

构建一个相对较小的图像识别卷积神经网络
描述
今天的文章是有关 “高级卷积神经” 的教程。我们希望您能够以本文为起点,在 TensorFlow 上构建更大的 CNN 来处理视觉任务。
概述
CIFAR-10 分类问题是机器学习领域一种常见的基准问题,其任务是将 RGB 32x32 像素的图像分为以下 10 类:
airplane, automobile, bird, cat, deer, dog, frog, horse, ship, and truck.
有关详情,请参阅 CIFAR-10 页面 (https://www.cs.toronto.edu/~kriz/cifar.html)及 Alex Krizhevsky 发表的一篇 技术报告 (https://tensorflow.google.cn/tutorials/images/deep_cnn?hl=zh-CN)。
目标
本文的目标是构建一个相对较小的图像识别卷积神经网络 (CNN)。在此过程中,本文将:
重点介绍网络架构、训练和评估的规范结构
提供一个用于构建更大、更为复杂的模型的模板
选择 CIFAR-10 的原因是它足够复杂,可以用来练习 TensorFlow 的大部分功能,进而扩展到大型模型。同时,该模型足够小,可以快速训练,是尝试新想法以及实验新技术的理想之选。
本文的要点
CIFAR-10 教程介绍了几个用于在 TensorFlow 中设计更大、更为复杂的模型的重要结构:
核心数学组件,包括卷积(维基百科页面)、修正线性激活函数(维基百科页面)、最大池化(维基百科页面)和局部响应归一化(AlexNet 论文的第 3.3 节)
训练期间网络活动(包括输入图像、损失以及激活函数和梯度的分布)的可视化
例行程序,用于计算已学参数的移动平均值,并在评估期间使用这些平均值提升预测性能
实施学习速率计划(随时间的推移系统性地降低)
输入数据的预取队列,使模型避开磁盘延迟和代价高的图像预处理过程
此外,我们还提供了模型的多 GPU 版本,它会展示:
如何配置模型以跨多个 GPU 卡并行训练
如何在多个 GPU 间共享和更新变量
模型架构
本 CIFAR-10 教程中的模型是一个多层架构,由卷积层和非线性层交替排列后构成。这些层后面是全连接层,然后通向 softmax 分类器。该模型除了最顶部的几层外,基本跟 Alex Krizhevsky 描述的模型架构一致。
在 GPU 上经过几个小时的训练后,该模型的准确率达到峰值(约 86%)。详情请参阅下文和相应代码。模型中包含 1068298 个可学习参数,对一张图像进行推理计算大约需要 1950 万个乘加操作。
代码结构
本教程使用的代码位于 models/tutorials/image/cifar10/ 中。
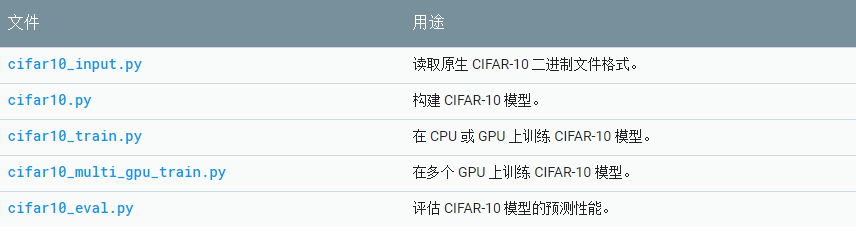
CIFAR-10 模型
CIFAR-10 网络主要包含在 cifar10.py 中。完整的训练图大约包含 765 个操作。我们发现,使用以下模块构建训练图可最大限度地提高代码的重复使用率:
模型输入:inputs() 和 distorted_inputs() 分别可添加读取和预处理 CIFAR 图像以用于评估和训练的操作
模型预测:inference() 可添加对提供的图像进行推理(即分类)的操作
模型训练:loss() 和 train() 可添加计算损失和梯度、更新变量和呈现可视化汇总的操作
模型输入
模型的输入部分由 inputs() 和 distorted_inputs() 函数构建,这两种函数会从 CIFAR-10 二进制数据文件中读取图像。这些文件包含字节长度固定的记录,因此我们可以使用 tf.FixedLengthRecordReader。如需详细了解 Reader 类的工作原理,请参阅 读取数据(https://tensorflow.google.cn/api_guides/python/reading_data?hl=zh-CN#reading-from-files)。
图像按以下方式处理:
从中心(用于评估)或随机(用于训练)剪裁成 24 x 24 像素
进行近似白化处理,使模型对图像的动态范围变化不敏感
对于训练,我们还会额外向图像应用一系列随机失真,以人为增加数据集的大小:
从左到右随机翻转图像
随机对图像亮度进行失真处理
随机对图像对比度进行失真处理
