

如何设计CEV模型与质量甜点算法详细资料概述
描述

实时视频通信质量评价的方法思路并不复杂,其难点一是在于实时通讯通常并没有参考,其准确度与精度难以达到一个客观最佳值;二是在于我们并不希望实时通信的计算量过大,应当尽量避免传统编码与那些会明显提升算法复杂度的方法。在介绍完实时视频通信质量评价的方法研究之后,我将为大家分享如何根据质量模型设计质量甜点算法。
PART1 评价实时视频通信质量
1. 动机
我们能否找到一种可靠的评价视频通话质量的自动化方法?能否实现对视频通话端到端质量的实时监控?想必这两项都是产品上线测试与运营中亟需的衡量标尺。

但我们并不能将现有的简单方法直接用于评价实时视频通信质量,首先是因为传统方法中比较常用的 PSNR、SSIM需要参考图像用以比较并且每一帧都要计算,这对实时视频通信来说计算量较大;其次,传统方法仅考虑空间维度的质量而未考虑时间维度的质量,实时视频通信还需重点考虑到时间间纬度的质量,即低延迟和流畅度。

当然,从2008年到2017年陆陆续续有改进方法被提出,如PEVQ、VQuad-HD、VMAF等,虽然相对于之前的方法有所进步,但由于这些方法需要全参考,其背后庞大的计算量并不适用于实时视频通讯。
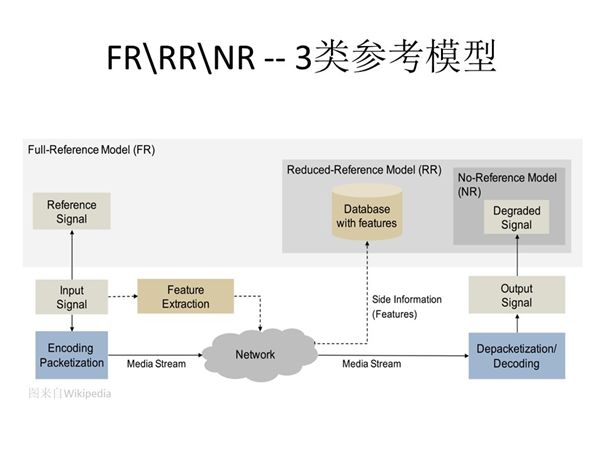
视频质量评价模型有以下三种:全参考、半参考、无参考。考虑到运营系统中可以获取部分参考信息,我们主要选用了半参考模型。半参考模型虽然不需要获取原始视频作为对比,但也可获取原始视频中的一些编码和网络信息特征作为对比如QP、PSNR、RTT等。
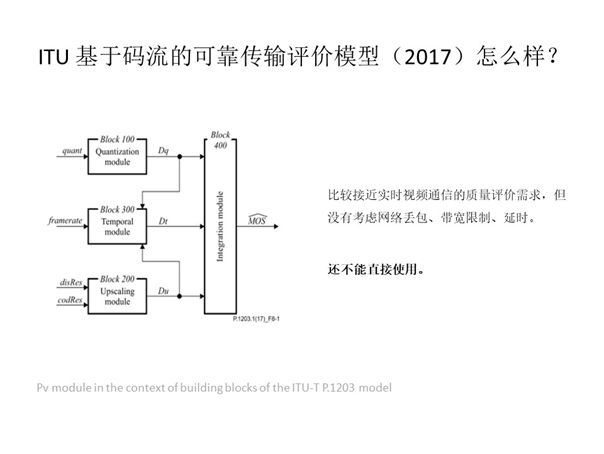
至于ITU在2017年提出的基于码流的传输评价模型,可以说与我们的需求较为贴近。此类模型原理可总结为输入所需特征值并通过训练模型输出结果,但此方法输入的特征值并不包括实时视频通讯中容易出现的网络丢包、延时、带宽限制等影响因素,并不适用于实时视频通讯。
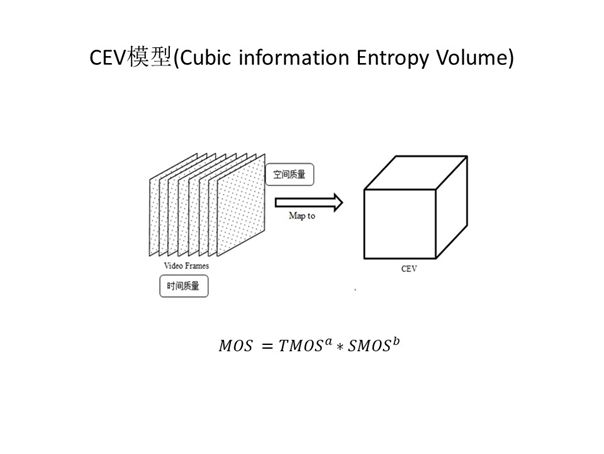
