

双核MCU开发其实也不难!
电子说
描述
多核的微控制器(MCU)向来是设计上的一大挑战,尤其是多核异构的设计。恩智浦半导体早在2011年年底,就率先推出了基于Cortex-M4F和Cortex-M0的双核MCU——LPC43xx/43Sxx系列, 主频高达204MHz。凭借其超强的处理性能,很快受到业界的好评。四年之后,MCU双核精简版本LPC5411x系列,在广大LPC发烧友的期待中,终于露出了一代天骄的本色。
双核MCU:LPC5411x
这款LPC5411x系列MCU集成了Cortex-M4F和Cortex-M0+双内核,主频高达100MHz 。因为Cortex-M4F内核采用Harvard架构,3级流水线,支持SIMD,支持单精度浮点运算,单个时钟周期就能完成一条乘累加(MAC)指令,所以其处理性能强悍,一般用于处理复杂的计算或算法。而Cortex-M0+内核结构简单,只有2级流水线,能效高,一般用于实时控制、外设管理、数据通信等任务。
在LPC5411x产品中Cortex-M4F是主核,而Cortex-M0+是从核。从核的主要任务是协助主核处理非计算性的杂务,充分解放主核的运算能力,这样可以达到整个系统的最优性能。
为了实现整体性能最优,LPC5411x采用了多层AHB矩阵式总线架构,以及多个RAM分块。下图是LPC5411x的内部功能框图,可以看到内部的AHB矩阵式总线架构,Cortex-M4F和M0+都是总线上的master,可以访问所有的片上资源。总线访问的优先级可以通过寄存器设定。
Cortex-M4F核在AHB总线上有3个接口:I-code, D-code和System总线。而Cortex-M0+只有一个System总线接口。不同的RAM块可以被不同的AHB master同时访问。
双核MCU的存储区分配
I-code总线用于从CODE内存分区取指令, 地址范围是:0x0000-0000~0x1FFF-FFFF。D-code总线用于从CODE内存分区取操作数,地址范围是:0x0000-0000~0x1FFF-FFFF。
当以上两条总线同时访问同一内存单元时,D-code总线访问优先级比I-code高,所以D-code先访问。对地址范围从0x2000-0000~0xDFFF-FFFF的访问是通过System总线进行的,可用于访问操作数、指令等,数据访问的优先级高于取指令及中断向量。
各个存储区所在的地址区域如下表:
| 存储区 | 地址区域 | 大小 |
| Flash |
0x0000-0000 ~ 0x0003-FFFF |
256KB |
| Boot ROM |
0x0300-0000 ~ 0x0300-7FFF |
32KB |
| SRAMX |
0x0400-0000 ~ 0x0400-7FFF |
32KB |
| SRAM0 |
0x2000-0000 ~ 0x2000-FFFF |
64KB |
| SRAM1 |
0x2001-0000 ~ 0x2001-FFFF |
64KB |
| SRAM2 |
0x2002-0000 ~ 0x2002-7FFF |
32KB |
为优化系统整体处理能力,需要让这两个CPU内核同时以最快速度执行各自指令, 比如Cortex-M4F上能执行单周期的的MAC指令,同时Cortex-M0+上能执行单周期的32位乘法。
因此,存储区的合理分配策略是,Flash和RAMX以及SRAM0需要分配给Cortex-M4F内核,分别用于存放指令代码和操作数(见上图红/黄框部分)。而SRAM1/SRAM2这两块需要分给Cortex-M0+(见上图绿色框部分)。 需要注意的是,只要其中一个RAM块分配给某个CPU核,这个RAM块就不能分配给另一个CPU核, 否则这两个CPU核同时访问同一块区域时,就会出现总线争用,而导致另一个CPU核访问出现等待周期,从而降低整个系统处理效率。
双核运行的功耗如何?