要查看可采用的失真列表,请访问 图像 页面(https://tensorflow.google.cn/api_guides/python/image?hl=zh-CN)。此外,我们还向图像附加了 tf.summary.image,以便在 TensorBoard 中可视化它们。这对验证输入的构建是否正确十分有用。
从磁盘读取图像并进行失真处理需要不少时间。为了防止这些操作影响训练速度,我们在 16 个独立的线程中执行这些操作,而这些线程会不断填充一个 TensorFlow 队列。
模型预测
模型的预测部分由 inference() 函数构建,该函数可添加计算预测对数的操作。模型这一部分的结构如下:

下图是从 TensorBoard 生成的图表,描述了推理操作的过程:
练习:inference 的输出为非归一化对数。请尝试使用 tf.nn.softmax 修改网络架构以返回归一化预测结果。
inputs() 和 inference() 函数提供了评估模型所需的所有组件。我们现在将重点转向构建训练模型所需的操作。
练习:inference() 中的模型架构与 cuda-convnet 中指定的 CIFAR-10 模型的架构略有不同。具体而言,Alex 的初始模型的顶层是局部连接层,而非全连接层。请尝试修改架构以在顶层中完全重现局部连接层。
模型训练
训练网络执行 N 元分类的常用方法是多项逻辑回归(又称 Softmax 回归)。Softmax 回归向网络输出应用 Softmax 非线性函数,并计算归一化预测与标签索引之间的交叉熵。在正则化过程中,我们还会对所有已学变量应用常见的权重衰减损失。模型的目标函数是求交叉熵损失和所有权重衰减项的和并由 loss() 函数返回。
我们通过 tf.summary.scalar 在 TensorBoard 中对其进行可视化:
我们使用标准的梯度下降法训练模型(有关其他方法,请参阅 训练 https://github.com/tensorflow/docs/tree/master/site/en/api_guides/python),其中学习速率随时间的推移呈指数级衰减。
train() 函数会添加一些最小化目标所需的操作,包括计算梯度、更新学习变量(详情请参阅 tf.train.GradientDescentOptimizer https://tensorflow.google.cn/api_docs/python/tf/train/GradientDescentOptimizer?hl=zh-CN)。它会返回一项用以对一批图像执行所有计算的操作,以便训练并更新模型。
启动并训练模型
我们已构建了模型,现在使用脚本 cifar10_train.py 启动该模型并执行训练操作。
python cifar10_train.py
注意:首次运行 CIFAR-10 教程中的任何目标时,系统都会自动下载 CIFAR-10 数据集。该数据集大约为 160MB,因此首次运行时您可以喝杯咖啡小栖一会。
您应该会看到以下输出:
Filling queue with 20000 CIFAR images before starting to train. This will take a few minutes.
2015-11-04 11:45:45.927302: step 0, loss = 4.68 (2.0 examples/sec; 64.221 sec/batch)2015-11-04 11:45:49.133065: step 10, loss = 4.66 (533.8 examples/sec; 0.240 sec/batch)2015-11-04 11:45:51.397710: step 20, loss = 4.64 (597.4 examples/sec; 0.214 sec/batch)2015-11-04 11:45:54.446850: step 30, loss = 4.62 (391.0 examples/sec; 0.327 sec/batch)2015-11-04 11:45:57.152676: step 40, loss = 4.61 (430.2 examples/sec; 0.298 sec/batch)2015-11-04 11:46:00.437717: step 50, loss = 4.59 (406.4 examples/sec; 0.315 sec/batch)...
