

一文解析Git文件的三种状态
描述
Git作为大家熟悉的,深受欢迎的版本控制工具,和其他同类工具有很多不同之处:
Git始终保存快照而不是文件差异。
任何数据存储前始终使用SHA-1计算校验和,保证内容完整性。
使用分布式仓库设计,让大多数操作都在本地进行,保证了使用效率。
几乎所有操作都是向数据库增加数据,提交之后就很难丢失数据。
它的本质更像一个内容寻址(content-addressable)文件系统,并在此之上提供了一个版本控制系统的用户界面。
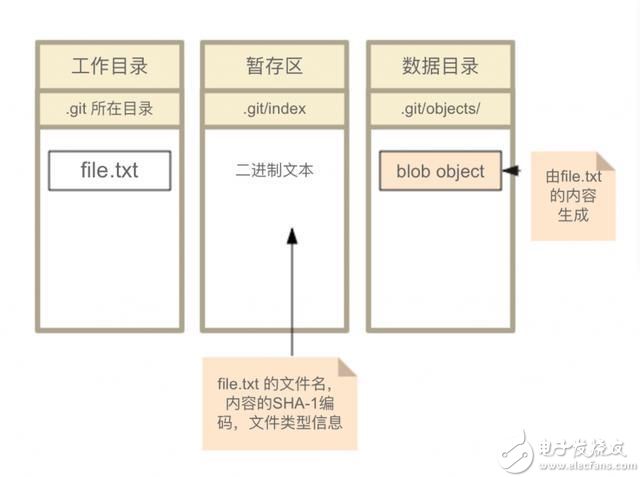
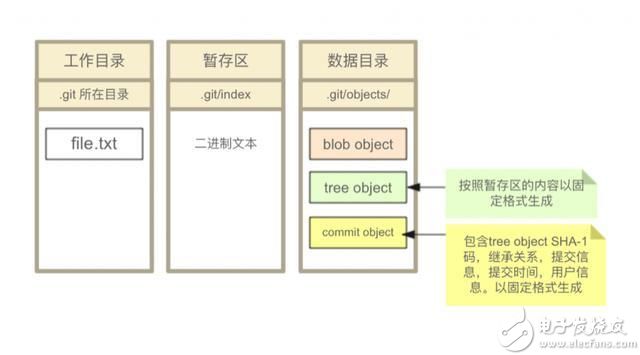
Git 有三种状态,你的文件可能处于其中之一:已修改(modified)、已暂存(staged)、已提交(committed)。由此引出三个逻辑区域,他们和文件状态以及部分对应操作的关系如下图。
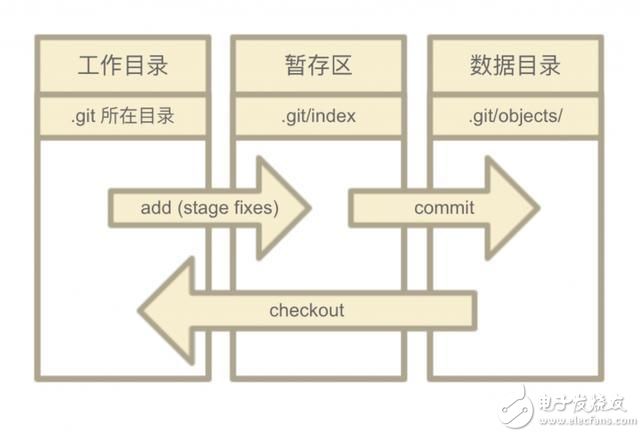
高层命令和底层命令:Git 最初是一套面向版本控制系统的工具集,它包含很多用于完成底层工作的命令。这些命令被设计成能以UNIX 命令行的风格连接,或由脚本调用来完成更复杂的工作。这部分一般被称作“底层(plumbing)”命令,那些对用户更友好的命令则被称作“高层(porcelain)”命令。
下面新建两个空仓库A 和B,来观察隐藏在Git常见命令下的实际执行过程。
1.git init
此命令初始化一个新本地仓库,它在工作目录下生成一个名为.git的隐藏文件夹。

