

基于Kubeflo的应用与开发
电子说
描述
本文将介绍以下三部分内容:第一:Kubeflow 的应用;第二:基于 Kubeflow 的开发;第三:Momenta 深度学习数据流。
ubeflow 的应用
为什么要用 Kubeflow?
在一些 GPU 集群较小的机构(例如实验室、科研机构等)中,他们一般只有几台多卡 GPU。实验人员可能会将一台机器或两台机器用于安装各种环境以及 GPU 的驱动,同时使用 Caffe 或 TensorFlow 等工具做模型训练。这种场景较为简单,但会带来一个问题,即人员需要花大量精力管理这几台机器的环境。
为了解决这个问题,降低用户的部署成本,技术人员可以引入容器技术,用 nvidia-docker 允许容器使用 GPU,将 TensorFlow、PyTorch 以及 Caffe 封装到 Docker 镜像中,用 nvidia-docker 在物理机上面运行训练任务。
但是以上只是小规模 GPU 集群中的解决方法,一旦集群规模扩大,实验人员就不得不需要解决这些问题:如何合理地分配 GPU 资源?如果让每位用户直接在每台机器上获取资源?技术人员如何进行资源管理、环境维护?2017 年年底发行的 Kubeflow 很好地解决了这些难题,它将训练任务装到容器中,利用 Kubernetes 对 CPU、GPU 等资源进行充分管理。
什么是 Kubeflow?

Kubeflow 可以看作是 Kubernetes + TensorFlow 的成果。它是一个基于 Kubernetes 的机器学习工具项目,支持众多训练框架,包括 TensorFlow、PyTorch、Caffe2、MxNet 等。
Kubeflow 社区在半年多的时间内收集了 4000 多个 stars,发展非常迅速。同时,众多国内公司也助力了 Kubeflow 的发展,贡献了很多项目。例如才云贡献的 tf - operator 项目,Momenta 贡献的 caffe2 - operator 项目。新浪、京东和拼多多也在尝试使用 Kubeflow 解决问题。
在 Kubernetes 里部署 Kubeflow 的方法有很多,常规方法是用 ksonnet 或单独用 kubectl 手动部署各个 Operator 以及相应的服务。个人用户也可以很方便地体验用 Kubeflow 轻松部署一套用于训练模型的环境。
# CNN_JOB_NAME=mycnnjob # VERSION=v0.2-branch # ks registry add kubeflow-git github.com/kubeflow/kubeflow/tree/${VERSION}/kubeflow # ks pkg install kubeflow-git/examples # ks generate tf-job-simple ${CNN_JOB_NAME} --name=${CNN_JOB_NAME} # ks apply ${KF_ENV} -c ${CNN_JOB_NAME}
以上是直接从 Kubeflow 官网上获取的一个示例。以往在部署环境时,实验人员需要预装很多东西用于模型训练,但如果使用 Kubeflow,他们就可以很简单地跑一个已知数、已知模型。如果在其中加入一些参数,程序就可以跑整个 Kubeflow 的任务(仅以 TensorFlow 为例)。
# arena submit tf --name=tf-git --gpus=1 --image=tensorflow/tensorflow:1.5.0-devel-gpu --syncMode=git --syncSource=https://github.com/cheyang/tensorflow-sample-code.git --env=GIT_SYNC_USERNAME=yourname --env=GIT_SYNC_PASSWORD=yourpwd "python code/tensorflow-sample-code/tfjob/docker/mnist/main.py” # arena list NAME STATUS TRAINER AGE NODE tf-git RUNNING tfjob 0s 192.168.1.120
在这个实例中,arena 是另外一套基于 Kubeflow 的封装,相当于简化版本的命令行。arena 能帮助算法研发人员减少对 kubectl 的使用,通过命令行指定各种算法参数以及要运行的脚本,直接运行 arena submit 来提交训练任务。
基于 Kubeflow 的开发
为了满足不同场景需求,目前 Kubeflow 已经拥有许多解决方案,但它们大多比较简单。如果训练数据集较大,需求较复杂,开发任务将会涉及很多块 GPU 的使用(例如用 128 块 GPU 训练很多天)。