综上所述,为了实现符合要求的评价实时视频通信质量方法,我们根据自身需求提出了一种涵盖时间质量与空间质量两个维度的全新质量模型CEV。实时视频通讯的质量由时间质量与空间质量共同决定二者缺一不可,时间质量包括流畅度、延时等确保视频流畅播放的指标,空间质量包括清晰度等确保画面观感的指标。
2. 基于CEV质量评价模型的实践

我们基于CEV质量评价模型的实践主要分为以下四步骤:
生成系统
主要用于生成参与人工主观打分的视频源。
打分系统
由于主观MOS分质量评价是一个黄金标准,此项标准需要人工主观打分进行统计,我们需要大量的人工评估数据才能让质量评价算法标准具有良好匹配度。通过建立的打分系统,我们收集参与者的打分结果并导出主观分数据用于接下来的分析。
视频质量分
基于打分系统得到的人工主观分数据我们分析影响视频质量的多项因子。
建模预测
根据主观评分建立预测模型并预测不同参数下视频的质量得分。
2.1 生成系统

我们的研究主要针对于实时视频通信,着重于研究编码失真与传输失真。虽然在标准库中有很多失真类型如高频噪声、高斯模糊、压缩失真等等,但对不适用于实时视频的质量评价。在编码失真方面我们的研究主要围绕量化失真、频域变换失真(DCT)、下采样失真、良性超分辨率失真与良性滤波失真展开;在传输失真方面则主要围绕降低帧率(抽帧)、卡帧丢帧与延迟展开。
虽然失真类型复杂多样,但我们的研究主要针对传输失真与编码失真,并未着重考虑如高斯模糊或偏移失真等其他失真类型。基于此前提我们积累了900个视频失真试例,其中600个为传输失真;并让35人参与实验,得到生成系统的实验数据。
如果将我们的实验数据与公共数据集进行对比,可以看到我们的数据量处在第三名左右的位置。
在生成系统中,系统会首先分析视频源并依据其在时间与空间复杂度上的不同将视频进行分类,按照分辨率等指标整理得到无损视频序列;随后系统会对其中部分视频进行模拟丢包、编码器失真等操作从而生成一定数量的低质量视频;最后再将这些低质量视频与原始视频混合推送至实验端进行打分操作。
