

研究人员们提出了一种新的导航工具SafeRoute
电子说
描述
最近的研究表明,85%的女性会在外出时特意避开危险区域,选择相对安全的道路,防止受到骚扰或伤害。尽管如此,现有的导航工具并不能给用户提供安全性指数。在这篇论文中,研究人员们提出了一种新的导航工具SafeRoute,它借助深度强化学习工具,能显示城市街道中潜在的犯罪概率。以下是论智对论文的介绍:
康奈尔大学和Hollaback公司2014年调查了美国4872名女性,其中85%的人会为了避免潜在的危险而选择绕路,67%的调查对象会改变出行时间确保安全。或许当地人会熟悉他们的居住环境,知道哪里危险、哪里相对安全。可是对第一次来某地的人来说,环境的陌生会大大增加危险发生的概率。随着犯罪率的上升,我们在想,是否能创建一款安全道路导航应用,让更多人能保护自己呢?
在这篇论文中,我们的研究对象仅限于非机动车道(例如可以走路或骑自行车的区域)。在美国,想纽约、波士顿、旧金山这样的城市,通常有很多步行街道。我们想计算出到达目的地的最短距离,并且危险系数低的步行方案。现有的导航方法也能覆盖大城市,但他们没有考虑犯罪率的问题,忽略了小范围的犯罪区域。
另外,最接近也有很多有关深度强化学习进行最短路径导航的成果出现,但我们的模型不仅仅是为了规划路径,而是要加入安全因素。于是我们选择了基于深度强化学习的解决方案,这在很多数据挖掘问题中都是常用方法。
SafeRoute介绍
我们可以将路径选择的过程看作是马尔科夫决策过程,在每个步骤,智能体都要决定下一步的方向,最终到达目的地。首先会向模型输入开始和结束点的坐标,模型会返回智能体做出的决策坐标列表,同时对智能体进行奖励,避免道路上遇到犯罪事件。
模型架构
SafeRoute系统主要有两大部分:强化学习智能体可以交互的环境,以及智能体进行表示并做决定的策略网络。主要架构如下图:
环境是用具有< S, A, P, R >元组的马尔科夫决策过程表示。S表示环境持续的状态,A={a1,a2,…,aN},定义了智能体可能做出的所有动作。P(St+1 = s0|St = s,At = a)表示从一个状态转移到另一个状态的概率。R(s, a)是智能体在状态s下做出动作a时的奖励函数。
在我们的模型中,智能体的状态表示目前在地图上的位置以及目标位置。如果目标位置和此前训练时的目标位置很接近,那么智能体会采取相似行动靠近该目标。为了表示状态,地图信息被转换成有节点和线条的图,其中图嵌入用来表示强化学习智能体的连续状态,这些嵌入用node2vec来生成。用图嵌入而不用坐标的原因是,坐标不能体现地图上的交互是如何连接的任何信息。状态从智能体目前的节点和目标节点中使用的嵌入如下所示:
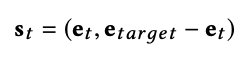
其中et表示当前节点的嵌入,etarget表示目标节点的嵌入。
另外,策略网络表示强化学习智能体使用的随机策略,用πθ(s, a) = p(a|s;θ)表示,其中θ是神经网络的参数列表,会用Adam优化器进行更新。系统使用随机梯度而不是贪婪策略,是为了防止智能体在地图上循环前进,停滞不前。运用随机梯度,智能体可以打破循环(例如向死路前进或选择可能会通向死路的道路)。神经网络包含两个隐藏层,每一层都有一个ReLU激活函数。输出使用一个softmax函数,可以返回所有行为的概率分布。
至于奖励,智能体要考虑多方面优化,所以奖励函数也必须包含多种因素。由于SafeRoute的一个重要特征就是躲避犯罪区域,所以我们将安全性添加到奖励中,用函数表示坐标到此前有过犯罪记录坐标的平均距离。
虽然SafeRoute的主要目标是增加安全性,但是我们还想尽量选择较短路线。路径沿线距离犯罪现场的所有平均距离都要计算,如果附近没有发生过犯罪事件,那么就得到奖励k。最终的奖励函数定义如下:

其中n是路径中线条的数量,m是每个节点一定半径内的犯罪事件数量,x是路线中线段的中点,c是每个半径上发生的犯罪事件,p是路线,k是超参数。
训练
训练SafeRoute也分为两部分:监督训练和用奖励进行重复训练。在最初不使用监督训练的情况下,智能体在找寻目标节点时很困难,最终可能会随意寻找方向。AlphaGo在训练时用了模拟学习的方法,让智能体在最初能够找到正确方法。同样,我们也在训练开始时用监督学习进行模拟学习。经过监督学习之后,智能体还会再次训练,避开犯罪率高的区域。再次训练的算法过程如下:

实验过程
由于此前没有类似的实验,所以我们创建了自己的SafeRoute数据集。我们从OpenStreetMap中收集了地图信息,这是一个免费的协作世界地图,我们选择了波士顿、纽约和旧金山的市区,这是很多游客会去的地方,也是繁华的市中心。最终,波士顿和旧金山的图在训练时每个epoch会欧2000个episode,而纽约的更大,可以达到4000个episode。三个模型都经过了60epoch的训练。
犯罪数据从Spotcrime中收集,其中包括了最近有关犯罪的类型和地理坐标。我们只选择了枪击、骚扰和抢劫三类。
另外,我们在多种尺度上对SafeRoute进行了评估,路线的质量有三个方面:距离犯罪点的平均距离(包括局部和全局两种)以及路线长短。局部犯罪平均距离只考虑当智能体走在路上时,附近的犯罪活动。而全局的平均距离会考虑该路线上所有发生过的犯罪活动。其中局部平均距离是重点考量因素。
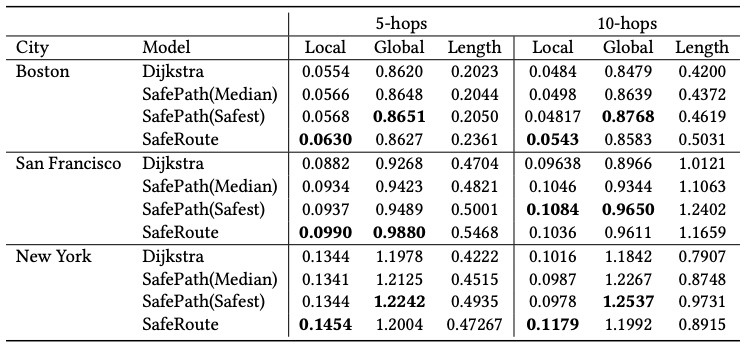
可以看到,在我们的评估前两个因素的值越高并且路线距离越短的选择更好。并且在波士顿遵循了离犯罪地点距离最短的原则,但是纽约的案例中,离犯罪地点远的路线却很长。
为了减少我们模型结果的多样性,我们为每个城市创建了三种模型,并对结果进行了平均。下表表现了SafeRoute和SafePath最安全的路线相比,增加或减少的百分比。
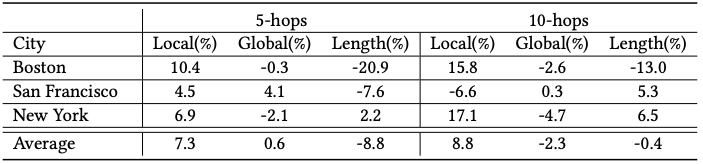
经过测试,SafeRoute能在大多情况下生成合适的结果,未来,我们打算让SafeRoute作用于更长路径和更大的地图。除此之外,我们还会研究模型的可携带型。
-
日研究人员新发现:光纤也能变身太阳能电池2009-04-14 0
-
美国普渡大学和哈佛大学的研究人员推出了一项新发明 新...2013-02-03 0
-
一种基于FPGA的高速导航解算方法设计2019-07-03 0
-
怎么实现一种基于Google Map Api的Android导航应用?2021-05-25 0
-
研究人员提出了一种柔性可拉伸扩展的多功能集成传感器阵列2018-01-24 6914
-
以色列研究人员开发出了一种能够识别不同刺激的新型传感系统2019-05-21 752
-
研究人员们提出了一系列新的点云处理模块2019-08-02 2756
-
Facebook的研究人员提出了Mesh R-CNN模型2019-08-02 3600
-
研究人员开发的可预测宇宙结构的人工智能工具2020-03-06 661
-
瑞士研究人员研发出了一种可以躲闪障碍物的无人机2020-03-23 591
-
研究人员推出了一种新的基于深度学习的策略2020-03-26 2413
-
中美研究人员合作开发出了一种可以预测新冠肺炎病情的AI工具2020-04-01 527
-
研究人员开发出了一种称为LB-WayPtNav-DH的机器人导航新框架2020-04-09 871
-
麦克斯·德尔布吕克分子医学中心的研究人员开发了一种新工具2020-07-16 1859
-
MIT研究人员提出了一种制造软气动执行器的新方法2022-05-06 1301
全部0条评论

快来发表一下你的评论吧 !
