

硅谷首场AI硬件峰会干货报告:AI芯片井喷期即将到来
描述
(本文来自智东西微信号,本文作为转载分享)
所有的云计算商都在开发内部的芯片,AI芯片不仅是未来十年半导体行业中最有希望的增长机会之一,而且还是有可能破坏传统计算市场的力量。现今 99%的AI软件尚未编写,只有不到1%的云服务器用于AI加速(今年总计500+万台服务器),企业服务器活动几乎为零。训练和推理工作从低基数中倍增,说明市场似乎是一致的,因为今天的加速硬件(GPU、CPU、FPGA)远远不能满足市场的要求。
吞吐量上还需要巨大的飞跃(现今100倍)才能使AI无处不在。好消息是真正的架构创新即将出现,但需要时间才能生效:2019年以后,我们将看到新的工艺技术(7nm)、新的计算架构(芯片上的神经网络)、新的芯片互连(serdes 56/112GBs)、新的存储器方法(HBM3、片上SRAM等)和新的封装技术相结合,可带来对数级性能的提升。因为不能太依赖工艺的缩减而进步,AI行业正在进行全面的创新。但长远来看,台积电等主要DRAM制造商还是AI芯片产业的主要受益者。
本期的智能内参,我们推荐来自Arete的研究报告,详解AI硬件峰会对未来的预测,2大科技巨头及创业公司的AI芯片布局。
AI硬件峰会的5大结论
上个月加州山景城举办的AI硬件峰会是目前唯一专门致力于开发用于神经网络和计算机视觉硬件加速器生态系统的活动。 会上,来自AI芯片初创企业、半导体公司、系统供应商/ OEM、数据中心、企业、金融服务、投资者和基金经理等 250 多位先进技术领导者们,为新兴的AI芯片市场构建了一幅全面的架构路线图。
会上展示了 许多AI芯片中另类创业者的状态。其中有一件事是非常明确的:从未见过如此多的公司(无论大小)进攻这个新兴芯片市场。就像今天的AI一样,毫无疑问在接下来的几年中,将会出现一个成果井喷期。继谷歌的TPU之后,每个创业者都有正在研发的内部AI芯片程序。问题是这一切需要多长时间才能影响到市场情绪?毕竟,谷歌的TPU芯片已经到了第三代(在16年中期推出其第一个TPU之后),但仍然承载不了Tensorflow或其他框架的所有工作量。所以我们认为,2020年是许多AI芯片问世和量产的开始。
AI硬件峰会的5个重要结论:
1、台积电中几乎所有的AI加速芯片都使用了7nm工艺。此外,我们还发现大量新的高速接口芯片(Serdes 56/112GBs)将在19年扩展。
2、英伟达仍然是机器学习之王,其新的T4卡将会被广泛接受。它将在19年继续占据主导地位。但长远来看,我们仍然担心AI会减少对CUDA和GPU的依赖。
3、英特尔有新的7nm AI芯片(由台积电制造),我们认为这个芯片支持112GB的Serdes和高速DRAM。它还应该在明年的Cascade Lake服务器中支持新的DL Boost INT8,并且速度增强11倍。
4、所有的云计算商都在开发内部的芯片,但问题是时机的选择,因为计划的增加是私密的。这种垂直推进是芯片制造商面临的主要威胁。
5、在最近的5年,我们见证了新的纳米线取代了数字计算的模拟计算机的进步;硅光子学取代了Serdes(超过112 GB)和更高速内存驱动AI的性能提升。
新的AI芯片有两种通用思路:
1、首先是拥有更快的I/O和外部存储器接口的能够扩展性能的系统,如英伟达,英特尔等。
2、其次是将所有数据存储在芯片上(芯片上的神经网络),使用大量的小内核和片上存储器来减少对外部DRAM的需求。
