

交通事故数据如何助力自动驾驶
电子说
描述
作为曾经十余年奋战在道路交通事故再现分析第一、第二线的一员,在面对自动驾驶测试这个新主题的时候,时常被问到关于如何基于已有的事故数据支持ADAS或自动驾驶测试的问题…索性把想到的一些零零总总的内容整理为下文,以期引发更多、更深入的探讨。笔者认知水平和领悟层次有限,难免疏漏,欢迎指正。
本文转自同济智能汽车研究所,智车科技(IV_Technology)整理,转载请注明来源。
背景:关于测试场景生成
基于场景的测试是ADAS测试的主要手段(包括法规测试和各国的NCAP测试等),也是目前更高等级自动驾驶功能所采用的主流的测试方法。生成场景的方法大致可以分为两大类:基于知识的(演绎的方法)&基于数据的(归纳的方法)。其细分架构如下图所示。
图 1 场景生成方法概要
基于知识的场景生成方法,是指从自动驾驶系统从外界接受信息的软硬件、处理信息的软硬件、执行指令的软硬件等方面开展理论分析;从解析的角度分析该系统的功能和性能的边界,并以此为主要依据,创建测试的场景。从自动驾驶系统的功能原理来看,该方法的挑战主体是其中与外界关联紧密的环境感知系统(含定位系统)和规划决策系统。这部分的分析比较偏重白箱,与特定的被测对象结合紧密。
基于数据的场景生成方法,是指基于已有的、人类驾驶员在真实交通中积累的、各类驾驶过程数据,经过分析、提炼并生成的测试场景。这些驾驶过程数据,依照数据来源可以大致分为三类:1)FOT(Field Operational Test) / NDS(Naturalistic Driving Study)、2)危险工况、3)交通事故。各数据来源对比情况如下表所示。
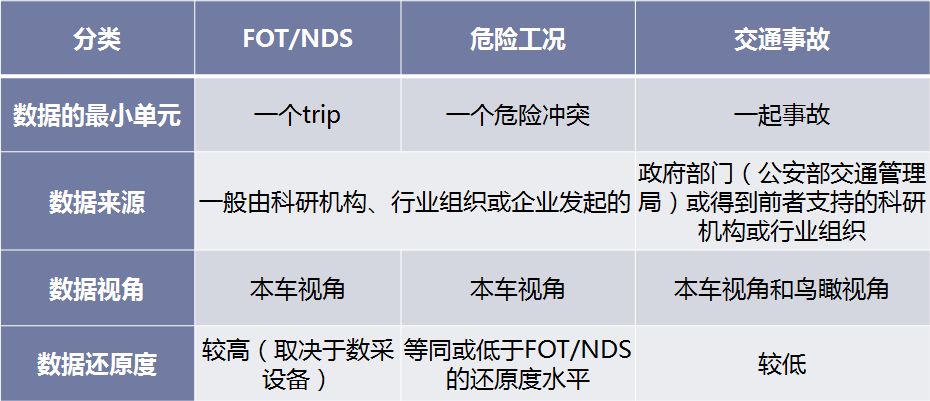
表1 :驾驶过程数据来源对比
当然,无论是基于上述哪种方法,或者综合这两种方法,也许都不是有关自动驾驶测试的终极问题(测试完备性)的答案;这有待更多有创造力的思考和尝试。
1. 道路交通事故数据
FOT/NDS数据、危险工况数据在国内外文献中很多见,在此不再敷述;最后一类交通事故由于其数据资源的特殊性,其可接近性相对较弱,以下对其进行深入分析。
交通事故数据一般来源于两大方面:1)统计数据。交通管理部门在进行道路交通事故处置时,记录的数据,包含事故基本信息、车辆信息、驾驶人信息等;2)深度数据。科研机构或行业组织开展深度事故研究时,所采集、分析、再现计算得到的数据等。
基于统计数据可以做宏观层面的估计。统计数据主要是刻画某个地域范围内的事故整体特征,以典型的四项统计为例,就是事故起数、死亡人数、受伤人数和直接财产损失。而分类的角度一般涵盖:事故的严重程度(死亡事故、一般事故、轻微事故)、事故的基本属性(时间、地点、道路类型、肇事人员和车辆情况、伤亡人员情况、是否营运车辆等)。
深度数据则能揭示一些微观的规律。基于单个事故案例,再现分析所有相关交通参与者在这个时间区间内、空间范围内、交通环境和自然环境内的运动过程(即经典的“人-车-路-环境”系统),并进而分析其原因;从而在车辆工程、交通工程,及交通管理等角度探寻更好的解决方案或者优化方法。
