

便携式设备的多核设计解决方案
描述
一开始有手机,它们很好 - 好吧,允许它们的大小和重量的砖块,只能做一件事:拨打电话。今天的蜂窝手机是21世纪的微型计算机,能够运行无数的“应用程序”,流式传输高清视频和高质量音频,捕捉和处理1200万像素图片,并仍可拨打电话。
尽管摩尔定律,对单个处理器要求很高,尤其是需要长时间使用小电池供电的处理器。手机长期以来一直使用独立的应用处理器来卸载主处理器的工作。然而,随着ARM最近推出其big.LITTLE方法 - 以及NXP在低功耗双核(M4/M0)嵌入式MCU中实现它 - 其他便携式设备中的非对称多核处理器(AMP)的转变看来已经设定为迅速从利基走向主流。
德州仪器的OMAP和DaVinci
德州仪器的OMAP™SoC长期以来一直是蜂窝手机中的主要应用处理器。由于流式视频和音频最好由数据路径中的DSP处理,因此OMAP SoC都将通用ARM®处理器与TI DSP相结合。
最初的130 nm OMAP 1系列 - 例如OMAP5912ZZG - 配对192 MHz ARM926EJ-S™和TMS320C55x™DSP内核。内部总线结构 - 一个程序总线,三个数据读总线,两个数据写总线以及用于外设和DMA活动的附加总线 - 有效地使DSP能够在一个周期内执行最多三次数据读取和两次数据写入,相对较高高速视频和图像处理。
向下移动到65 nm,OMAP 3系列显着提高了速度。例如,600 MHz OMAP3530DZCBB将ARM926EJ-S升级为Cortex™-A8; C55x™DSP到TMS320C64x™;并添加了POWERVR™SGX图形加速器和NEON™SIMD协处理器。虽然大多数OMAP 3系列SoC直接销售给手机OEM,但OMAP3530是针对嵌入式开发人员的目录项目。 TI在Digi-Key的网站上提供了一系列OMAP3530培训视频。
继续提高赌注,TI的45纳米OMAP 4平台转向支持对称多处理(SMP)的双核ARM Cortex-A9 MPCore™处理器;切换到基于C64x™DSP的可编程多媒体引擎;增加了IVA 3硬件加速器;并升级到POWERVR SGX540 3D图形加速器(参见图1)。考虑到高端应用,OMAP4460可以提供1080p多标准视频记录和回放以及立体3D编码/解码。虽然TI利用这些芯片中的几乎所有电源管理技巧,但人们不应期望能够在不给手机充电的情况下整天进行高速在线3D游戏。希望评估OMAP4460的开发人员应该查看流行的SVTronics的Pandaboard ES。
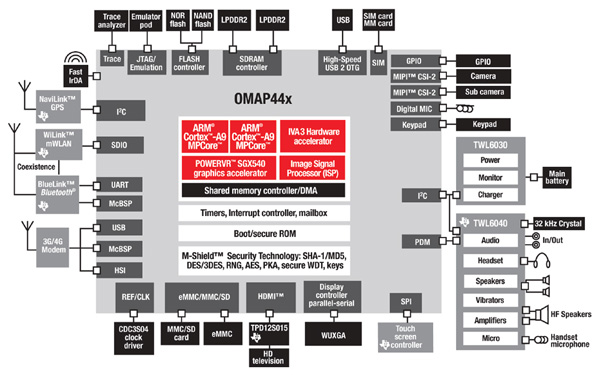
图1:德州仪器的OMAP44x框图(由德州仪器公司提供)。
虽然TI的OMAP 5系列 - 围绕ARM的双核Cortex-A15和两个Cortex-M4构建 - 显然对服务器比对手机更感兴趣,但是来自DaVinci™系列视频处理器的OMAP-L138又向后移动了考虑到便携设备的功率曲线。 OMAP-L138采用ARM926EJ-S RISC MPU和TMS320C674x固定/浮点VLIW DSP,运行温度为375/456-MHz。与DaVinci芯片相比,OMAP-L138支持更宽,更少视频的外设,并包含浮点DSP。 TI推出OMAP-L138实验套件,您可以在此查看。
如果您的项目更加面向视频,那么DM644系列双核DaVinci DSP可能只需支付费用。 TMS320DM6446包括一个运行频率高达405 MHz的ARM926EJ-S内核和一个运行频率高达810 MHz的VLIW TMS320C64x + DSP内核。该芯片可用于DM6446评估模块的在线测试。