2.2 众包打分系统
实验端是简易的Web页面,参与者通过Web端观看视频并打分,以便接下来的影响因子分析。
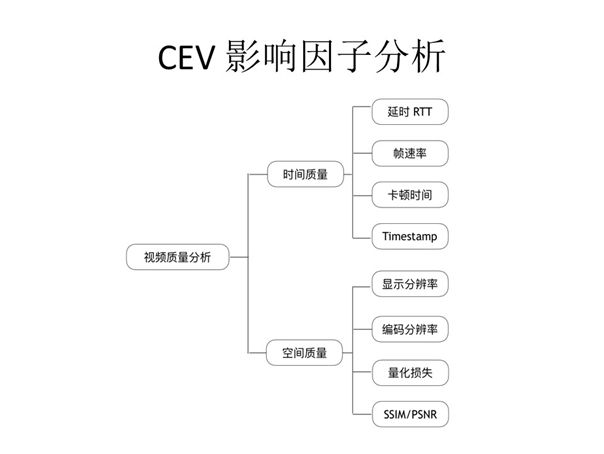
影响因子分析主要会从时间质量与空间质量两大方面全面衡量影响视频通信质量的因素。在时间质量方面,除了时间戳,系统会着重分析视频延时RTT与流畅性(帧速率、卡顿时间)。一般的直播系统,流畅性较易达成而低延时无法完全保证,而实时性则是实时视频通讯之根本。所以,一般的实时系统为了保证严苛的实时性体验会牺牲一部分画面质量与流畅性。在空间质量方面,系统会重点考量显示分辨率、编码分辨率、编码量化参数等。带宽资源是否充足会对空间质量产生显著影响,而量化损失分析主要通过记录QP编码的量化参数实现,SSIM/PSNR则是在计算资源允许的条件下得到空间质量。
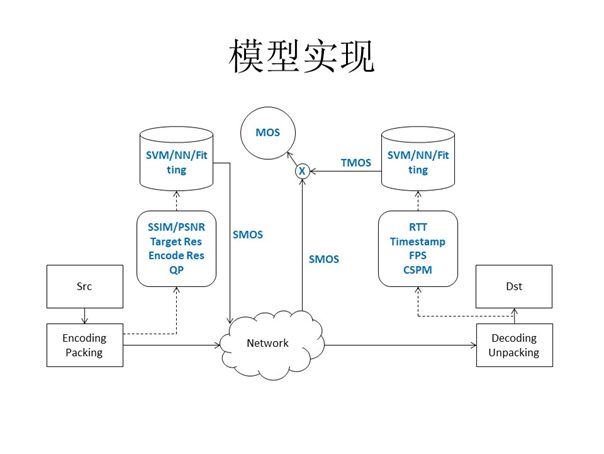
于是我们实现了前文提到的半参考模型在影响因子分析上的运用。位于上图右侧的TMOS分是对时间质量的量化,其所需要的RTT、Timestamp、FPS、CSPM等参数主要来源于解码端;左侧的SMOS分是对空间质量的量化,其所需要的SSIM/PSNR、分辨率、QP等参数主要来源于编码端。此模型主要的功能便是将来自解码端与编码端的数据整合分析最终生成一个整体模型,这些数据都会经过SVM/NN(神经网络)/Fitting的处理得到相应的时间质量/空间质量评价值,用以实现对视频通信质量的估计。
分析时间质量TMOS

在分析时间质量TMOS时,我们会优先采取拟合模型处理RTT、Play Timestamp、Frame rate、CSPM,原因是我们希望用最小的代价快速得到最有价值的数据。
1)回归预测

最佳策略便是仅将所有变量代入一个公式就可直接得到TMOS,我们使用图中的公式对Fmos、RTTmos、Cmos等进行拟合,公式中的m9、m10、m13等等代表的就是这些拟合参数,此公式利用梯度下降法训练,将这些实际评测出的数据进行均方差最小(损失函数)的拟合,即可得到这个公式的一系列参数。