由于资源总体总是有限的,这两类交通事故数据呈现在单个事故的信息量和样本数量这两个维度上的状态正好相反。基于交通事故统计数据的单个事故信息约为100条,而基于深度事故研究数据的单个事故信息约为3000条。在样本数量方面,前者在我国每年约5万多个,而一个大型机构每年能完成的深度事故分析约为500至1000个。其定性对比如下图所示。
图 2 统计数据和深度数据的数据量对比
2. 深度事故研究
深度事故研究数据,传统来说是主要面向车辆工程的被动安全研究的,直接的应用是改进车身耐撞性设计、设计约束系统等,后来也逐渐被用于ESC、AEB等主动安全系统的应用效用的估计与验证。
随着ADAS和其他等级自动驾驶系统的发展,深度事故研究的方法也在随之变化,通过追加关于“碰撞前5秒“的再现分析,数据可以被转化为一个临近碰撞条件的场景,进而可被用于测试相关ADAS功能在此情况下的避撞效果(从而估计安全收益)。
深度事故数据再现分析的基本顺序是逆序,即从碰撞后的信息推导到碰撞时刻的状态和条件,再推测碰撞前的状态和条件。示意图如下。
图3:深度事故数据再现分析流程
再现分析所使用的基本方法是物理学定律,主要是碰撞力学(牛顿定律)。就分析工具而言,主要是上述定律的解析或图解法,或在此基础上运用PC-CRASH等软件进行再现计算。
深度事故数据再现分析所需要的输入信息主要包括:
事故现场的痕迹标记、信息采集和绘制的现场图
事故车辆的内外部测量和分析
事故参与者的回访
事故伤亡人员的伤情及治疗信息等
固定点的监控视频、车辆上的行车记录仪数据和视频或其他相关数据
深度事故数据再现分析的产出物主要包括:
数字化的比例复现的事故现场图(AUTOCAD)
上述计算模型及结果(PC-CRASH)
数字化的事故信息和分析结论(数据库)
3. 深度事故分析与自动驾驶
在自动驾驶开发及验证过程中,常见的基于事故分析输出物的应用包括以下两种:
基于交通事故数据生成测试场景,一般采用聚类的方法,将同类型的事故数据和特征加以提炼,形成能体现该类型事故中的大多数情形的若干种典型工况,从而用于ADAS功能的测试与验证。 例如可应用于行人AEB等功能的测试工况生成。
运用交通事故数据进行ADAS效用评价,在假设ADAS具有理想的感知、决策、执行系统的前提下,将该功能虚拟地将设置于事故冲突的双方(或单方)车辆中,仿真计算其对事故避免或事故减轻的效用,如下图所示。
图 4:从交通事故到仿真场景
限于本文篇幅,本节不做更具体展开。如果有需要,可以在之后的推送中续篇。但显然,上述两类数据的应用,都无法直面自动驾驶测试完备性这一终极拷问。
4. 关于采用事故数据生成测试场景的一些思考
由于事故研究的基本方法是逆序分析,从结果(碰撞后的最末状态)依据物理定理反推最合理的起因(碰撞前的最初状态)。这里就存在两个可能的误差源:收集的信息的完整性和可靠性、分析过程的准确性和可靠性。
一个比较常被问到的问题是,从碰撞时刻向前反推碰撞前5秒的状态时,所依据的信息是什么?
