

自制Word2Vec图书推荐系统,帮你找到最想看的书!
电子说
描述
最近有开发者自制了一套图书推荐系统,使用Word2Vec算法将书目表示为向量,可以同时获得几种书籍的推荐结果,并获得书籍的TSNE图及相似度最高的推荐。图书数据来自GoodReads上的评价最高的前10000本书。开发者表示,采用较小的batch size和长度可变的窗口可提升推荐相似度。
近日,有开发人员自制了一套图书推荐系统,使用Word2Vec算法将书目表示为向量,可以同时获得几种书籍的推荐,并获得书籍的TSNE图以及相似度最高的推荐信息。训练数据来自GoodReads上的评价最高的前10000本书。
作者将这一系统在Reddit论坛上进行了算法介绍和推荐效果图分享,引发广泛讨论。我们不妨来看看这个自制荐书系统是怎么做的。
以下是作者自己给出的系统展示和介绍,最后是技术实现环节的相关讨论。
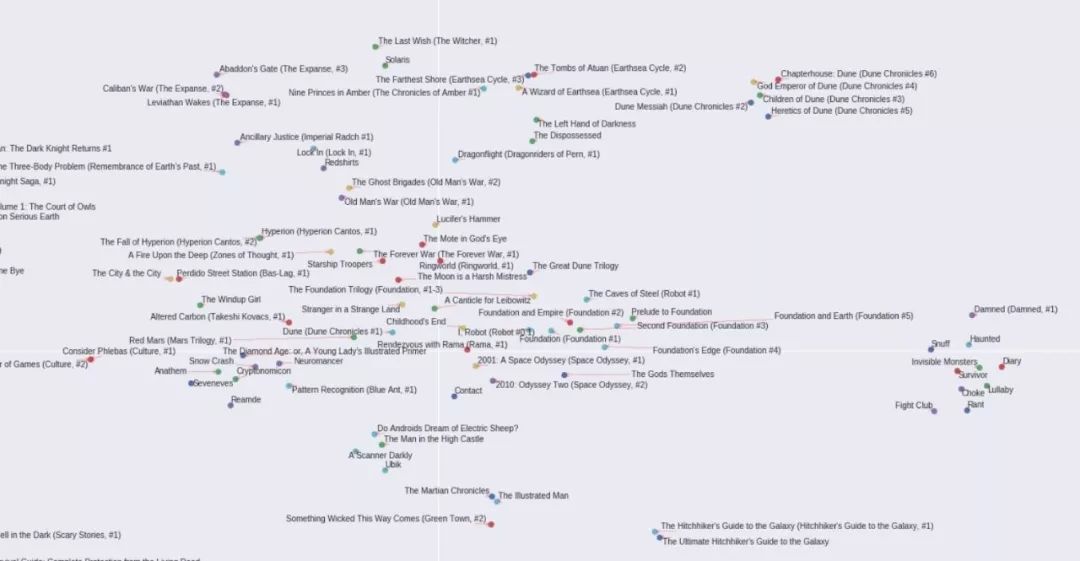
下面的图片来自两个2D TSNE生成的图书嵌入图。第一部分是数据中最常出现的3000本书的TNSE(已经过10000本书的数据训练),第二部分是全部10000本书的TSNE。
我做了两个TSNE图,因为随着书籍书目的增加,推荐的准确度趋于下降,所以我想查看最常出现的书籍的分布图,然后再处理其余的书。
首先最常出现的3000本书的TSNE图,先给出几个局部放大图,最后放上全图。
下图为作于最近30-40年间的奇幻/古典奇幻类书

中间的部分大部分是漫画书,周围是一些科学类书籍

宇宙科幻类:
喜剧类(主要是电视剧)

全图

然后是全部10000本书的TSNE图,同样先给出几个局部图,最后是全图。
历史类书籍。图左半部为美国史,右半部为世界通史

宇宙史和起源理论

儿童经典书目

食品科学和新闻类

Word2Vec荐书系统的技术实现
下面是一些技术上的实现要点,对机器学习感兴趣的小伙伴们可以关注一下。
1、使用较小的batch size
训练中使用batch size较小(32和64)对于确保所有书籍向量的稳健性非常重要。在更高的batch size(128、256和512)下,大多数向量具有相当的相似性,但似乎总是有一些书的向量不具备相似性。
以《哈利·波特》2-7部的推荐结果为例,如果直接查看数据,很容易知道与这些书相似度最高的书应该是该系列中的其他《哈利·波特》书,但最初推荐模型给出的相似图书结果并非如此。但是,在把batch size设置为64后,推荐结果的相似度很快得到明显改善。
由于平均窗口大小为112,并在20到200之间变化(取决于用户阅读的书籍数量),因此像《哈利·波特》这样的系列丛书中的一些书,很可能会与其他书籍匹配为相似了。
假设某系列丛书中共有7本书,并且用户对所有7本书都进行了评分,该用户还评价了112本其他书,那么,其中一本《哈利·波特》书与另一本《哈利·波特》在该用户的标签下实现配对的概率是6/112。
在这种情况下,由于word2vec试图一次性优化多个嵌入,因此对于窗口大小很小且恒定的情况,更高的batch size会比word2vec算法的应用对结果优化造成更加明显的阻碍。
2、Softmax嵌入向量算术
到目前为止,上面的所有矢量算术示例都是我在书籍输入嵌入上执行加法和/或减法,然后针对softmax嵌入对结果矢量执行相似性结果的情况。比结果向量与输入嵌入进行比较要稳健得多。
3、可变长度窗口(VLW)
最初的Word2Vec Cbow算法使用固定的窗口大小的单词用作特定目标的输入。比如,如果窗口大小是目标词左侧和右侧的2个单词,那么在这句“The cat in the hat”中,如果目标词(标签)是“in”,那么单词'The ','cat','the'和'hat'将各自向量进行平均,并将得到的结果向量作为输入。
而在这个荐书系统中,窗口大小不可能是固定的。对于特定数据点(输入),由用户输入的所有对全部书籍的评价都可能作为潜在的输入,而且每个用户浏览过的书籍数量彼此存在很大差异,因此窗口大小不可能恒定。
尽管窗口大小不是恒定的,但是平均输入向量的数量是保持不变的。所有提供的数据都使用两个平均向量作为输入,这样向量的算术属性的稳健性是最高的。改变输入平均向量的数量,在相似性推荐属性方面并没有表现出明显优势。
-
浅析word2vec的安装和使用方法2018-12-25 0
-
Gensim的word2vec说明是什么2020-04-26 0
-
word2vec之嵌入空间2020-05-08 0
-
Word2Vec学习笔记2020-07-17 0
-
word2vec使用说明资料分享2021-07-02 0
-
word2vector如何使用2021-07-02 0
-
请问word2vec怎么使用?2021-09-23 0
-
如何对2013年的Word2Vec算法进行增强2022-11-04 0
-
如何使用Word2vec模型进行古诗词个性化推荐的应用2018-11-15 883
-
基于单词贡献度和Word2Vec词向量的文档表示方法2021-04-29 584
-
你们了解Word2vec吗?读者一篇就够了2021-06-23 1588
-
PyTorch教程15.4之预训练word2vec2023-06-05 123
-
PyTorch教程-15.4. 预训练word2vec2023-06-05 201
-
论文遭首届ICLR拒稿、代码被过度优化,word2vec作者Tomas Mikolov分享背后的故事2023-12-18 368
全部0条评论

快来发表一下你的评论吧 !