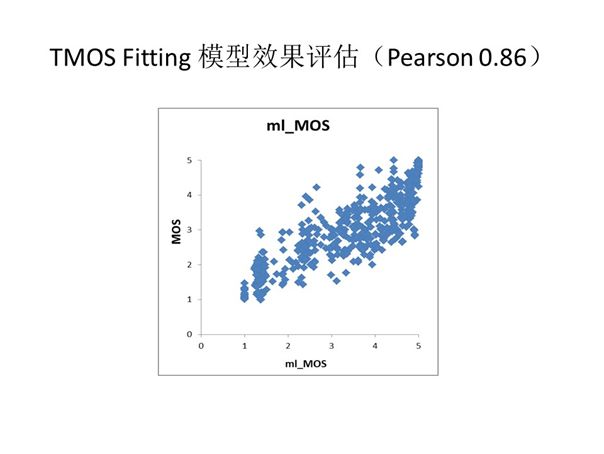
我们会选取其中70%的数据用于训练,30%的数据用于测试并得出相关系数,上图展示的是便是我们的一个测试集得出的相关系数为0.86。
2)SVM建模
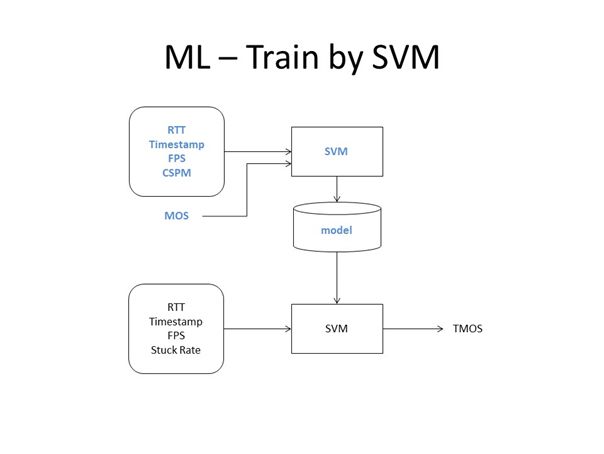
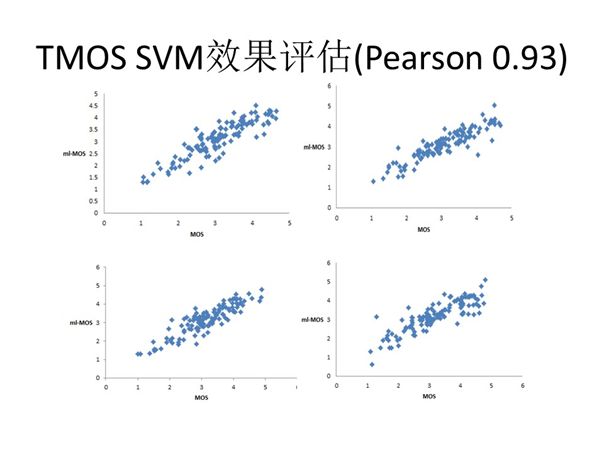
除了上述实践,我们还使用了SVM方法训练系统。SVM的意义在于可将原本难以量化的时间戳引入公式作为参数的一部分影响最终的评估结果,使用SVM后相同测试集得到的相关系数由原来的0.86变为0.93,精度进一步提升。
3)NN神经网络
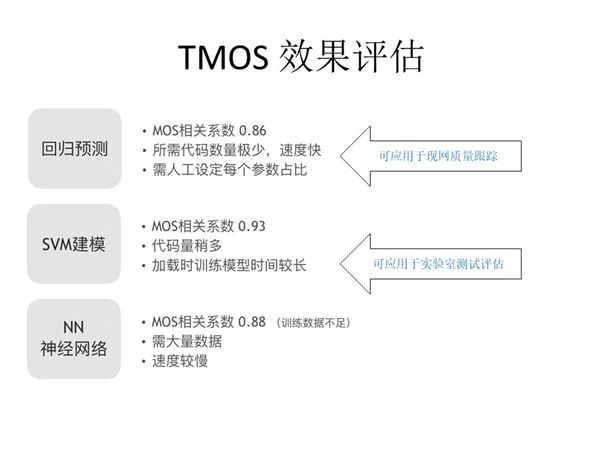
除了回归预测与SVM建模,神经网络也能为提升MOS分的精度带来帮助,前提是需要足够的训练数据规模。在实践中我们使用了七至八层的深度网络,也尝试了两至三层的浅度网络,测试得到的最高相关系数为0.88,比不上SVM建模优化后的0.93,其原因可能是训练的数据量不够,具体原因还需要进一步分析。因此,最终我们选择了可用于现网质量跟踪的回归预测与可用于实验室测试评估的SVM建模优化TMOS时间质量分析模型。
分析空间质量SMOS
1)回归预测

分析空间质量首先需要评估PSNR/SSIM指标。
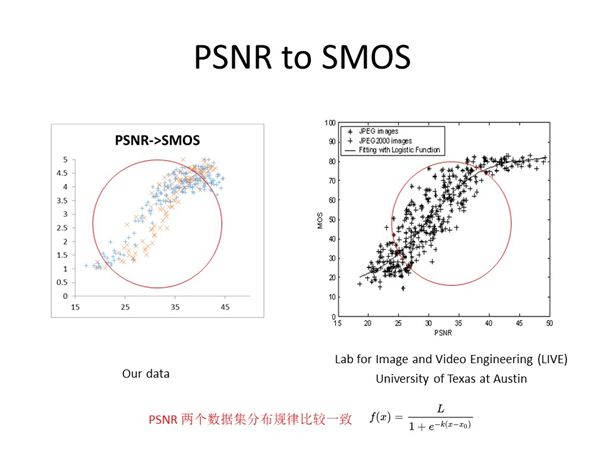
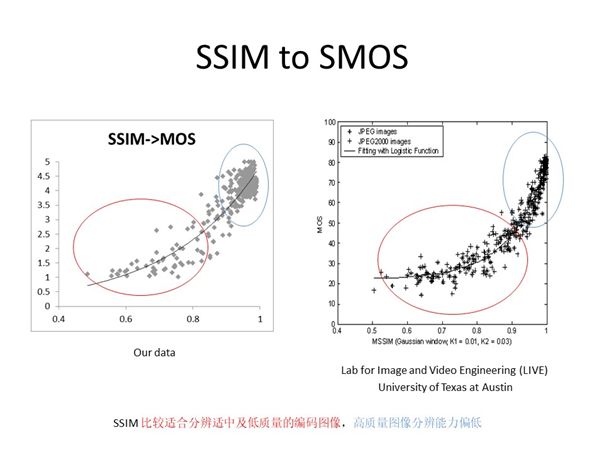
上面两张图的左侧分别表示我们经过测试得到的PSNR/SSIM数据集分布规律,右侧表示互联网上公开的PSNR/SSIM数据集分布规律,可以看到二者大致相同。
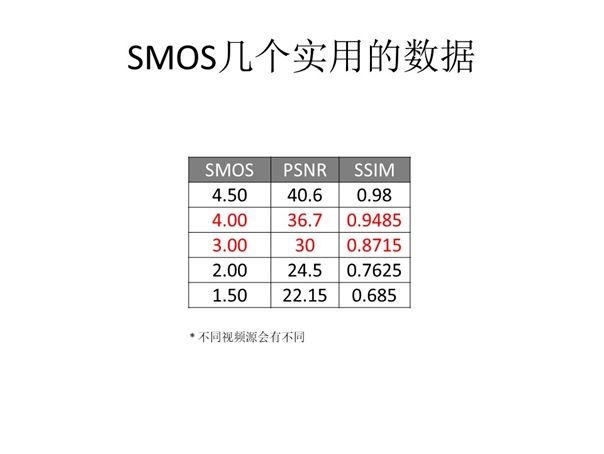
如果讨论具体的量化指标,上图展示的是SMOS的几个实用数据。我们可以看到当PSNR为30时SMOS分为3.00。