查看该文件夹结构:
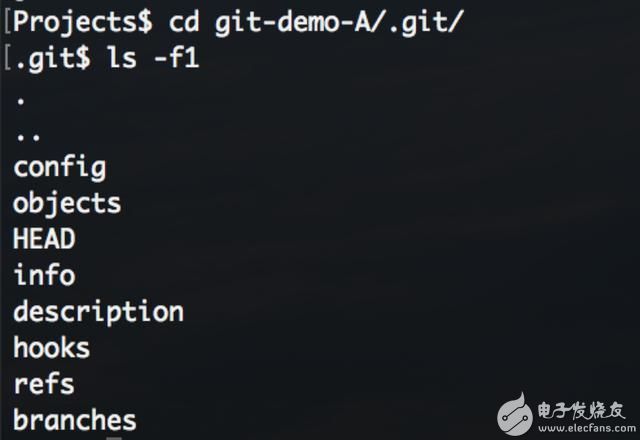
config//文件- 包含一些配置选项
objects//目录- 存储所有Git的数据对象
HEAD//文件- 指定当前分支
info //目录- 存放项目信息,默认包含一个全局exclude文件, 用来放置不希望记录在.gitignore 中的忽略模式
deion//文件- 仅供GitWeb 程序使用
hooks //目录- 存放可在某些指令前后触发运行的钩子脚本(hook s),默认包含一些脚本样例
refs//目录- 存储各个分支指向的目标提交
branches //目录- 还没发现有什么用处
.git 目录下可能还会包含其他文件,不过对于一个全新的仓库,这将是你看到的默认结构。
其中有四个条目很重要:HEAD 文件、(尚未创建的)index 文件,和 objects 目录、refs 目录。这些条目是Git 的核心组成部分。
本地仓库刚刚新建,Git的三个区域都为空。
2.git add
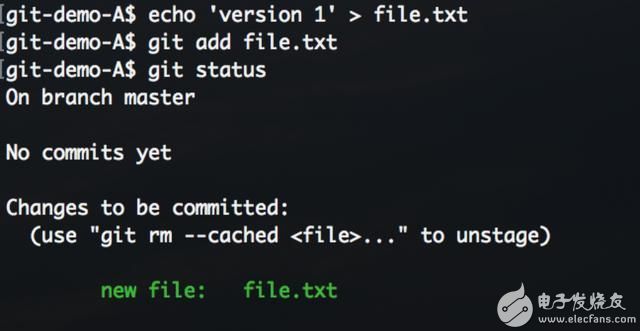
在A仓库的工作目录创建一个文件file.txt,写入内容version 1,模拟需要管理的代码文件。
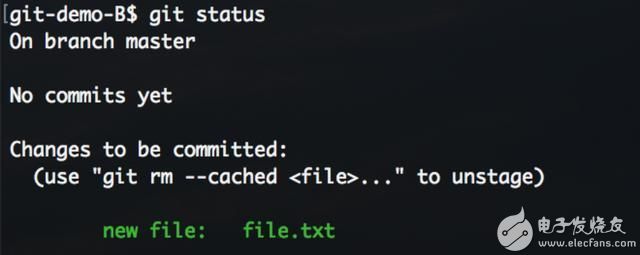
执行git add,使用git status查看此时的状态。
然后另外初始化一个空仓库B,尝试用底层命令来实现以上效果。
创建相同内容的file.txt,执行 git hash-object,计算文件头部信息+文件内容的SHA-1编码,执行后显示出40位的编码结果。-w参数表示将内容写入数据目录。

查看写入到数据目录的Git对象文件:

Git以SHA1编码前两位作为子目录名,剩余位数作为文件名,存储压缩后的头部信息和原文内容。
可以通过 cat-file 命令查看原始数据。为 cat-file 指定 -p 选项可使该命令自动判断源文件类型。