主要依靠对驾驶员的回访(彼时采取了什么操作)和地面的痕迹(如有纵向/横向的紧急操作)等。这方面信息的准确性和定量描述的精确性等都一定程度上存疑。
故而,再现分析结果的误差也将作为输入,不可避免地带入到测试场景的问题中。
小样本数据的外推性
前述所提及的深度事故样本,由于单个样本的研究成本非常高,故而样本总数纵然积累十多年,仍然较为有限。这里衍生出几个问题:
事故类型和形态会随着快速发展的交通环境和参与者行为的变化而变化,单一以延长数据累计年份的方法而增加样本数量,是否会使得数据所体现出来的问题本质存在有偏?
实际交通中的事故类型以不同的定义和研究目的进行划分,总会分成若干类;以面向ADAS功能的测试为例,如果仅探讨该功能所针对的特定场景,只会存在一小部分有效的事故样本;故而,有效样本数会进一步缩水。
由于目前覆盖范围最广的国内研究机构也只能覆盖5-7个城市(的局部区域),而国内不同地域范围、不同城市等级的差异性又确实较大,所以基于这样不大规模的深度事故数据的样本的分析结果,是否有把握外推至全国范围,仍然是个问号。
事故数据在自动驾驶测试中的适用性
以两个比较典型的事故类型为例进行解释。
追尾事故。追尾事故大多虽然并不十分严重,但确是一种常见的事故类型。由于冲突类型较为明晰,故很容易聚类归纳成为相关自动驾驶功能的测试用例或测试工况。
绝大多数的追尾事故的情景是由人类驾驶员的分心(疏于关注前车或路况)或及对前车的行驶状态或趋势的误判(对速度或及加速度的误判)而导致的,这种情况对于连续执行自动驾驶任务的车辆来说,是几乎不会演变成这样的冲突情景的,也即不会由其自身导致此类事故。
十字路口对向行驶时转弯和直行车辆的冲突。如图所示,这是国内常见的路口事故类型,在没有单独转向红绿灯控制的路口,双方都可以通行。由于人类集中注意力时的水平视角有限(25度左右),A车驾驶员往往无法及时观察到右侧来车,或无法准确判断对方车速/加速度等,从而导致碰撞事故。
图 5:十字路口交通冲突
如果没有特殊情况的视野阻挡,连续执行自动驾驶任务的车辆应比人类驾驶员有显著的信息获取能力(感知能力)的提升。当然,也必须承认“非受保护的左转”对自动驾驶的决策系统(对态势的评估和决策)也是颇具挑战的。但大量从真实事故中提炼而得的此类测试场景是否能形成有效的测试用例,达到测试验证的目的,并不是个显而易见的结论。
人类驾驶员和交通事故的辩证关系
上周与达姆施塔特工业大学(TUD)的Prof.Winner交流的时候,他提出了以下观点,人类驾驶员消解(compensate)了很多冲突的危险,从而避免了交通事故。
确实,谈起人类驾驶员,言必称90-95%左右的交通事故都是由于驾驶员本人的失误造成的。这些“失误”五花八门,分心、疲劳驾驶、酒后驾驶、驾驶经验或技能不足(特别是紧急或极限工况下)等等。而自动驾驶似乎被看作是解决这些“人类失误”一劳永逸的解决方案。
事故中的大部分必将被自动驾驶所避免,那人类驾驶员已经compensate的那些危险冲突呢?自动驾驶是否也“全权代劳”了?该如何验证?