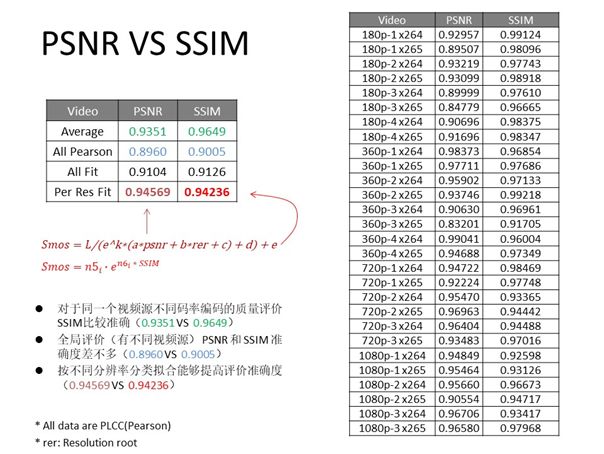
根据上图数据进一步分析PSNR与SSIM,我们发现即使在有些场景下SSIM并不准确,但处理同一个视频源不同码率编码的相对质量评价SSIM还是较为准确的,而面对有不同视频源的全局评价时PSNR与SSIM势均力敌,准确度相似;因此,我们可以对同一个视频按照不同分辨率比较来分类拟合提高评价准确度,比如对于不同分辨率的视频基于PSNR/SSIM估计质量值的相关度只有0.89,而对于相同尺寸同类型的视频基于PSNR/SSIM估计质量值其相关度可达到0.93~0.96。对于不同分辨率的视频,集合越大其准确度越低;而对于同一类视频其预测准确度较高。

同样,空间质量分析也存在一个拟合模型,主要分为编码质量损失与下采样质量损失。上图公式中 代表编码质量损失, 代表下采样质量损失,我们建议以下三种预测方法:方法一是直接通过QP预测,这是几乎没有任何代价的方法;方法二是通过PSNR预测,此方法计算量较大,一般会采取10帧取1帧或一秒一帧的方式预测;方法三是通过SSIM预测,但这种方法的处理速度最为缓慢但精度最高。我们需要根据PSNR/SSIM MOS分曲线的走向选用不同的拟合公式,需要强调的是,方法一可直接在编码或解码端实现,而方法二、三必须在编码端完成计算后才能将得到的数据发送给解码端,单纯解码端无法实现。
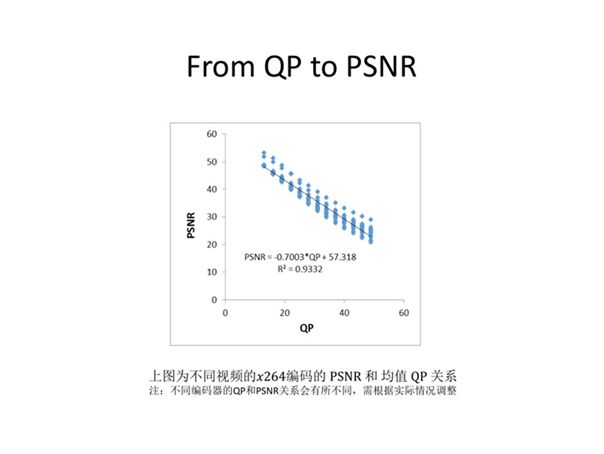
上图较为清晰地展示了H.264下QP与PSNR的关系,可以看到QP与视频空间质量呈现明显的线性负相关关系,QP越大视频空间质量越低。
2)SVM建模
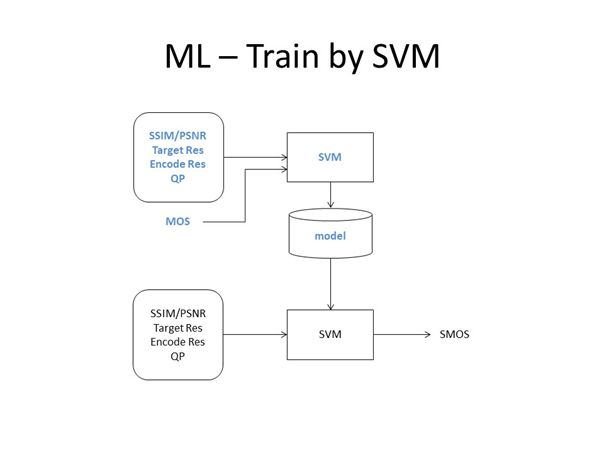
与时间质量分析的思路类似,我们也可以借助SVM建模优化空间质量分析。

在分别得到空间模式与时间模式对应的MOS分后,我们就可计算总的MOS分。这里的a、b两个参数可以根据应用场景需求做出一些变化:如果此应用场景对流畅度要求较高那么我们就可以适当增大a的值(权重),如果此应用场景对清晰度要求更高则适当增大b的值(权重)。