接下来,我们尝试搭设一个深度学习实验平台。这里需要注意的是,我们定义的是 “实验平台”,因为 Momenta 的算法研究人员在调参、看论文时需要测试各种各样的网络。对他们而言,深度学习实验平台非常重要,而且要满足多种需求。
第一:实验平台需要多机多卡调度。比如研发人员有调度 128 块卡的需求,如果卡不足,就需要等待调度;
第二:多租户。在多用户的环境下共用相同的系统或程序组件,且仍可确保各用户间数据的隔离性;
第三:多训练框架支持。比如 Caffe、TensorFlow、PyTorch 等;其他的还有日志收集、监控信息收集(如 GPU 的使用率)等。
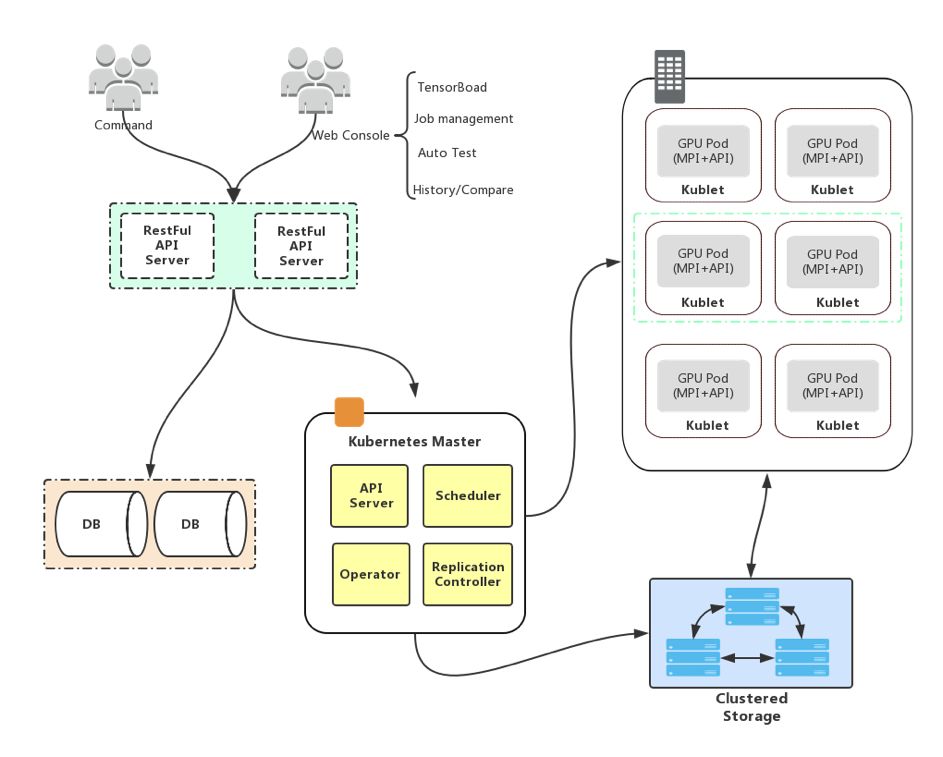
考虑到以上需求,我们设计了一个训练平台架构,如上图所示。我们在 Kubernetes 前面加了一个带状态的 apigateway,它包含用户信息、状态管理、后期审计等功能。架构还包括 caffe2 - operator、mpi - operator 和 TensorFlow 的 Operator,主要是为了能够统一管理训练任务的生命周期。此外,该架构还支持运用 kube - batch 实现多机多卡的调度期。图中的假设比较简单,每个 Pod 都是一个单独的机器。
如何实现多台机器间的通讯也是框架的重点。该设计分为两套环境:
线下的环境使用 Infiniband,借助高速的 RDMA 网络就能很好地解决延迟问题,并提供非常高的带宽;
线上的环境使用 25Gb/s 的以太网,其相对于 Infiniband 延迟过高,所以在多机通讯的过程中,需要包一个聚合再下发,才能解决延迟问题。
底层的数据存储也需要使用分布式数据存储以及图像缓存,基于 Momenta 的数据的特征(不需要对图片进行修改),用户可以在客户端加上一些缓存。比如在客户端安装高速 SSD,使用开源的 fscache 把数据缓存到 SSD 上,保证整个训练过程中数据的高速传输。用相对比较便宜的 SSD 确保昂贵的 GPU 的充分使用,这是 Momenta 整套训练平台的架构的最大优势之一。

对具有一定操作经验的用户而言,他们更喜欢以命令行的方式操作,习惯用 HPC 领域的 slurm 作为操作工具。为了兼容 slurm 的命令行,Momenta 形成了一套类似 slurm 管理命令行的操作方式。同时,平台也提供 Web 端的操作方式。