ADI公司的Blackfin设计公司专为低功耗便携式应用而设计,ADI公司的Blackfin®是一款令人尊敬的处理器,就好像它是双核处理器 - 其中一些实际上是。 Blackfin系列与英特尔共同开发,包含各种小型16/32位RISC处理器,运行频率范围为300至600 MHz。该处理器基于SIMD架构,具有两个16位MAC,两个40位ALU和一个扁平地址空间。每个MAC可以在每个周期中执行16位乘16位乘法,并且包括特殊指令以加速各种信号处理任务;所以Blackfin可以执行控制功能并同时充当DSP。 ADI声称Blackfin显示出“同类最佳的MHz/mW性能”,尽管这已成为每个人都在追逐的激烈竞争指标。
ADSP-BF561SBBZ600(见图2)是一款真正的双核设备,包含两个600 MHz Blackfin内核,每个内核有两个16位MAC,两个40位ALU,四个8位视频ALU,一个40-位移寄存器,128 KB低延迟片上L2 SRAM和外部存储器控制器。这是一款针对各种多媒体,工业和电信应用的对称多处理器(SMP)设备。
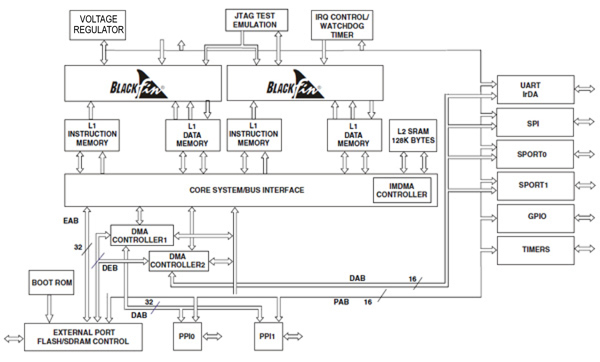
图2:ADI公司的ADSP-BF561功能框图(由Analog Devices提供)。
飞思卡尔半导体的QorIQ
飞思卡尔QorIQ™P1022是一款SMP处理器,围绕两个Power Architecture™e500v2内核构建,共享一个256 KB的L2缓存(参见图3)。 P1022明确强调连接性,包括带TCP/UDP/IP卸载的虚拟化增强型三速以太网,用于ASIC连接的直接FIFO模式,用于本地存储的SATA,支持三种PCI Express接口选项,以及通常的USB,SPI ,多个GPIO等.QorIQ P1022NSN2LFB的运行频率为1055 MHz,具有双精度浮点单元。 P1平台概述培训模块介绍了处理器系列,P1022多核开发系统让您可以亲身体验该芯片。
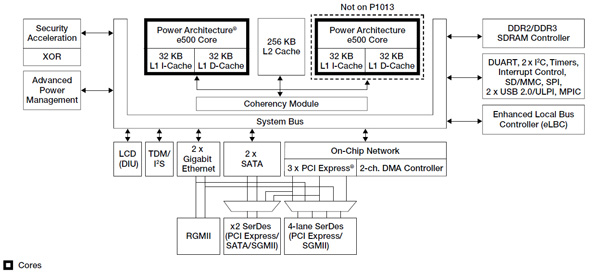
图3:飞思卡尔半导体的QorIQ P1022框图(由飞思卡尔提供)。
恩智浦的LPC4350
最新进入低功耗多核市场的是恩智浦的LPC4350,它被称为“世界上第一款双核心DSC”。遵循ARM的“big.LITTLE”方法 - TI采用了同样的方法其OMAP 5系列使用Cortex-M4s和Cortex-A15s - NXP结合了Cortex-M4和Cortex-M0内核,功耗更低的LPC4350。
为了最大限度地降低功耗,204 MHz LPC4350使用Cortex-M0内核尽可能从Cortex-M4卸载工作,Cortex-M4根据需要快速突发数据。 LPC4350的连接选项明显针对嵌入式市场,包括CAN,EBI/EMI,以太网,I²C,微线,SD/MMC,SPI,SSI,SSP,UART/USART和USB OTG;内置外设包括掉电检测/复位,DMA,I²S,LCD,电机控制PWM,POR,PWM和WDT(见图4)。
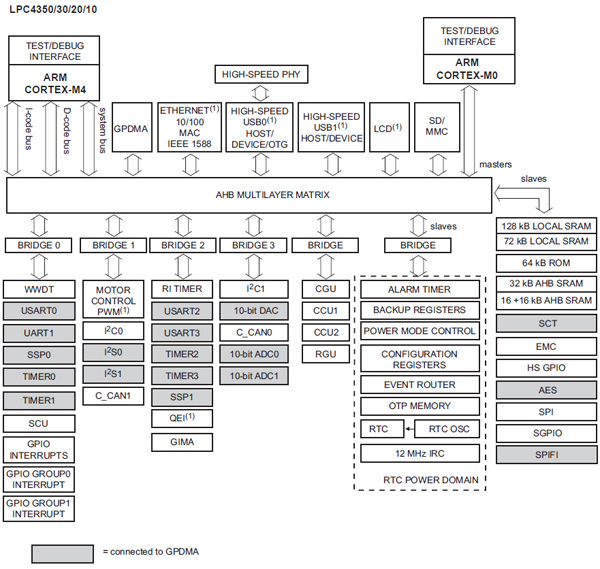
图4:恩智浦半导体的LPC4350框图(由NXP Semiconductors提供)。
LPC4350增加了两个有趣的新功能:状态可配置定时器(SCT)和四SPI闪存接口(SPIFI)。 SCT子系统位于AHB总线上,由两个16位计数器或一个32位计数器组成,可通过总线时钟或外部输入进行时钟控制。 SCT支持跨多个计数器周期进行排序,并使事件能够控制输入,输出和其他事件。 SPIFI接口可以以高达每秒40 MB的速度向外部闪存传输四个数据通道,这是一种独特且非常有用的技巧。
总而言之,LPC4350是进入低功耗多核市场的一个有趣的新进入;一个提高了其他人必须满足的标准。但是那些产品可能已经在筹备中,这将继续使这个市场更加有趣。
ARM的big.LITTLE架构