在回答这个问题之前,让我们看一下其实测的CoreMark动态功耗图吧:
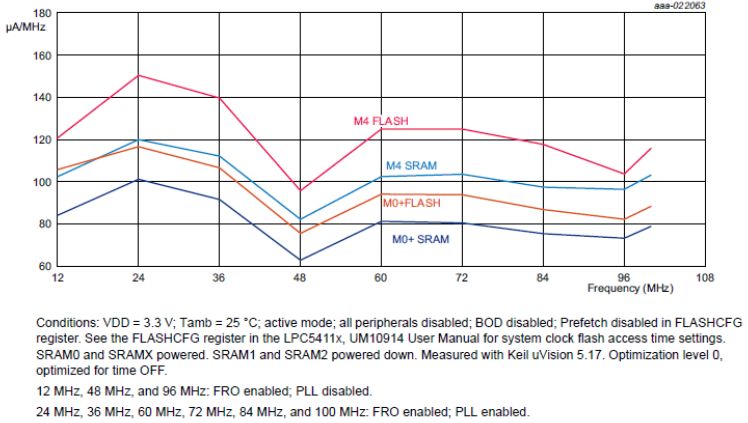
以代码放在Flash中运行并且主频为48MHz为例,Cortex-M4F动态功耗大约为96uA/MHz,而Cortex-M0+为75uA/MHz。两者之和为171uA/MHz,也就是说双核同时运行时的功耗为8.2mA。这个功耗比许多其他厂家的单Cortex-M4F核的MCU还低,但性能要强很多。
当然如果你比较关心功耗,可以根据应用实际情况让一个CPU内核进入低功耗模式,另一个CPU内核工作,等到一定条件时再唤醒另一个核。
双核之间怎么通信?
下面这张图说明了俩核之间的通信机制。
当一个CPU内核准备好数据之后,通过互锁信号放在共享RAM中,再通过邮箱机制产生中断事件,通知另一个CPU内核来处理。另一个CPU内核处理完数据后,清理相应的中断标志。通过这种方式可以实现实时性很强的双核通信和数据交换。也可以不用互锁信号和共享RAM,直接通过邮箱机制传递最多32位的数据。
另外一种简单的方法叫作消息队列机制:直接在共享RAM中创建循环缓冲器用于消息队列。当一个CPU内核准备好数据之后,就把数据发送到这个队列最后面(队尾),而另一CPU内核每次从这个队列的最前面取数据。对每个队列的访问是单向的,即一个CPU核只能写,而另一个CPU内核只能读。要实现双向,必须创建至少两个队列。 这种方法可以不用互锁信号,但可以使用中断机制通知另一个CPU核,以便实现实时通信和数据交换。
双核的开发很难吗?
针对双核以及多核体系架构,恩智浦提供了多核SDK开发库(称为MCSDK), 以及丰富的例程,包含在相应多核平台的MCUXpresso SDK 开发包中。 下图显示了MCSDK的架构:
eRPC即嵌入式远程过程调用(Embedded Remote Procedure Call),是一套实现调用另一核上远程服务的透明函数调用接口。MCMGR即多核管理器(Multicore Manager),是包含所有CPU内核信息及启动从核的函数调用接口。RPMsg-Lite即远程处理器消息机制精简版(Remote Processor Messaging – Lite),包含了所有处理器间通信的函数库。
这套库支持市面上所有主流ARM Cortex-M软件开发工具,包括IAR、KEIL、GCC,以及MCUXpresso IDE。
有了这套多核SDK开发库,用户可以不用关心硬件底层的通信机制,直接使用相应的例程和调用接口,几分钟内便可以实现双核间的通信和数据交换代码。
下面这个例子说明如何使用RPMsg-Lite,从一个CPU内核发送数据到另一内核:
rpmsg_lite_send(my_rpmsg, my_ept, REMOTE_EPT_ADDR, (char *)&msg, sizeof(msg), …);
其中my_rpmsg是rpmsg_lite_remote_init()或rpmsg_lite_master_init()调用所创建的RPMsg实例;如果是主CPU内核,就用rpmsg_lite_master_init()初始化, 否则就是远程CPU内核,用rpmsg_lite_remote_init()初始化
my_ept是此消息管道的端点,由rpmsg_lite_create_ept()调用创建的:
my_ept = rpmsg_lite_create_ept(my_rpmsg, LOCAL_EPT_ADDR, …);
msg是真正要交换的消息。
REMOTE_EPT_ADDR,LOCAL_EPT_ADDR分别是此消息管道的远程端点和本地端点的逻辑地址。
怎么调试双核应用程序?
在回答这个问题之前,先看一下硬件调试接口图:
上图说明,LPC5411x 系列支持对双核同时调试 ,就像调试单个CPU内核程序一样简单。
全部0条评论

快来发表一下你的评论吧 !