图6:人类驾驶员的驾驶状态;上文探讨的是其中“事故工况”的部分,而砖红色的“危险冲突情况”的部分,是在真实交通中被驾驶员消解的危险。
前两年,Prof.Winner还提出过另外一个问题,启发了大家的思考;在此也再转述分享一下:当自动驾驶更多地融入了真实交通后,势必会带来新的critical scenarios和新的accidents。从事故研究的角度,也应该对此做好充分的准备和预估,并随时投入新的研究中,为自动驾驶的研发提供更好的反馈。
图 7:自动驾驶测试风险场景(摘自(How) can we validate safety of automated driving | Prof. H. Winner | Tongji | May 23, 2017)
5. 附:国内开展深度数据研究的主要机构
国内目前比较大规模的深度事故研究的方法、模式、数据库结构均脱胎于GIDAS。具体内容这里不再敷述,简要信息总结于下表。如果没有这些团队的辛勤工作,我们对如何在国内开展自动驾驶测试,可能会更迷茫一些。
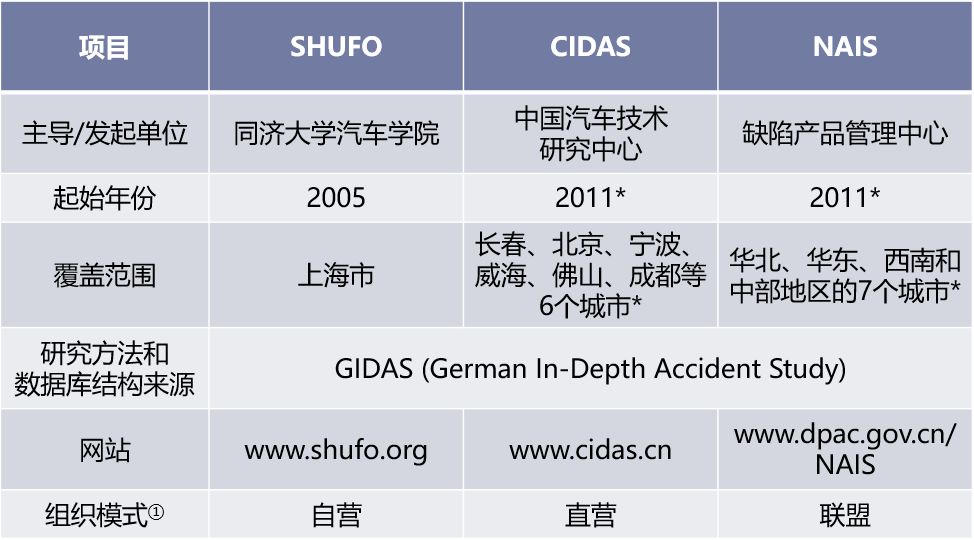
表2:国内主要深度事故研究机构
-
【工程创新队】基于android系统的交通事故处理系统2014-12-31 0
-
[科普] 谷歌自动驾驶汽车发展简史,都来了解下吧!2016-10-25 0
-
细说关于自动驾驶那些事儿2017-05-15 0
-
汽车安全产品助力全球将减少一半交通事故死亡人数2018-10-19 0
-
粗集在交通事故黑点成因分析中的应用2009-05-11 597
-
交通事故勘查图像采集系统的研究与设计2009-09-10 548
-
Uber又出大事儿! 无人驾驶汽车发生交通事故2017-03-28 1086
-
基于AdaBoost分类器的交通事故实时预测的方法2017-12-07 751
-
Uber自动驾驶事故原因解析_自动驾驶事故还有哪些2018-04-05 8532
-
苹果自动驾驶汽车发生首起交通事故 暂无人受伤2018-09-03 586
-
特斯拉自动驾驶及其主动安全功能降低交通事故,特斯拉车型保费降低2018-08-12 4282
-
自动驾驶变得较为普遍 交通事故数量也在不断增加2018-12-11 995
-
ADAS让智慧交通和自动驾驶未来可期2020-05-20 713
-
特斯拉Autopilot系统可以大幅减少交通事故2020-11-04 1483
-
海康威视推出交通事故分析研判系统2021-12-24 2293
全部0条评论

快来发表一下你的评论吧 !
