

一种基于FPGA的高性能DNN加速器自动生成方案
电子说
描述
美国伊利诺伊大学、IBM中国研究院等的最新研究,提出一种基于FPGA的DNN推理加速器DNNBuilder,获得电子设计自动化领域学术顶会ICCAD的最佳论文。实验证明,DNNBuilder生成的加速器拥有现时最先进的性能和效率,超越了同类加速器。本文带来论文作者的详细解读。
FPGA 编程耗时耗力,即使对专业人员来说也颇有难度。如何才能加速深度神经网络模型在FPGA上的部署?
有没有想过,要是有个能“一键自动生成”FPGA上DNN模型实现的工具就好了?
你还别说,现在还真有一款这样的工具,而且云端和边缘的设备都适用!
相关研究论文获得了第37届电子设计自动化顶会 International Conference on Computer Aided Design(ICCAD)的最佳论文奖。
获奖团队研究成员来自美国伊利诺伊大学(UIUC)、IBM中国研究院及IBM T. J. Watson研究中心。该团队同时隶属于IBM和UIUC联合成立的认知计算AI系统研究中心(C3SR.com)。
全文地址:
https://zhangxf218.wixsite.com/mysite
DNN推理加速挑战巨大
DNN应用已被广泛部署于云端和终端设备中,如人脸识别、语音识别(翻译)、产品推荐、物体检测等。这些应用需要大量计算与存储资源,以满足其高吞吐率、低能耗和低延时要求。
可见,不论是云端还是终端计算, DNN的推理过程都需要作加速处理才能适应日常使用需求。在加速器的设计上,设计者无可避免地会遇到多种挑战,包括:
流式数据(如视频输入输出)要求加速器具备高吞吐率和低延时的DNN推理性能;
不平衡的DNN网络要求加速器设计拥有合理的资源分配策略以平衡不同网络层的资源需求;
高分辨率图片和视频输入要求加速器能应对由此带来的巨大片上数据缓存压力。
使用FPGA,高效灵活的DNN加速方案
本文作者提出使用基于FPGA的DNN推理加速器去应对上述挑战。
FPGA可提供比基于CPU或GPU解决方案更低的延时和能耗,也能提供比专用集成电路(ASIC)更高的灵活度和更短的产品上市周期,是非常理想的DNN加速平台。
可是,设计一个基于FPGA的高性能DNN推理加速器还是充满了困难,它需要寄存器传输级(RTL)编程技巧,硬件验证知识和丰富的硬件资源分配经验等硬件设计相关知识,对于在算法层面关注深度学习的研究人员来说是非常不友好的。
为此,作者认为业界需要一种更加便捷的端到端DNN加速器自动生成方案——DNNBuilder。
只需三步,获得高性能DNN加速器
图 1 DNN推理加速器自动生成流程
DNNBuilder只需Design、Generation和Execution三步就能自动生成基于FPGA的高性能DNN推理加速器,并能把加速器快捷部署到云端或终端不同的FPGA上而不要求使用者了解RTL编程或硬件资源分配策略。
其中,DNNBuilder的第一步支持热门的深度学习框架(如Caffe,Tensorflow),使用者能继续使用原有的网络设计和训练工具去定制DNN,并可像往常一样使用GPU加速训练过程。特别的一点是,本文作者在Design步骤中增加了网络更新接口以接收该加速器在硬件性能方面的反馈,并以此引导使用者对DNN作相应优化(如增减层数、调整量化方案等)。
DNNBuilder的第二步操作会接收上一步训练好的网络定义及权重数据文件,并开始分析网络结构和提取关键参数,如网络层数、网络层种类、通道数等。根据对网络的理解,DNNBuilder会综合考虑DNN每层复杂度、权重数据可重用程度和可用的FPGA硬件资源,自动生成性能优化策略。随后,DNNBuilder会根据优化策略配置预制的高度参数化的RTL IP,并使用这些IP搭建整个DNN加速器。