2.3 现网与实验室应用
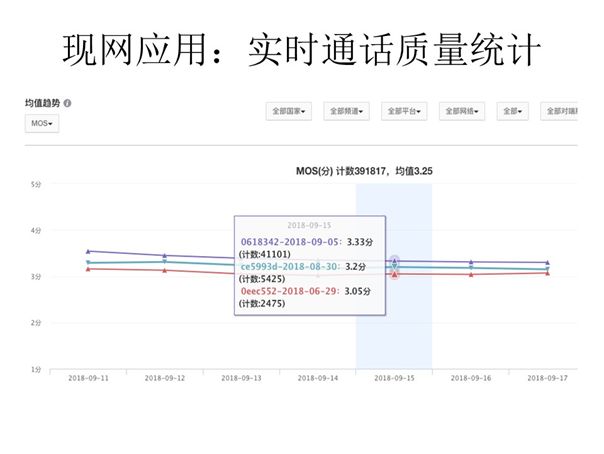
将此分析工具运用于现网的实时通话质量统计,我们可以看到随着版本的升级,计算得到的MOS分也在增加,反应出版本迭代带来的实时视频通话质量的提升或下降。
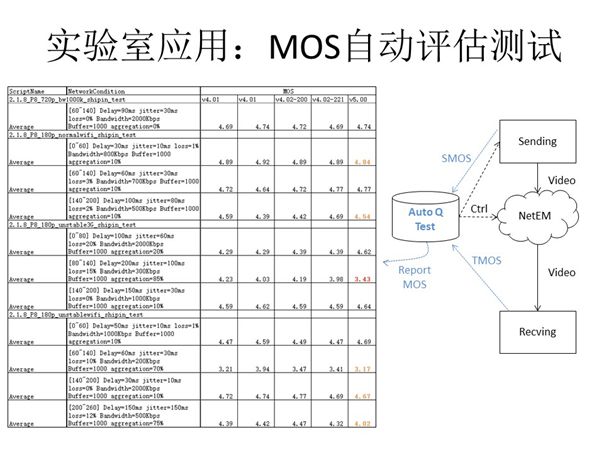
将此分析工具运用于实验室等理想环境,根据上图左侧表格展示的自动化测试统计结果我们可以看到,设置网络条件千变万化(延时30毫秒,抖动10毫秒等等),系统能较为准确且自动计算出相应MOS分。右侧展示的就是与此实验相关的拓扑结构,其中NetEM代表网络模拟器。
2.4 CEV缺点
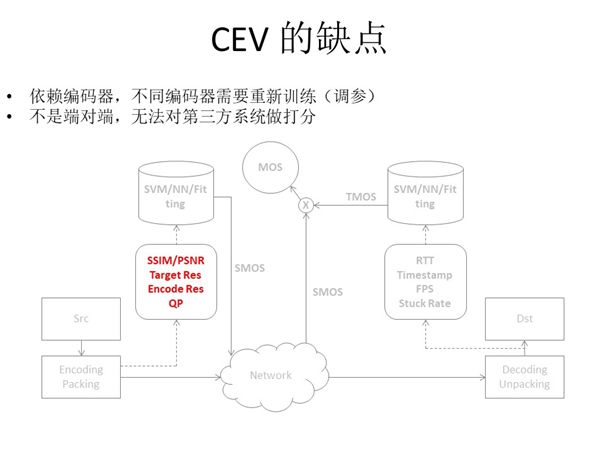
当然,CEV也存在一定局限性。首先就是非端对端的,CEV现在仅能作为我们内部的测试方案而未实现端对端,这就导致我们无法用此方法评估对比微信、FaceTime等第三方应用场景的实时视频质量。其次就是由于CEV依赖编码器,面对不同编码器(如VP8、VP9在QP取值范围上存在不一致)需要重新训练并调整参数,由此造成的工作量无疑是巨大的。
2.5 端到端MOS评分
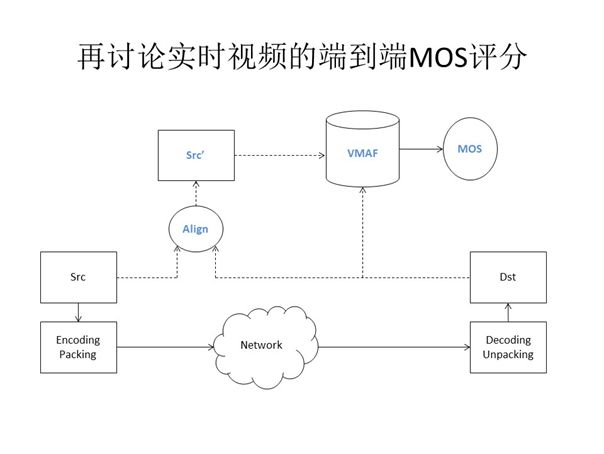
那么我们如何实现实时视频的端到端MOS评分,达成对第三方平台的评估与对比?下一步的计划就是使用“增强版“的VMAF。所谓增强版就是,VMAF存在原始参考视频与目标视频对齐的要求,那么我们可通过在输入VMAF之前进行对齐操作,从而实现实时视频的端到端MOS评分。
PART2 根据质量模型设计质量甜点算法
1. 动机
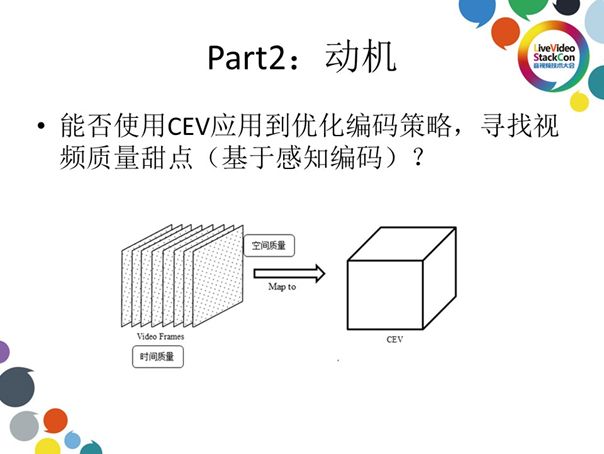
在构建CEV质量评估模型后我们继续探索,能否将此模型用于寻找基于感知编码的视频质量甜点?之前的试验并不涉及编码过程,那么我们能否更进一步,将其用于优化对编码的使用?