后一种方法将在未来六个月内会看到第一批商品化的芯片,但我们认为这需要7纳米工艺真正推动家用优势的时候(即2020年)。围绕AI的软件也在快速发展,云服务商也正在推出开源适配软件,以支持在其框架中运行的各种芯片(例如,Tensorflow XLA、Facebook Glow)。随着新神经网络的成熟,每个人都意识到了可编程性和灵活性的重要性。隐含的目标是在7nm的FP16上达到每瓦特至少10 TOPS(比现在好10倍),并且通过更好地支持稀疏性,更低的精度、更小的批量、更快的芯片互连(112GB Serdes)、更快的存储器接口(远远超出HBM2)以及新的多芯片高级封装真正提高效率和性能。
英特尔:AI芯片扮装者
尽管人们普遍转向依赖通用CPU,但对于英特尔计划在未来几年内为AI引入的一些新优化措施,大家并未给予足够的信任。英特尔去年的AI收入大约为10亿美元(2017年),至强CPU将继续在AI推理和训练中发挥重要作用。例如,在Cascade Lake中,英特尔在架构中提供了大量新指令,以提高推理性能(声称在支持INT8精度的情况下性能提升11倍)。我们预计这些扩展将与AMD EPYC2规格区别开来。
英特尔的下一代Nervana ASIC芯片将在台积电(7nm工艺)制造,并将拥有一些关键的专有接口,可显着提升性能。虽然GPU现在以低速(PCIE-3)连接到CPU,预计新服务器将支持PCIE-4(16GB),但这仍然是数据输入GPU的关键瓶颈。相比之下,英特尔或将在其Xeon CPU和7nm Nervana芯片之间构建专有接口,速度高达112GB。英特尔可能计划推出一种新的高带宽存储器接口(对云计算商而言是一个关键的关注点),并积极参与新的多芯片封装。虽然向AI加速的转变将导致更多的CPU被卸载,但英特尔希望通过在Xeon周围构建外围解决方案来获取价值。时间将证明这是否有效,但规格的突破显然揭示了英特尔的目标是在2020年取代英伟达的地位。
英伟达:暂时的旗舰
英伟达的GPU目前仍然是AI计算的王者,他们拥有真正的在位优势(支持所有框架、所有云服务商、所有OEM),并且其新产品具有显着的性能提升,我们认为T4将得到广泛采用并且其新的DGX2服务器今年已售罄。虽然目前几乎没有令人信服的替代方案,而且我们也认为NVIDIA将继续占据主导地位(至少到2019年),但有两个主要问题影响英伟达可以在多大程度上长期维持其领导地位:
1、首先,我们认为很明显英伟达软件壕沟(CUDA)将变得不那么重要,因为像谷歌、ONNX都努力推进了他们的堆栈并建立了开发者生态系统。云服务商现在正在积极提供替代芯片解决方案的开源插件,以支持Tensorflow、Pytorch、CNTK、Caffe2等框架,降低了新AI处理器的入门软件门槛。
2、其次,是英伟达训练和推理芯片的经济性,虽然它们可以为许多AI工作负载节省CPU,但是销售的GPU卡的超高利润率与昂贵的内存捆绑在一起(V100每卡10万美元,P4可能每个2万美元)只会让云端用户拥抱其他架构。
也就是说,英伟达拥有大量资源来投资竞争对手(尤其是初创公司),它致力于每年为AI推出一种新的架构,它可能会在2019年下半年首先推出7nm解决方案。 V100和T4都被视为英伟达首款用于AI的转换芯片(远离通用型GPU),因为它们是第一款支持张量核心和更低推理精度的芯片(INT8)。