在DNNBuilder的最后一步,使用者可以把生成的二进制文件下载至FPGA,运行DNN推理加速器。
三大硬件设计创新
本文提出了多个DNN加速器架构创新,令自动生成的加速器也拥有现时最高的吞吐率、最少的输出响应时间和极佳的可拓展性。论文着重介绍的有三个创新点,包括“列缓存方案(a column-based cache scheme)”、“细粒度流水线结构(a fine-grained layer-based pipeline structure)”和“高性能RTL IP (optimized and reconfigurable DNN-specific RTL IPs)”。
1)列缓存方案能在使用高清输入的情况下大幅减少存放特征图(feature map)所需的缓存空间,其核心思想是通过缓存若干slices代替缓存整个3维特征图(图2左),从而减少FPGA片上存储器(Block RAM)的使用量。
只要这些被缓存的数据可提供足够数量的卷积滑窗操作,不同网络层之间的操作就能继续下去。如当前的网络层为卷积层(卷积核=3x3,stride=1),缓存4个slices就能满足2次滑窗操作,当需要做第三次滑窗时,只需要传入1个新的slice替代旧数据即可。
此设计可行的根本原因是特征图数据生命周期短,可在计算后立刻丢弃以节省空间。实验表明(见图2右),在运行高清输入的YOLO加速器时,在使用列缓存方案可减少7至320倍的片上缓存使用量(平均减少43倍)。
2)细粒度流水线结构可在保留传统流水线结构高吞吐率特性的同时,大幅度减少DNN加速器的计算延时。
与使用传统流水线结构的加速器类似,该结构会在FPGA上例化DNN中需要使用参数的主要网络层(如卷积层、全连接层),每一主要网络层会对应加速器的一级流水;而不同的地方是此方案让各层重叠,从而大幅度降低输出需要等待的时间。
一个使用传统流水结构的加速器对一个9层的DNN作推理运算需要等待457.24ms才能获得结果,而在使用本文提出的结构后,运行同样的网络推理仅需等待59.04ms(图3右),延时下降幅度达7.7倍。
图 3传统流水线结构(左)及本文提出的细粒度流水结构(右)
3)高性能RTL IP是构建DNN加速器的最基本模块。通过分解这些DNN网络层,核心功能可以被映射到对应所需的RTL IP上,并通过这些IP搭建加速器(图4左)。
由于这些IP是高度可配置的,DNNBuilder可通过生成优化策略去合理配置这些IP,以满足不同网络层对硬件资源和运行性能的要求。
图4右展示了DNNBuilder使用的卷积IP。它的输入和输出数据处理并行度均可被配置(分别对应CPF和KPF)。此外IP中数据通路的位宽都是灵活的可变的(如输入输出位宽,bias和weight的位宽等),这样DNNBuilder就可以精确控制每一个IP相应的资源消耗及可获取的性能。
图4
自动化:确保最优资源分配
DNNBuilder可对FPGA的计算及存储资源作分配并生成优化策略,为RTL IP的参数配置提供依据。
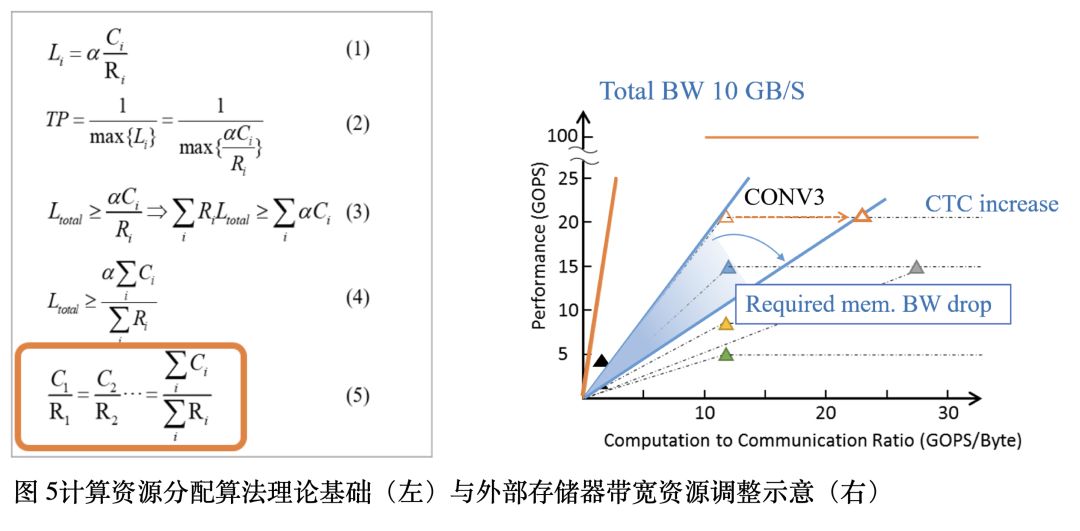
在计算资源分配方面,作者在文中提及了资源分配的理论基础(图5左公式):即在使用流水线结构的加速器中,只有每一级流水的延时相当时,加速器才能获得最大吞吐率。
根据算法理论,作者设计了基于FPGA的DNN推理加速器的资源分配算法(见原文Algorithm 1)。
