

AI系统存在巨大缺陷 看图识物比不上人类幼儿
电子说
描述
人类,1分;AI,0分。
上个月,来自约克大学和多伦多大学的两名研究人员合作发表了一篇论文:The Elephant in the Room,在学界引起巨大反响。通过实验,他们发现现有人工智能系统还存在巨大缺陷,它们在“看图识物”这类视觉任务上的表现甚至还比不上人类幼儿。
看罢这篇论文,加里·马库斯表达了对研究人员的赞许:“这是一篇聪明而重要的论文,它提醒我们所谓的‘深度学习’还没有那么‘深刻’。”他是纽约大学的认知心理学教授,也是优步(Uber)人工智能实验室的负责人。
这项成果出现在计算机视觉领域,论文设计的任务很常规:训练一个机器学习系统,让它学会检测和分类图像中的对象。随着自动驾驶汽车离真正落地越来越近,学界对机器的视觉处理技术一直寄予厚望。为了保障安全,计算机必须能从一幅街景图中准确分辨哪个是鸟,哪个是自行车,即便达不到超人水平,它们至少也应该和被替代的人眼一样好用。
但是,这个任务并不简单,它突出了人类视觉的复杂性——以及构建模仿系统的高难度。在这项研究中,研究人员首先展示了一个能检测、识别客厅场景下物品的计算机视觉系统,它的性能很不错,能发现客厅里有一把椅子、一个人和书架上的书。之后,他们在同一幅图中加入了一个异常物体——一只大象,这时系统却“指鹿为马”了,它开始把椅子称为沙发,把大象称为椅子,还忽视了之前能“看”到的其他物品。
对此,论文作者之一Amir Rosenfeld认为:“这些奇怪现象的出现,表明了目前的物体检测系统是多么脆弱。”他们没能在论文中解释为什么会出现这种脆弱,但提出了一个破有见地的猜想:
这和人类具备,而AI没有的一项能力有关——人类在看图识物时能理解图像中是否存在令人困惑的东西,从而让自己去看第二眼。
房间里的大象
人类视觉和机器视觉很不一样。
当我们睁开双眼时,眼球开始收集大量视觉信息,并把它们输送给大脑快速处理,这时我们知道天是蓝的,草是绿的,万物在不断生长。
相比之下,机器在生成“视觉”上更费力。它们看待事物的方式类似用盲文阅读,其中图像的像素就是“文字”,通过在像素上运行各类算法,机器最终能生成关于目标物体的越来越复杂的表达形式。运行这一复杂过程的系统是神经网络,它由许多“层”构成。
输入一幅图像后,神经网络会逐层提取图像中的细节,比如各个像素的颜色和亮度,层数越深,它提取到的特征就越抽象。在过程结束时,它会对根据这些特征对其正在观察的内容输出最佳预测。
这个过程意味着相比人类,神经网络能把握更多人眼难辨的细节。事实上,现在基于神经网络的系统已经在许多视觉处理任务上超越人类,比如依据品种对狗进行分类。这些成功应用提高了人们对技术的期待,研究人员也开始着手研究,看计算机视觉系统是否能帮助汽车快速通过拥挤的街道。
但是,这项技术的成功也激励了一批人去探索它的脆弱性,比如近几年非常流行的“对抗样本”。通过在原图上做一些肉眼几乎看不到的扰动,新图像就能欺骗人工智能系统,让它把“虎斑猫”分类成“鳄梨酱”,把3D打印的“乌龟”分类为“步枪”。这些研究不是杞人忧天,试想一下,如果有人恶意在道路标志上添加了这种扰动,致使自动驾驶汽车误读、漏读路标,那车上乘客的生命安全该如何保障?