该脚本每隔 10 步报告一次总损失值及最后一批数据的处理速度。需要注意以下几点:
第一批数据的处理速度可能会非常慢(例如,需要几分钟),因为预处理线程需要将 20000 张处理过的 CIFAR 图像填充到随机化处理队列中
报告的损失是最近一批数据的平均损失。请注意,该损失是交叉熵和所有权重衰减项的和
请留意一批数据的处理速度。上述数字是在 Tesla K40c 上得出的结果。如果您是在 CPU 上运行,速度可能会慢些
练习:进行实验时,有时候第一个训练步持续时间比较长。请尝试减少最初填充队列的图像数量。在cifar10_input.py 中搜索 min_fraction_of_examples_in_queue。
cifar10_train.py 会定期将所有模型参数保存在检查点文件中,但不会对模型进行评估。cifar10_eval.py 将使用检查点文件衡量预测性能(请参阅下文中的评估模型部分)。
如果您按照上述步骤进行操作,那么现在已开始训练 CIFAR-10 模型了。恭喜!
cifar10_train.py 返回的终端文本几乎不提供任何有关模型训练情况的信息。我们希望在训练期间更深入地了解模型的以下信息:
损失是真的在减小,还是只是噪点?
为模型提供的图像是否合适?
梯度、激活函数和权重的值是否合理?
当前的学习速率是多少?
TensorBoard 可提供此功能,它会通过 tf.summary.FileWriter 显示定期从 cifar10_train.py 导出的数据。
例如,我们可以观看 local3 特征中激活函数的分步及稀疏程度在训练过程中的变化情况:
跟踪各个损失函数以及总损失在不同时间段的情况尤为有用。不过,由于训练所用的批次较小,因此损失中夹杂的噪点相当多。在实践中,我们发现除了原始值之外,可视化损失的移动平均值也非常有用。了解脚本如何将tf.train.ExponentialMovingAverage 用于此用途。
评估模型
现在,我们来评估一下经过训练的模型在保留数据集上的表现如何。该模型由脚本 cifar10_eval.py 进行评估。它通过inference() 函数构建模型,并使用 CIFAR-10 评估数据集中的全部 10000 张图像。它会计算 precision @ 1,表示得分最高的一项预测与图像的真实标签一致的频率。
为了监控模型在训练过程中的改进情况,评估脚本会定期在 cifar10_train.py 创建的最新检查点文件上运行。
python cifar10_eval.py
注意不要在同一 GPU 上同时运行评估和训练二进制文件,否则可能会耗尽内存。您可以考虑在其他 GPU(如可用)上单独运行评估二进制文件,或在同一 GPU 上运行评估二进制文件时暂停训练二进制文件的运行。
您应该会看到以下输出:
2015-11-06 08:30:44.391206: precision @ 1 = 0.860...
该脚本只是定期返回 precision @ 1,在本例中,返回的准确率为 86%。cifar10_eval.py 还会导出可以在 TensorBoard 中可视化的汇总。在评估期间,您可通过这些汇总进一步了解模型。
训练脚本会计算所有已学变量的移动平均值。评估脚本会将所有已学模型参数替换为移动平均值。这种替换可以在评估时提升模型的性能。
练习:根据 precision @ 1,采用平均参数可以使预测性能提升 3% 左右。修改 cifar10_eval.py,使模型不采用平均参数,然后验证预测性能是否会下降。
使用多个 GPU 卡训练模型
现代工作站可能会包含多个用于科学计算的 GPU。TensorFlow 可利用此环境在多个卡上同时运行训练操作。
如果要以并行的分布式方式训练模型,则需要协调训练过程。在接下来的内容中,术语 “模型副本” 指在数据子集上训练的模型副本。
简单地采用模型参数异步更新方法会导致训练性能无法达到最佳,因为单个模型副本在训练时使用的可能是过时的模型参数。反之,如果采用完全同步的更新后参数,其速度堪比最慢的模型副本。
在具有多个 GPU 卡的工作站中,每个 GPU 的速度大致相当,且具有足够的内存来运行整个 CIFAR-10 模型。因此,我们选择按照以下方式设计训练系统:
在每个 GPU 上放一个模型副本
等待所有 GPU 完成一批数据的处理工作,然后同步更新模型参数
模型示意图如下所示:
请注意,每个 GPU 都会针对一批唯一的数据计算推理和梯度。这种设置可以有效地将一大批数据划分到各个 GPU 上。
这种设置要求所有 GPU 都共享模型参数。众所周知,将数据传输到 GPU 或从中向外传输数据的速度非常慢。因此,我们决定在 CPU 上存储和更新所有模型参数(如绿色方框所示)。当所有 GPU 均处理完一批新数据时,系统会将一组全新的模型参数传输给相应 GPU。
GPU 会同步运行。GPU 的所有梯度将累积并求平均值(如绿色方框所示)。模型参数会更新为所有模型副本的梯度平均值。
将变量和操作放到多个设备上
将操作和变量放到多个设备上需要一些特殊的抽象操作。
第一个抽象操作是计算单个模型副本的推理和梯度的函数。在代码中,我们将此抽象操作称为 “tower”。我们必须为每个 tower 设置两个属性:
tower 中所有操作的唯一名称。 tf.name_scope 通过添加作用域前缀提供唯一的名称。例如,第一个 tower 中的所有操作都会附带 tower_0 前缀,例如 tower_0/conv1/Conv2D
运行 tower 中操作的首选硬件设备。 tf.device 会指定该属性。例如,第一个 tower 中的所有操作都位于device('/device:GPU:0') 作用域内,表示它们应在第一个 GPU 上运行
为了在多 GPU 版本中共享变量,所有变量都固定到 CPU 上且通过 tf.get_variable 访问。了解如何共享变量。
在多个 GPU 卡上启动并训练模型
如果计算机上安装了多个 GPU 卡,您可以使用 cifar10_multi_gpu_train.py 脚本借助它们加快模型的训练过程。此版训练脚本可在多个 GPU 卡上并行训练模型。
python cifar10_multi_gpu_train.py --num_gpus=2
请注意,使用的 GPU 卡数量默认为 1。此外,如果计算机上仅有一个 GPU,则所有计算都会在该 GPU 上运行,即使您设置的是多个 GPU。
练习:cifar10_train.py 的默认设置是在大小为 128 的批次数据上运行。请尝试在 2 个 GPU 上运行cifar10_multi_gpu_train.py,批次大小为 64,然后比较这两种方式的训练速度。
后续学习计划
如果您有兴趣开发并训练您自己的图像分类系统,我们建议您分叉本教程的代码,并替换组件以解决您的图像分类问题。
练习:下载 Street View House Numbers (SVHN) 数据集(http://ufldl.stanford.edu/housenumbers/)。分叉 CIFAR-10 教程的代码并将输入数据替换为 SVHN。尝试调整网络架构以提高预测性能。
-
【uFun试用申请】基于cortex-m系列核和卷积神经网络算法的图像识别2019-04-09 0
-
基于赛灵思FPGA的卷积神经网络实现设计2019-06-19 0
-
卷积神经网络如何使用2019-07-17 0
-
卷积神经网络一维卷积的处理过程2021-12-23 0
-
卷积神经网络模型发展及应用2022-08-02 0
-
卷积神经网络为什么适合图像处理?2022-09-08 0
-
卷积神经网络简介:什么是机器学习?2023-02-23 0
-
卷积神经网络的应用 卷积神经网络通常用来处理什么2023-08-21 3898
-
卷积神经网络概述 卷积神经网络的特点 cnn卷积神经网络的优点2023-08-21 1914
-
卷积神经网络如何识别图像2023-08-21 1401
-
卷积神经网络应用领域2023-08-21 2713
-
卷积神经网络的介绍 什么是卷积神经网络算法2023-08-21 1413
-
卷积神经网络算法比其他算法好吗2023-08-21 446
-
图像识别卷积神经网络模型2023-08-21 528
-
使用Python卷积神经网络(CNN)进行图像识别的基本步骤2023-11-20 1738
全部0条评论

快来发表一下你的评论吧 !