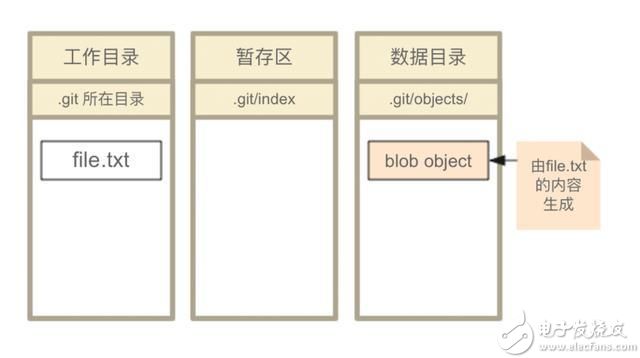
这种存储了数据原文的文件在Git对象中属于blob (Binary Large Object)类型。
此时Git的区域状态如下:
使用git update-index 命令可以修改暂存区,也就是.git/index文件。
由于此文件在暂存区没有记录,需要--add参数。
使用--cacheinfo参数,直接写入数据文本。如果不加此参数,仅使用git update-index --add file.txt 的方式,则与add命令效果完全相同。

本例中,我们指定的文件模式为100644,表明这是一个普通文件。其他选择包括:100755,表示一个可执行文件;120000,表示一个符号链接。Git的文件模式参考了常见的UNIX 文件模式,但比真正的文件系统简单许多。
此时暂存区index文件已经生成,直接打开会看到二进制字符,可以用 ls-files 命令解析查看。

显示出刚刚写入的内容。
此时Git的区域状态如下:
使用git status 查看,此时和A仓库状态相同。
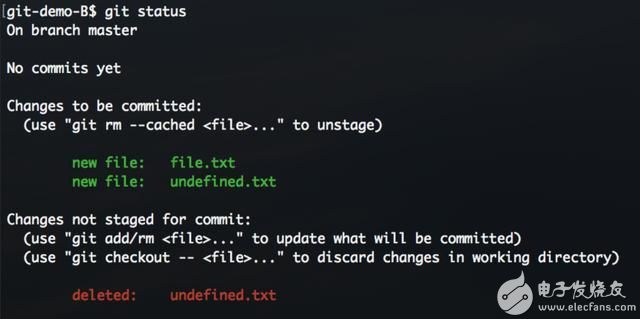
另外,由于 update-index --cacheinfo是直接写入文本,我们也可以添加完全不存在的对象名和文件名。

此时B仓库的状态:
3.git commit
回到A仓库,在git add 的基础上调用commit生成一个提交。
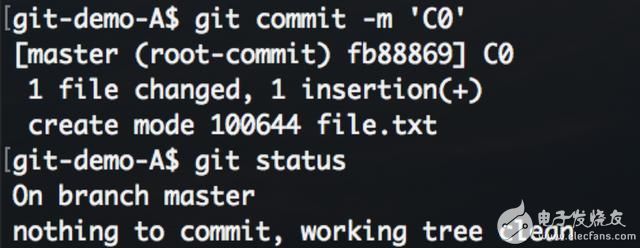
再查看暂存区:

与status的提示不同,提交操作并不会实际清空暂存区,其中始终保存着工作目录的文件结构。
再查看对象文件夹,发现两个新增文件。

接下来我们在另一个仓库重现这个操作。
回到B仓库,继续执行 git write-tree。

git 会在此时检查暂存区内容和数据目录中对象的对应关系,刚刚添加的不存在的文件导致失败。
git update-index --remove 命令可以从暂存区删除这条信息,只有在工作目录中不存在此文件时,才允许从暂存区直接删除相关信息。