此外,本文还讨论了FPGA外部存储器访存带宽的分配问题。作者使用Roofline模型(图5右)阐述了可通过改变CTC指数 (Computation to communication Ratio) 增加数据重用的机会,从而减少带宽资源消耗。CTC指数的增减可通过调整列缓存方案中slices多寡实现。根据此思路,作者在原文Algorithm2中详细描述了带宽资源分配方案。
终极杀器:DNNBuilder
为评估自动生成加速器的性能,作者选择了KU115(中端FPGA)和ZC706(嵌入式FPGA)这两款设备作为目标FPGA,让DNNBuilder分别对应云端和终端计算场景生成DNN推理加速器。
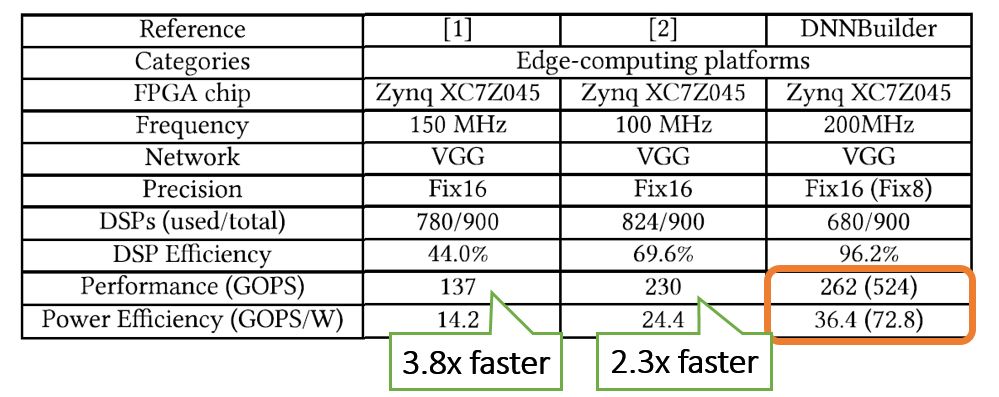
首先,作者与最近使用同款ZC706 FPGA的设计作比较(表1)。DNNBuilder生成的设计获得最高的吞吐率(GOPS)和最优秀的功率效率(GOPS/W)。
表1 DNN推理加速器性能对比(终端FPGA设备)
随后,作者选择了与其他运行在云端FPGA的加速器作对比(表2)。在使用Xilinx的一款中端FPGA KU115,DNNBuilder所生成设计能获得超过2TOPS(16比特量化)和4TOPS(8比特量化)吞吐率,超越其他设计。在功率效率方面,DNNBuilder也领先其他对手。
表2 DNN推理加速器性能对比(云端FPGA设备)

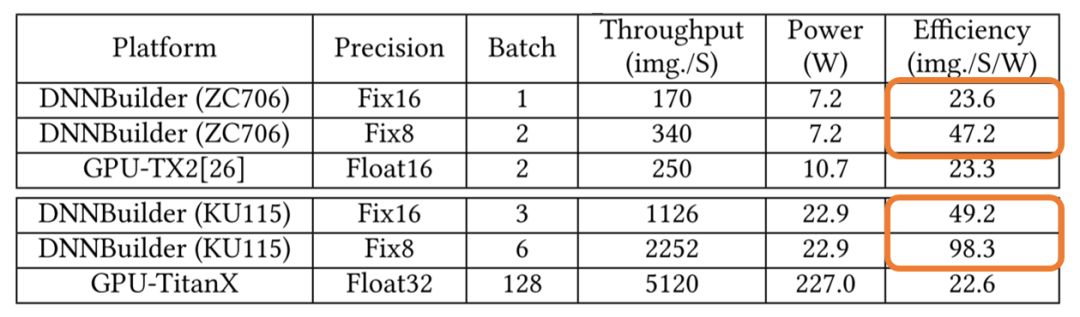
本文作者还以AlexNet作为基准测试,对比了基于GPU和FPGA的DNN推理加速器(表3)。此对比同样分成两组,分别使用云端(TitanX GPU vs. KU115 FPGA)与终端设别 (TX2 GPU vs. ZC706 FPGA)。DNNbuilder所生成的基于FPGA的加速器在效率方面超过了基于GPU的设计。
表3 GPU与FPGA的DNN推理性能对比
结论
本文作者提出了DNNBuilder,它是一种基于FPGA的高性能DNN加速器自动生成方案。作者通过三个硬件设计创新(列缓存方案、细粒度流水线结构和高性能RTL IP)和自动化资源分配方案,确保生成的加速器拥有现时最先进的性能和效率。实验表明,DNNBuilder生成的加速器在运行VGG-16时吞吐率可达4022 GOPS,效率达180.2 GOPS/W,超越了同类加速器。
-
汽车发动机升级产品,一种电子加速器是否真实?2016-10-09 0
-
汽车发动机升级产品,一种电子加速器的总体功能。2016-10-21 0
-
汽车发动机升级产品,一种电子加速器问专家?2016-12-11 0
-
汽车发动机升级产品,一种电子加速器与汽车点火增强器位置不同。2017-10-07 0
-
为什么汽车发动机升级产品,一种电子加速器能激发电的性能?2019-09-12 0
-
机器学习实战:GNN加速器的FPGA解决方案2020-10-20 0
-
核动力发动机与一种电子加速器2021-04-25 0
-
分享一种高性能的FM内置天线解决方案2021-05-26 0
-
请问怎样去设计一种MPEG-4 加速器?2021-06-04 0
-
一种基于FPGA的图神经网络加速器解决方案2021-09-25 0
-
RTthread移植代码自动生成方案2022-02-11 0
-
UIUC推出最新DNN/FPGA协同方案 助力物联网终端设备AI应用2019-06-10 1061
-
Rapanda流加速器-实时流式FPGA加速器解决方案2023-09-13 107
-
使用赛灵思Alveo加速器卡加速DNN2023-09-18 125
-
AI芯片设计DNN加速器buffer管理策略2023-10-17 812
全部0条评论

快来发表一下你的评论吧 !