预计19年新品的功能将再次大幅提升英伟达7nm AI加速芯片,将会有很多明显的效率改进可以大幅提高吞吐量和延迟。我们预计它的下一代将更多地是以AI为中心的ASIC而不是GPU。云客户告诉我们,他们从V100 GPU获得的利用率很低(低至15%),因为他们每个GPU只训练一个神经网络。他们希望英伟达能够虚拟化他们的GPU ,尽管这可能会给英伟达的GPU增长带来压力,甚至减少对AI计算芯片的需求。此外,今天英伟达拥有快速芯片到芯片接口(NVlink2),运行速度为25Gbs(远远超过标准PCIE-3连接,仅8GB或PCIE-4,16GB),我们预计到19年年底英伟达将推出对56Gbs甚至112GB serdes的支持,因为有些替代方案可以提升这些规格。我们认为英伟达的下一代架构将于2019年下半年发布(超越Volta / Turing),并将在很大程度上决定其在多大程度上可以继续占领市场。
另类AI芯片创业公司的时代到来
在谷歌TPU的带头下,每个云服务商都有内部的AI芯片程序,我们认为这可能会在未来18个月内得到验证。有些已经公开表达他们的意图,微软甚至在峰会上有一个招聘广告,说明它渴望建立自己的团队。但这些项目所处的状态还不清楚:云服务商不会分享任何他们的硬件计划细节 ,所以我们不知道他们处于什么发展阶段。我们认为第一次转换芯片将重点关注推理,就像谷歌两年前对TPU所做的那样。
来自谷歌大脑的演示展示了一种讽刺,即随着芯片行业达到摩尔定律的极限,AI计算的增长竟还能呈指数级增长,因此架构(和软件协同设计)将成为关键的推动者。谷歌不仅将TPU用于越来越多的工作负载,而且继续使用GPU,并将测试大量新系统上市。 50多家创业公司的工作已经缩减,以便将他们的平台商业化,我们预计未来12个月内将有6家公司推出首款加速芯片,2020年开始推出第二款(7nm工艺)。一些AI初创公司在19年可能会达到1亿美元的销售额,但我们还看不到是否有人能在2020年之前突破这一点。有许多令人印象深刻的初创公司,但其中许多还没有流片,因此很难对性能声明进行验证。
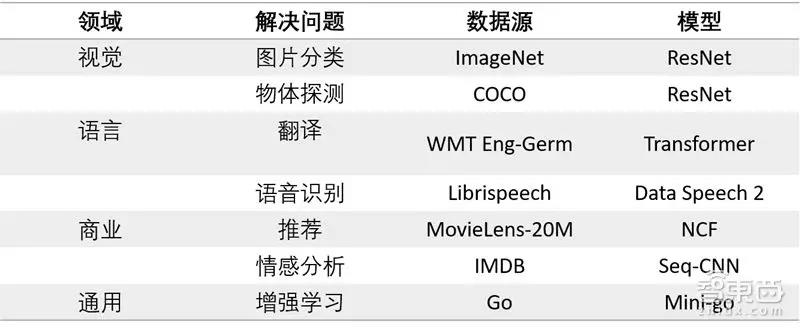
云服务商希望了解新的AI芯片的系统性能,因此他们建立了一个名为MLPerf的基准测试标准。我们认为这将是分析特定模型的训练时间的关键标准 ,并且有助于与当前市场领导者英伟达(尚未加入MLPerf)的训练平台进行比较。很明显,许多初创公司从未提供产品给主要的云数据中心,或者已经建立了领先的芯片。此外,只有少数参与者具有详细的云计算关系或在如何围绕关键型任务云计算芯片建立工程团队方面拥有丰富经验。
云加速:巨大的市场机会
今天看一下现在典型的云服务器配置(2插槽,10核Xeon E5是最受欢迎的销售平台之一),它包含大约660平方毫米的硅芯片面积来处理主CPU计算(即两个330平方毫米的CPU芯片,主要由英特尔提供)。但是用于AI的加速服务器(例如NVIDIA DGX-1)通常具有多达10倍的硅面积来处理加速度计算,如下图所示。加速芯片面积与CPU芯片面积的比率仅会增加我们看到每个CPU从四个加速卡上升到每个CPU的六个和八个卡随着时间的推移。我们认为谷歌计划明年增加三倍的TPU芯片。
英伟达在训练方面可能会继续大幅增长,同时还有大量的AI创业公司。由于AI服务器目前在市场上的渗透率很低(今年购买的云服务器不到1%支持加速),台积电的长期前景非常好。如果我们假设这种渗透率上升到100万台加速AI服务器(今年小于5万),并且芯片面积保持不变(即每个AI服务器6,560平方毫米),这将转化为大约每年20万片晶圆,或30亿美元的代工收入(假设每片晶15,000美元,收益率55%)。这就是为什么台积电会作为AI芯片长期的主要受益者之一。