write-tree 执行成功后同样返回40位哈希值,此命令将暂存区内容写入数据目录,生成一个 tree类型的对象。此对象也可以使用cat-file 命令查看。

使用刚刚生成的tree 对象来继续生成commit 对象,查看内容。
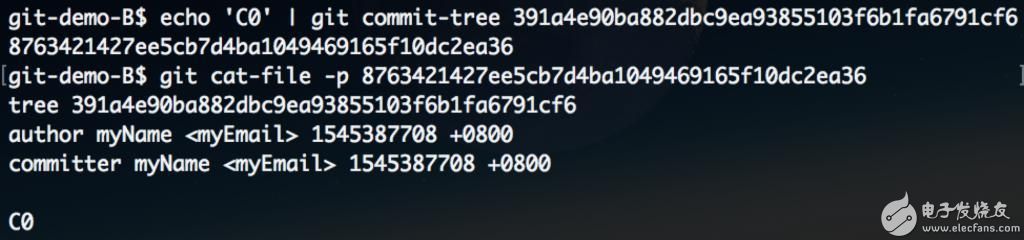
其中用户信息使用 git config user.name 和 git config user.email 设置,仅对当前仓库生效,如未指定则使用全局配置。
查看对象目录:

和A仓库直接git commit生成的文件对比,发现其中一个文件名不同。这是由于commit对象中包含执行时间信息,导致生成了不同的哈希编码。
使用log命令可以看到一个普通的commit信息。
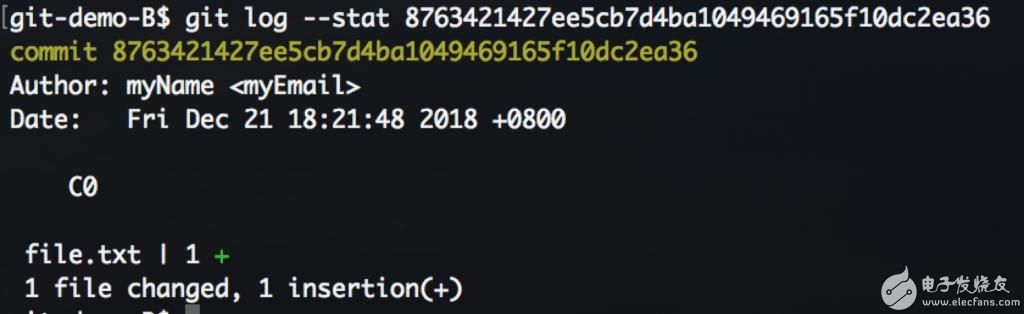
此时Git工作区域的状态:
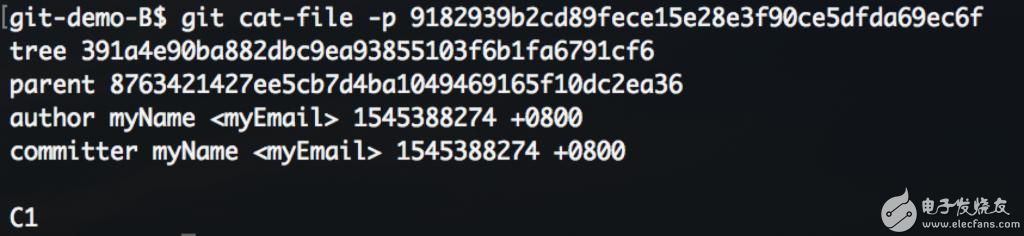
继续使用唯一的tree对象创建另一个提交。-p参数指定继承关系,作为标识符的hash值冲突概率较低,在git命令中通常使用前几位简写表示。
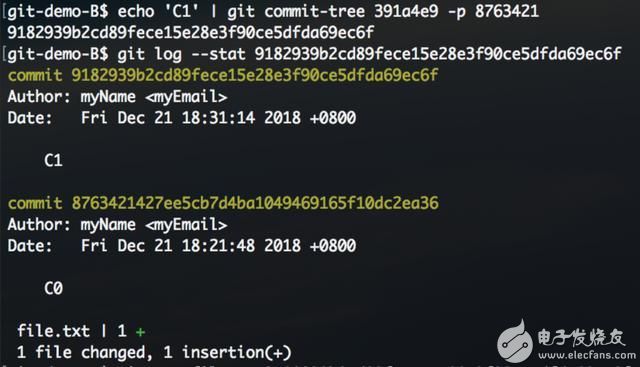
有继承关系的commit对象多出一条parent信息:
4.refs和HEAD
回到A仓库,使用commit 增加C1提交。