上图是一个任务提交的案例,包括以下几点:
定义了几个节点;
每个节点需要几个 GPU;
基于哪些的框架(如 TensorFlow、PyTorch 及 Caffe2 等);
当前的工作任务。
我们之所以做出这样的设计,一个原因是为了兼容旧的使用习惯,让老用户能够无缝迁移。另一个原因是重新设计一套交互方式的时间成本太高,基础架构开发人员需要花很长时间才能了解平台用户在进行深度学习研发的操作行为和操作意图。
Momenta 深度学习数据流
在实现自动驾驶的过程中,深度学习算法在训练模型时需要大量图像数据作为支撑。Momenta 平台可以处理自动驾驶领域的数据流。
数据筛选
上图是车辆识别的(电动车)的一个典型。目前,Momenta 在电动车识别上准确率较高。在人工智能数据流中,数据筛选有以下作用:
降低成本:无需重复标注即可识别素材,降低标注成本。
提高模型训练效率:去除无效素材,提取包含识别目标的素材,提高训练效率;
提高模型训练边际效用:通过对极端情况(corner case)的数据进行针对性训练,有效地提高模型性能。
数据标注
经过一轮筛选后,部分图片会需要人工标注。Momenta 开发的在线远程众包数据标注系统允许可视化操作,即便不懂代码的众包人员也能远程完成各类标注任务。数据标注的作用主要是提供更多带标注的图像数据,提供包含更多识别目标的素材,最终提高模型训练精度。
模型训练
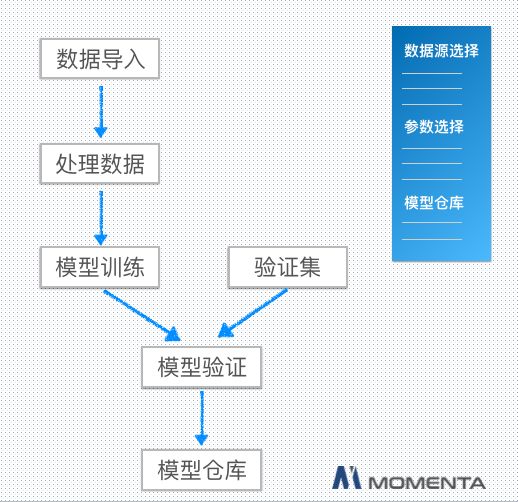
上图是模型训练的流程图:
数据导入:支持多种数据类型,支持多批次数据合并,支持多种组合规则;
模型训练:多机多卡并发训练,共享式集群、支持多人多任务同时进行,支持多种主流训练框架,所有任务由 Kubernetes 自动调度完成;
模型验证:训练所得模型自动在验证集上进行验证,通过验证的模型将进入模型仓库供后续流程使用;
与传统方式相比,Momenta 采用的共享集群调度让用户(内部的算法研发人员)可以编写任务描述和训练脚本,而管理员通过网页界面进行集群管理和工作调度。极大地节省人工成本,提高资源利用率,实现集中性管理,提高安全性。
结语
Kubeflow 基于 Kubernetes 和 TensorFlow ,提供了一个数据科学工具箱和部署平台。它具有很多优点,如 DevOps 和 CICD 的支持、多核心支持等。但它的缺点也很明显,就是组件较多,协调较差。
如何利用 Kubeflow 更好地做二次开发?这是当下的一个热点问题,也是 Momenta 致力于解决的一大问题,是我们围绕不同级别自动驾驶方案和一级供应商展开合作时首先要解决的一个必要问题。为了见证自动驾驶汽车的落地,为了共同打造更好的人工智能自动驾驶产品,欢迎有想法的小伙伴与我共同探讨基于 Kubeflow 的深度学习。
-
stm32开发板开发板原理图2015-12-21 1565
-
开发板是什么_开发板有什么用_开发板怎么用(使用步骤教程)2017-12-09 104781
-
app开发是该选择原生开发还是混合开发呢2018-12-30 424
-
Java开发和嵌入式开发该如何选择2019-06-10 1848
-
如何看待Java开发和嵌入式开发2019-06-15 2613
-
什么是低代码开发?低代码开发有什么好处2020-04-02 2732
-
2021 OPPO开发者大会:更容易的开发2021-10-27 2400
-
单片机开发与Linux开发区别2021-11-13 633
-
单片机开发与Linux开发有何不同?2021-11-13 483
-
使用 rust 开发 stm32:开发环境搭建2021-11-18 1168
-
STM32驱动开发(一)--串口原理与开发实践2021-12-08 405
-
ARM-Linux应用开发和单片机开发的不同2022-03-23 1949
-
使用开发Arduino的方法开发STM322022-08-09 556
-
迅为国产开发板值得入手的三款开发板2022-07-12 1283
-
新唐开发平台黄金3部曲:第1部,开发2023-08-09 420
全部0条评论

快来发表一下你的评论吧 !
