
资料下载


如何使用深度学习进行视频行人目标检测
分享资料个
近年来,随着深度学习在计算机视觉领域的广泛应用,基于深度学习的视频运动目标检测受到广大学者的青睐。这种方法的基本原理是利用大量目标样本数据训练一个基于深度神经网络的分类器,然后通过分类器在线检测目标。由于深度神经网络能够通过多层表示的方式更加深刻的描述目标特征,基于深度学习的检测方法优点在于能够准确检测具有训练数据中目标特征的目标。针对视频运动目标检测这个特定的应用,这种方法的局限性在于没有利用目标运动信息,检测结果容易出现虚警目标。本文将GMM建模方法与深度神经网络相结合,充分利用目标外观特征和运动信息,以期获得更准确的检测结果。在2017年央企双创展实地采集的展台监控数据上进行了实验验证。结果表明,本文方法相比于不融合运动信息的检测方法,行人检测准确率提高3.8%。
随着计算机计算技术和存储技术的快速发展,视频信息占人们接受信息的比重越来越大,对视频的智能分析也越来越重要。其中视频目标检测是对视频分析的重要切入点,因此不管是在学术界还是在商业界,目标检测都是研究和应用的一个热点。传统的视频运动目标检测方法包括背景差法、帧差法、光流法,这类方法的主要原理是基于像素级分析来确定运动目标相对于背景图像的差异,检测运动目标所在的位置。尽管学者们在这类方法基础上进行了很多创新改进,但是这类自底向上的方法并未利用目标外观等宏观信息,检测结果容易受光照变化、目标交叉遮挡、目标与背景相似、阴影等因素影响。此外,针对视频行人检测这个特定的应用,仅仅利用目标运动信息并不能精确定位行人目标,尤其是目标之间有交叠、部分遮挡等情况下,无法区分不同的目标。
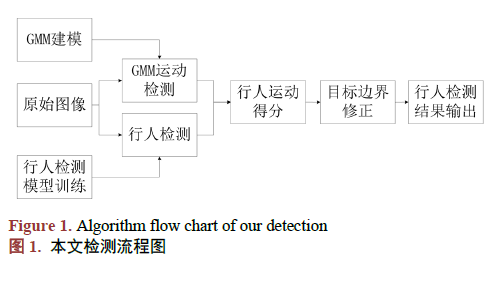
深度学习是目前机器学习在实际应用中最成功的一种方法,在自然图像分类、通用目标检测、语义分割等视觉领域取得了突破性的成绩。将深度学习用于视频运动目标检测的方法[7] [8] [9],能够有效描述目标外观、结构、色彩等视觉特征,从而检测定位目标。这类方法的局限性在于没有利用目标运动信息,导致与目标外观相似的虚警目标被误检。
本文致力于复杂场景下的视频行人目标检测,将深度学习方法引入传统视频运动目标检测方法,利用深度学习方法对行人目标准确、全面的外观描述的同时,挖掘行人目标运动信息,克服传统运动检测出现空洞、易受阴影、光照变化影响等难题,提高行人检测准确率。运动检测采用背景建模法中比较成熟的混合高斯建模法GMM,有效克服光照变化,深度学习采用YOLOv3深度神经网络模型,实现行人与背景的二分类,解决目标与背景相似的问题,二者充分融合,准确检测行人目标。

声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章





