一个生成器,并让它学习数据的某些结构(即,典型样本看起来是什么样的),接着让它在竞争中使生成数据尽可能接近真实数据。经过这一过程,我们可能得到一些看起来相当不错的合成数据,这些合成数据的数量几乎是无限的。另外,我想指出(省略大量说明):生成器只能生成和之前见过的数据相似的数据。人们很容易忘记这点,没有魔法。
请会拉丁语的同学谅解 ;-)
从最高层的抽象看,这一切大概是这样的:
# 获取数据
real_data = pd.read('real_data.csv') # 形状 (n样本, n特征加标签)
unlabelled_data = pd.read('unlabelled_data.csv') # 形状 (n样本, n特征)
# 创建两个对象
generator = GeneratorClass()
discriminator = DiscriminatorClass()
# 预训练生成器
generator.train(unlabelled_data)
# 获取合成数据
synthetic_data = make_compete(generator, discriminator, real_data)
# 形状 (任意数量, n特征)
好吧,细心的读者可能会注意到我们没有描述如何标记生成样本。理想情况下,我们想要生成标注数据(例如,附带价格的房屋,或者附带物体描述的图像)。感谢大量的训练实例,我们有办法做到这点。如果你回头看看之前的示意图,你会看到其中提到了称为“潜空间”的东西。潜空间是一种控制生成什么样的图像的方法。如果我们训练猫狗生成器,其中一个维度将控制图像有多像猫/狗。它也允许我们获取两者之间的中间值,所以我们可以得到狗猫或者七分猫三分狗。换句话说,潜空间可以看成某种种子因素——为G提供一些初始输入免得它总是生成一样的东西,但是事实上这一种子因素具备一致的潜(“隐藏”)性质,特定的维度对应某种意义的。
简单修改上面的伪代码,以清楚地表明这一点:
# 形状 (任意数量, n特征)
synthetic_cats = make_compete(generator, discriminator,
real_data, input_noise=latent_feature_space.cat)
# 形状 (任意数量, n特征)
synthetic_dogs = make_compete(generator, discriminator,
real_data, input_noise=latent_feature_space.dog)
最棒的地方在于,理论上,我们甚至不需要有为当前任务标注的数据就可以生成相应样本(不过有标注数据会有很大帮助)。例如,我们可能有打上了好孩子和坏孩子的数据,然后我们可以训练G生成猫或狗的新样本(根据潜空间的一个参数决定是猫是狗),其中既有好孩子,也有坏孩子(基于潜空间的另一个参数决定)。比方说,我们可以基于图像判断狗的好坏(例如,如果我们看到狗破坏财物就标记为坏孩子,否则就标记为好孩子)。那么我们就可以在潜空间中发现对应这些特征的参数,然后通过插值生成猫狗或者狗猫。
再举一个例子,我们可以下载大量未标注的名人面部图像,然后让G生成面部,并通过操作潜空间得到明确的雄性样本或雌性样本,接着据此训练另一个识别雄性或雌性图像的分类器(无需标注过的数据!)这正是我曾经做过的项目。你可能想要知道“我们如何得到不同属性的潜空间表示?”很不幸,这个问题的答案超出了本文的范围。
唷,时候不早了:我希望给出一些可以实际运行的代码,这样读者可以自行试验。不过,我觉得这篇博客文章已经够长了,所以,对实际代码感兴趣的读者,请访问我的另一篇博客文章:http://jakublangr.com/gans-code.html
想要加入对话?欢迎在jakublangr.com上评论,或者发推给我(langrjakub)。我正在撰写一本关于对抗生成网络的书,这里有一些样章:www.manning.com/books/gans-in-action
-
深非监督学习-Hierarchical clustering 层次聚类python的实现2020-04-28 0
-
如何用卷积神经网络方法去解决机器监督学习下面的分类问题?2021-06-16 0
-
基于半监督学习的跌倒检测系统设计_李仲年2017-03-19 765
-
基于半监督学习框架的识别算法2018-01-21 722
-
英伟达通过利用GAN及无监督学习,实现了场景间的四季转换2018-05-16 2416
-
你想要的机器学习课程笔记在这:主要讨论监督学习和无监督学习2018-12-03 420
-
如何用Python进行无监督学习2019-01-21 3959
-
机器学习算法中有监督和无监督学习的区别2020-07-07 5373
-
最基础的半监督学习2020-11-02 2382
-
半监督学习最基础的3个概念2020-11-02 2682
-
为什么半监督学习是机器学习的未来?2020-11-27 3648
-
半监督学习:比监督学习做的更好2020-12-08 1140
-
基于人工智能的自监督学习详解2021-03-30 5639
-
机器学习中的无监督学习应用在哪些领域2022-01-20 4597
-
自监督学习的一些思考2022-01-26 290
全部0条评论

快来发表一下你的评论吧 !