长远的新技术
峰会期间还有许多其他新兴技术,未来在3到5年的视野中看起来很有趣。AI的边缘计算显然正在智能手机中进行,我们坚信每部智能手机都将在未来2-3年内拥有专用的计算机视觉AI处理器(在相机周围)。谷歌的Edge TPU和英伟达的DLA是早期可授权的例子,我们看到ARM现在提供专用的AI许可证解决方案,而Qualcomm、Hisilicon、Cambricon和MediaTek则提供一系列智能手机和物联网解决方案。一系列具有增强AI规格的嵌入式SOC即将推出 ,适用于相机、机器人、汽车等。英伟达的Xavier就是一个例子。我们将在即将发布的报告中研究自动驾驶汽车的汽车路线图,其中AI加速将发挥核心作用。
从长远来看,我们可以看到正在开发的一些扩展计算性能新技术,以应对摩尔定律的挑战。其中一个更令人印象深刻的演讲是来自Rain Neuromorphics和Mythic,他们看到模拟计算在5年的时间内商业化可能,使用松散的几何形状,围绕芯片内部的纳米线(如人脑中的突触)解决功率限制。此外,Ayar Labs阐述了硅光子微型化方面的突破引起的更快的芯片互连(超过112GB Serdes)的解决方案。随着Exascale计算机预计将在3-4年内出现在我们面前,我们认为AI正在全面推动新思路研发,将实现性能的指数增长。
我们认为,随着摩尔定律的终结,AI的发展不能指望摩尔定律带来的性能提升,尤其是AI芯片的发展。英伟达虽然目前处于行业领先地位,但很有可能被英特尔或新的创业公司超越。不远的未来AI芯片将是一个井喷的行业,而这个行业最大的受益者将是台积电。希望内地的相关企业也能在这一波浪潮中抓住机遇,改变我国缺芯的局面。
-
物理网时代即将到来了2014-07-23 0
-
即将到来的AI时代,谁将笑傲江湖2018-03-29 0
-
一张图读懂“云栖大会·武汉峰会”发布的阿里云AI产品体系2018-06-12 0
-
AI芯片怎么分类?2019-08-13 0
-
【免费直播】AI芯片专家陈小柏博士,带你解析AI算法及其芯片操作系统。2019-11-07 0
-
【免费直播】让AI芯片拥有最强大脑—AI芯片的操作系统设计介绍.2019-11-07 0
-
【HarmonyOS HiSpark AI Camera试用连载 】第一篇:开箱报告2020-11-20 0
-
清华出品:最易懂的AI芯片报告!人才技术趋势都在这里 精选资料分享2021-07-23 0
-
中国开源未来发展峰会“问道 AI 分论坛”即将开幕!2023-05-09 0
-
大陆AI芯片新创公司融资井喷2017-11-24 602
-
AI的时代即将到来,未来三至五年将迎“AI+医疗”的春天2018-07-24 1653
-
华为加速其在AI领域的布局 安防行业新一轮的洗牌即将到来2019-01-14 860
-
从云、网络到边缘和PC 英特尔的AI大时代即将到来2020-01-17 359
-
AI芯片“点燃”北京!GTIC 2020 AI芯片创新峰会大咖演讲全干货2020-12-03 1165
-
人类智慧水平AI即将到来,AI芯片已提前布局2024-01-22 2169
全部0条评论

快来发表一下你的评论吧 !