由于本文中提到的所有供应商都是ARM许可证持有者,因此可以安全地假设ARM的路线图将在相当短的时间内在硅片中发挥作用。该路线图的最新主要补充 - 去年10月宣布 - 是对多核处理器的‘big.LITTLE’方法。即使是飞思卡尔,其Power Architecture许可证也已正式签署。恩智浦已经发布了第一款基于big.LITTLE的芯片,虽然不是ARM去年年底提出的版本。
ARM的第一个big.LITTLE设计将Cortex-A15与Cortex-A7配对。 big.LITTLE的核心原则是两个核心必须在架构上基本相同,以便所有指令在两个核心上都能一致地执行。 Cortex-A15和Cortex-A7都共享完整的ARM v7A架构,包括虚拟化和大型物理地址扩展,因此在微架构级别之上,它们完全兼容。 Cortex-M4和Cortex-M0也是如此。只要保持这种对称性,SoC就可以包含任意数量的匹配big.LITTLE内核。
Cortex-A15 vs Cortex-A7
性能Cortex-A15 vs Cortex-A7
能效Dhrystone 1.9x 3.5x FDCT 2.3x 3.8x IMDCT 3.0x 3.0x MemCopy L1 1.9x 2.3x MemCopy L2 1.9 x 3.4x
表1:Cortex-A15和Cortex-A7性能和能量比较(由ARM提供)。
在微体系结构层面,Cortex-A15的管道比Cortex-A7复杂得多,它们的性能也大不相同(见表1)。 Cortex-A15倾向于权衡性能,而Cortex-A7倾向于相反;这些差异将倾向于确定应用程序分区。
Cortex-A15和Cortex-A7通过CCI-400(高速缓存一致性互连)共享内存和系统端口,如图5所示,尽管每对内核共享一个集成的二级高速缓存。 Cortex-A15和Cortex-A7对共用一个可编程通用中断控制器(GIC-400),可在各种内核之间分配多达480个中断。针对主要的多核障碍,Cortex-A15和Cortex-A7均提供跟踪解决方案,使程序员能够使用ARM的CoreSight™SoC调试其代码。
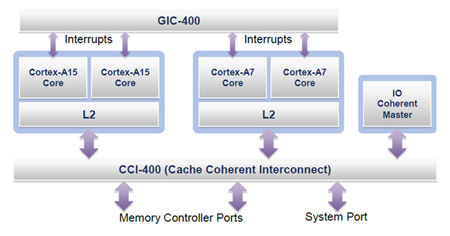
图5:Cortex-A15 CCI Cortex-A7系统(由ARM提供)。
ARM使用big.LITTLE的方法涉及使用Cortex-A7进行尽可能多的处理,只在需要性能时将任务迁移到Cortex-A15,将操作系统和应用程序移动到更快的核心。 ARM处理器工作频率为1 GHz时,可以在不到20微秒的时间内完成这种迁移。这是可能的,因为两个处理器是相同的,并且入站和出站处理器中的状态寄存器之间存在1:1映射。
总而言之,ARM的big.LITTLE方法似乎在逻辑上和架构上都很有意义。通过使用相干高速缓存并自动执行中断处理和存储器访问,这种架构可能会为今年晚些时候点击分销渠道的便携式设备带来新一波多核处理器。这不能保证,但这是一个非常好的选择。
-
便携式电源解决方案2008-07-27 0
-
LCD在无线/便携式设备中的应用2009-12-11 0
-
电源IC在便携式移动设备领域的应用2015-09-29 0
-
AMEYA360设计方案丨便携式超声仪解决方案2018-07-19 0
-
便携式手持设备解决方案参考指南2018-10-23 0
-
适用于便携式相机的完整电源解决方案2019-03-15 0
-
基于高性能模拟器件的便携式医疗设备2019-07-09 0
-
FPGA助力便携式存储应用的实现2019-07-16 0
-
基于FPGA的便携式存储应用2019-07-19 0
-
低功耗MCU系统在便携式设备的应用2019-07-19 0
-
便携式UPS电源的相关资料推荐2021-11-16 0
-
针对便携式设备的电源管理方案2021-11-17 0
-
加强便携式设备中的背光照明解决方案2010-03-07 872
全部0条评论

快来发表一下你的评论吧 !