论文中的研究具有相同的精神。研究人员向机器展示了一个普通的客厅生活场景:一名男子正坐在破旧椅子边缘,前倾身体,聚精会神地玩着游戏。如下图所示,在“思考”片刻后,神经网络正确检测到了一系列物体:椅子、手提包、杯子、笔记本电脑、人、书籍、电视机、瓶子、时钟。
但是,当他们在场景中引入了一些不协调的东西——一只大象后,神经网络就被新加入的像素迷惑了。如下图所示,在几次试验中,神经网络开始把大象识别为椅子,把椅子识别为沙发,它也忽略了靠近大象一侧的一排书。即便是离大象较远的物体,系统也存在错漏情况。
这个发现之所以令学界震惊,是因为实验展示的是现在最基础、最通行的物体检测技术,虽然客厅内突然出现一头大象并不现实,但公路上出现一只火鸡确实可能的。现实道路上会发生很多意料之外的事,根据论文结果,我们有理由怀疑,自动驾驶汽车会因为路边突然出现的一只火鸡,而无法检测到车前的行人。
正如罗恩菲尔德说的:“如果房间里真的有一头大象,那你肯定会注意到它,但这个系统却甚至没能检测到它的存在。”
万事皆有因果
当人类看到意想不到的东西时,我们会先愣一下,然后才恍然大悟。这是一个具有真实认知意义的常见现象——它恰好揭示了为什么神经网络无法处理“怪异”场景。
现如今,最先进的物体检测神经网络还是以“前馈”的方式工作,这意味着信息流经神经网络时是单向的,从输入细粒度像素开始,到检测曲线、检测形状、检测场景,再到最后输出最佳预测。为了确保预测的准确性,它必须在整个过程中不断收集“有用”信息,但这种单向性也意味着如果早期信息存在某种错误,那这些错误就会污染预测结果。
论文作者之一Tsotsos表示:“从神经网络顶部开始,我们确实可以探索和结果相关的一切内容,但我们也有可能让每个位置的每个特征都对每一个可能的输出作出干扰。”
举一个大家都理解的例子。假设图中有一个圆和一个正方形,它们颜色各异,一个是红的,一个是蓝的。现在要求你在短时间内观察图片,并迅速答出正方形是什么颜色的。如果注意力够集中,我们可能一瞥就能给出答案;如果有些头昏脑胀,我们可能看了一眼后还会有点迷惑,然后自然而然地会去重新看一遍。而且当我们看第二遍时,注意力是高度集中在观察正方形颜色上的。
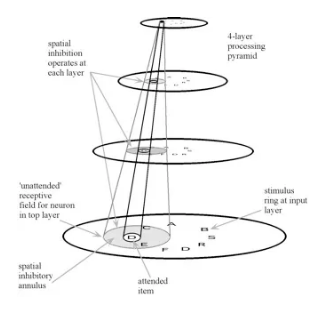
简而言之,人类的视觉系统如果没有获得想要的答案,它会回头看看自己在哪里犯了错。而这个过程可以用1990年《Behavioral and Brain Sciences》一篇论文中提到的概念——选择性调整模型(ST)来解释。如上图所示,那篇论文假设视觉处理架构在结构上是金字塔形的,该网络内的节点接收前馈和反馈连接。当刺激输入视觉系统时,首先它会以前馈的方式激活与其连接的金字塔内的所有节点;之后,输出的结果再以反馈的方式重新回到之前的节点中,激活倒置子金字塔。
这个模型的优势在于人类能依靠前馈和反馈,选择感兴趣的时空区域,选择与当前任务相关的事物并选择最佳视点,同时,我们也能通过修剪不相关的内容来限制任务相关的搜索空间,只考虑之前有过提示信息的位置,用位置/特征信息抑制感受野中的干扰,更简单、高效的获取最佳结果。
而大多数神经网络缺乏这种反馈能力,这也是科研人员一直无法有所突破的研究难点。现在使用前馈网络的一个优点是容易训练——只需让输入通过一个6层神经网络,但是,如果我们希望未来机器也能“先愣一下,然后才恍然大悟”,它们就必须理解什么时候该回头看看,什么时候该简单前馈。
人脑可以在这些过程之间无缝切换,但神经网络还需要一个新的理论框架才能做同样的事情。
就在本月,谷歌上线了一个对抗样本挑战Unrestricted Adversarial Examples Challenge,他们向社区征集参赛鸟/自行车分类器,要求参赛的“对抗者”可以在输入有扰动的图像后,依然准确分类鸟和自行车;而“攻击者”的目标是生成一张包含鸟的图像,让“对抗者”分类器把它分类成自行车。这离构建选择性调整模型还有不小距离,但这是通向解决问题的第一步——也是不可或缺的一步。
本文来源:Quanta Magazine
-
电子元器件知识大全:看图识元件2009-11-24 0
-
看图识元件2012-09-06 0
-
缺陷检测在工业生产中的应用2015-11-18 0
-
物联网技术应用于幼儿园管理,为儿童安全提供多重保障2017-12-22 0
-
恩智浦技术日-AI-IoT技术研讨会北京站2018-07-19 0
-
如果有一台AI机器人,你希望它每天帮你做哪些事?2018-10-23 0
-
浅谈RFID技术在幼儿园安全管理中的应用系统2018-11-17 0
-
什么是基于Zynq的人类生理模拟系统?2019-08-01 0
-
【免费直播】让AI芯片拥有最强大脑—AI芯片的操作系统设计介绍.2019-11-07 0
-
使用AI进行视觉检测的知识盘点2020-08-17 0
-
那种可以隔空识脸的智能AI技术门禁怎么样?2021-06-10 0
-
基于SSH的网上人才招聘系统的设计2018-01-09 838
-
人类在多方面已经输给了机器人,未来,必然是AI的时代2018-08-09 1021
-
AI偏见广泛存在 人类需要推动科技向善2019-11-14 338
全部0条评论

快来发表一下你的评论吧 !