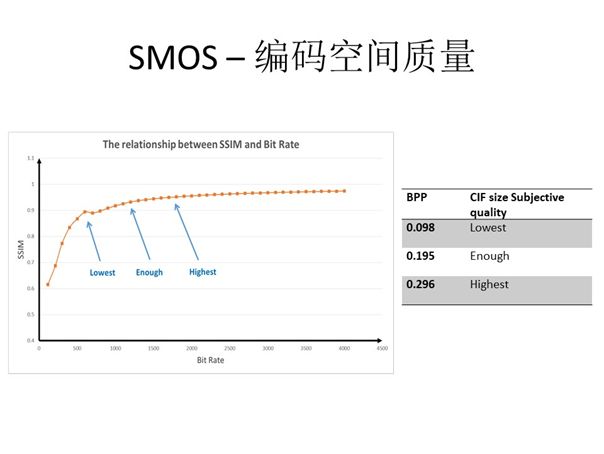
从概念上来说编码也存在时间质量与空间质量。首先就空间质量而言,在我们常见的质量与码率曲线上二者呈正相关关系且并非直线,其曲线上存在三个值得我们关注的点:第一个点是图中的Lowest也就是质量明显下降的点,表明在码率超过此点瞬间视频质量会出现一阵快速衰减,我们将此点定义为保底码率;第二个点位于图中指示的Highest,表示在此点后视频质量几乎不会随码率出现明显提升;而中间的Enough点所示就是我们的建议码率。考虑到不同分辨率与帧率的情况,(那我们把它再规划到BPP,就是Bit Per Pixel,即每个像素压缩以后,需要的占用的位数。)
在空间质量指标中影响编码的主要有影响帧间参考的帧率与影响帧内参考的分辨率。针对这种情况我们对帧率与分辨率进行了调整:帧率的调整在于随着帧率增高,维持同样质量需要增加的码率就相应降低且基本遵循测试得到的线性关系;分辨率的调整在于随着分辨率的增高,维持同样质量所需码率的也相应降低。这两点很容易理解:随着分辨率的提升,帧内参考信息越多压缩率则增高;而在相同质量下帧率越高,前后帧的相关性越强,每帧的变化越小那么压缩率也随之增高,码率的的提升与质量的提升呈现log函数的关系特点。
2. 思路:规模法则
我们使用杰弗里·韦斯特法则明确规定规律,有些情景是线性,也有部分情景是超线性或亚线性的。
根据数据我们可得到分辨率与质量的关系描述,但一般多为亚性关系。为了更好地研究相关参数,我们提供了这样一个公式:
应用规模法则我们可以得到,公式中x的取值为1.5~3,x越大则编码器越适合高分辨率。
3. Openh264编码举例
我们以Openh264编码作为示例,由图表我们可以看到随着分辨率的提高维持相同质量所需要的BPP不断下降,这符合我们之前对这个法则规律的期待。
除了编码空间质量SMOS,我们还需要衡量编码时间质量TMOS。之前提到的无论是SMOS还是TMOS其本质都是通过一些数据的训练拟合得到的数值,这里提到的编码时间质量也不例外,从曲线当中我们可以看到当帧率在7FPS以下时时间质量已经不符合我们的要求了。需要强调的是,无论是时间质量还是空间质量都是基于主观感受确定的。一旦超过25FPS也就是人眼视觉暂留原理的阈值那么继续提升帧率对质量的影响微乎其微了。由于在这里我们不考虑丢包、延时等额外变量,时间质量的问题比较容易解决。
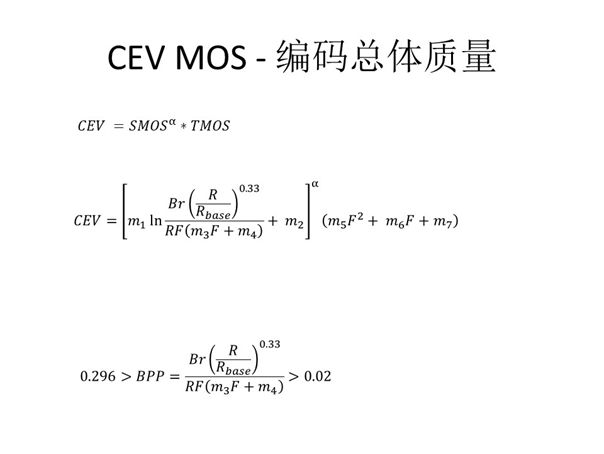
在得到了SMOS与TMOS之后,我们就可结合二者数值得到一个类似于“立方体”的模型,其公式如图所示,CEV由时间质量与空间质量共同决定。需要强调的是为保证质量符合实际需求,这里存在一项约束条件:BPP须大于0.02且小于0.296。
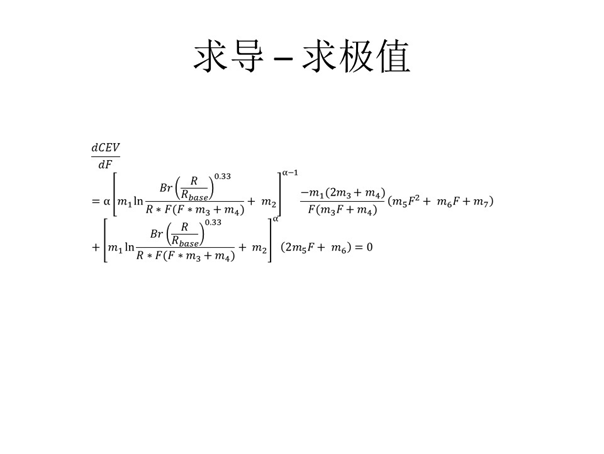