检查到暂存区并未修改,提交失败。可以使用 --allow-empty 参数放弃检查。生成以下log。
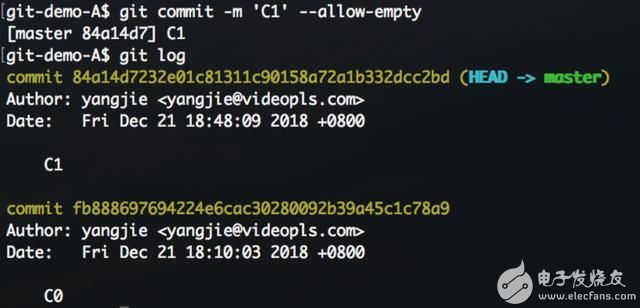
可以发现,打印的log信息和B仓库略有不同,并且B 仓库查看log时必须指定commit对象编码。如果不指定就会出现以下错误。

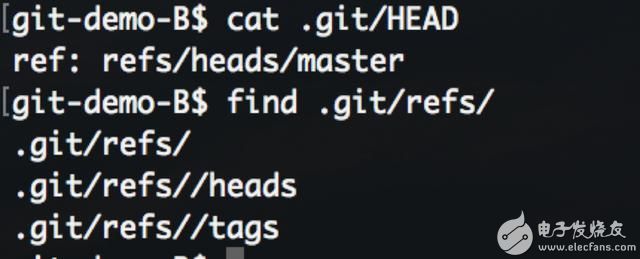
原因是之前用底层命令生成的提交链并不属于任何分支。分支的本质是指向commit对象的指针,hash编码无意义难以记忆,分支名更方便灵活管理。
而HEAD 文件中保存着当前工作目录所在的分支,可以看到在B 仓库中,HEAD 指向默认分支master,而 master 文件还不存在。
可以手动生成 master文件,并指向最新提交。
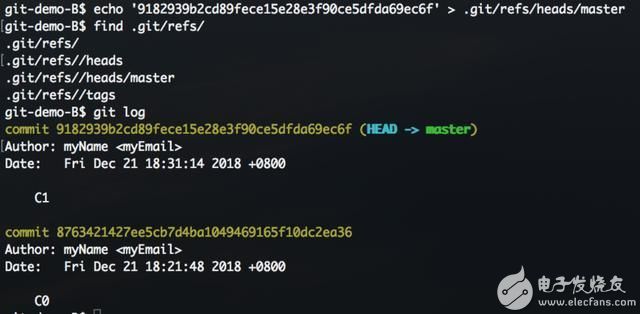
虽然可以直接修改分支文件的内容,但这是一种不安全的做法,可以使用git update-ref 命令来达成同一效果。
此时B仓库和A仓库的状态就完全一致了。
-
三极管的三种工作状态2008-07-14 0
-
labview如何实现圆环三种状态显示?2018-03-02 0
-
三种工作状态的三极管分别有什么区别?2019-03-05 0
-
进程类型及三种状态2021-04-02 0
-
关于TFT-LCD的三种广视角技术解析,不看肯定后悔2021-06-04 0
-
STM32的三种启动模式2021-08-05 0
-
STM32应用的三种框架应用代码2021-08-10 0
-
如何使用三种方式进行文件的创建2021-12-15 0
-
STM32的三种Boot模式的差异2021-12-20 0
-
什么是状态机?状态机的三种实现方法2021-12-22 0
-
介绍一下引脚的三种状态2022-01-14 0
-
分析下单片机 IO口的三种状态2022-02-28 0
-
关于Git教程解析2022-04-27 826
-
继电保护的三种状态解析2023-09-27 1849
-
Git是如何存储文件的?Git的工作原理解析2023-10-31 383
全部0条评论

快来发表一下你的评论吧 !