仔细观察不难看出CEV是一个凸函数,如果可用带宽确定,对方订阅的视频大小确定,那么我们需要得到最佳帧率是多少?我们对帧率求导,得到上图所示公式。若求导结果为0相当于“立方体”体积最大化,此时就是最佳帧率。

对公式进行简化与求导即可计算码率值,再使用约束公式即可求解最终结果。
最终我们得到了由分辨率与帧率两项变量组成的关系式,根据此公式可算出给定码率下分辨率与帧率之间的关系,将其图像画出我们可以看到最顶端代表最佳值。这里需要解释的是,在实际应用中相同复杂度的视频得出值可能较为近似,我们得到的是时间与空间复杂度的平均状况。但是,若视频复杂度较低则帧率可提高,反之帧率应当下降,这里需要根据复杂度做动态调整,视频复杂度可以以特定码率下的量化参数来估计,相同码率下QP越大复杂度就越高。
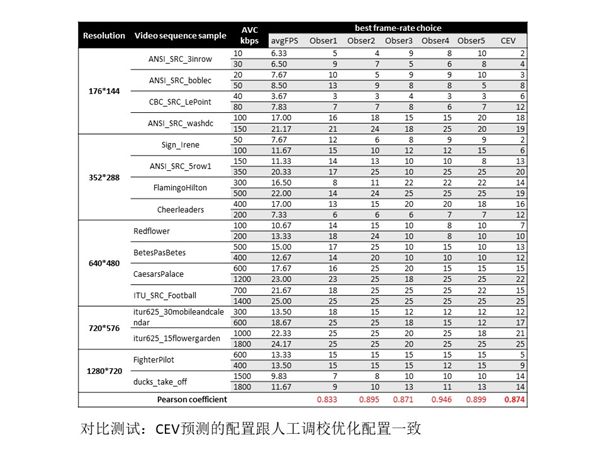
继续反向验证此模型,让五位参与者对不同分辨率进行测试,最终我们得到的相关系数为0.87,结果符合我们的预期,可以说我们成功将视频通话质量模型应用到编码参数的自动化优化。
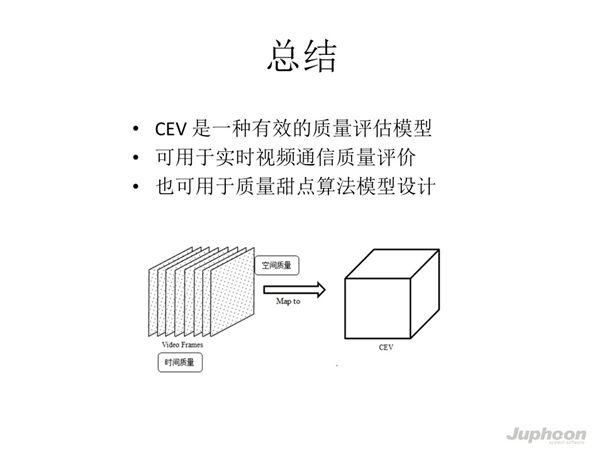
通过CEV模型,我们可在实现评估实时视频通讯质量的同时确定视频通讯的质量甜点,希望算法背后的思路能为大家带来帮助,谢谢。
-
调制解调器和积分器算法程序的详细资料概述2018-04-28 1281
-
TMS320VC5509A PGE IBIS Model DSP IBIS行为模型的详细资料概述2018-05-03 1136
-
C5515ZCH图像信息系统IBIS模型的详细资料概述2018-05-04 1224
-
C5535 ZHH边界扫描模型详细资料概述2018-05-04 901
-
TMS320C5501 GZZ IBIS ModelDSP行为模型的详细资料概述2018-05-04 1127
-
TMS320VC5504 ZCH 边界扫描模型的详细资料概述2018-05-04 825
-
利用Excel DSP兼容的第三方算法来对数字电机控制详细资料概述2018-05-07 884
-
TI的基于DSP兼容的第三方算法协议的详细资料概述2018-05-07 806
-
Excel DSP兼容的第三方算法用在语音系统上的详细资料概述2018-05-07 895
-
如何采用DSP兼容的第三方算法来进行视频成像技术的详细资料概述2018-05-07 940
-
LabVIEW在信捷PLC通讯上的应用详细资料概述2018-06-07 2915
-
PID程序算法的详细资料概述免费下载2018-07-24 880
-
SV601187的详细资料合集包括了电路图,原理图和介绍等详细资料概述2018-07-30 1359
-
python的内置函数详细资料概述2019-11-18 838
-
EMC HF垫圈的详细资料概述2020-09-07 889
全部0条评论

快来发表一下你的评论吧 !
