

如何采用处理器和FPGA设计机器学习的计算平台
描述
对于开发人员而言,机器学习(ML)硬件和软件的进步有望将这些复杂的方法带入物联网(IoT)边缘设备。然而,随着这一研究领域的发展,开发人员可以轻松地发现自己沉浸在这些技术背后的深层理论中,而不是专注于当前可用的解决方案,以帮助他们将基于ML的设计推向市场。
本文简要回顾了ML的目标和能力,ML开发周期,以及基本完全连接神经网络和卷积神经网络(CNN)的体系结构。然后讨论了支持主流ML应用程序的框架,库和驱动程序。
最后展示了通用处理器和FPGA如何作为实现机器学习算法的硬件平台。
ML简介
人工智能(AI)的一个子集,ML涵盖了广泛的方法和算法。作为一种强大的数据分类技术或在数据流中寻找感兴趣的模式,它迅速受到关注。已经出现了广泛的算法来解决特定类型的问题。
例如,聚类技术和其他无监督学习方法可以揭示大型数据集中不同类别的数据。强化学习提供了能够探索未知状态并选择替代解决方案的方法,目的是学习识别这些状态并在将来适当地做出响应。最后,监督学习方法使用表示所需输出的预备输入数据来教授算法如何对新输入数据进行分类。
监督学习方法通过使用精心准备的训练集来获得他们的名字,这些训练集将输入数据配对(称为特征向量),具有预期输出(称为标签),以训练算法模型,以便将来对未标记的输入数据模式进行分类。例如,开发人员可能有几个特征向量,包括不同的采样传感器值集合,这些值都代表某些工业过程中的安全条件,以及其他特征向量及其自身的传感器样本都表示不安全的情况。
监督学习方法可以使用这些代表性特征向量及其已知的安全/不安全标签来训练算法,以基于新的传感器值识别其他安全和不安全的条件。
神经网络
有监督的学习方法,神经网络算法已迅速获得其准确分类数据的能力。基本神经网络有三个阶段(图1)。第一个是输入层,其包括输入特征向量中的每个特征的输入。第二个是隐藏的一些神经元层,它们以不同的方式转换这些特征。第三层是输出层,其将该变换的结果呈现为一组概率,输入特征向量可以用训练期间提供的标签之一进行分类。
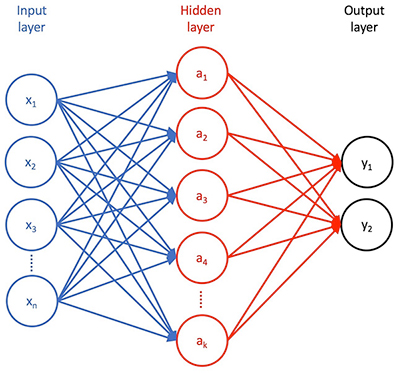
图1:神经网络包括输入层,一个或多个隐藏转换层,以及呈现该转换结果的输出层。 (图像来源:Digi-Key Electronics)
此外,一层神经元与后续层神经元之间的每个连接都有一个相关的权重,有效地代表了该特定连接的相对强度。
在完全连接的神经网络中,每个i输入神经元呈现其特征值xi,通过与下一个隐藏层中的每个目标神经元aj相关联的加权因子wij进行缩放。每个隐藏层神经元aj对加权输入w1jx1 + w2jx2 + ... + wnjxn(和一些偏差值)求和,然后应用一些激活函数,该函数缩放或以其他方式减少呈现给附加到其输出的神经元的求和结果。此过程通过其他隐藏层和最终输出层重复,其中该减少的值表示输入要素向量[x1,x2,... xn]可被分类为标签y1或y2的概率(对于图1所示的简单网络)训练过程通过调整权重和偏差值(统称为模型的参数)来改进模型以实现训练集向量与其相关标签之间的最佳匹配。通常以一组随机模型参数开始,训练算法通过模型重复传递训练数据集。对于每个完整的传递或纪元,训练算法试图减少预测标签和已知标签之间的差异 - 在每个时期由某种类型的特定损失函数计算的差异。
表示为函数在模型参数中,损失函数描述了与这些参数相关联的多维空间中的表面。因此,经过良好调整的训练过程基本上可以找到从起点(初始随机模型参数)到多维参数空间上最小点的最快路径(图2)。
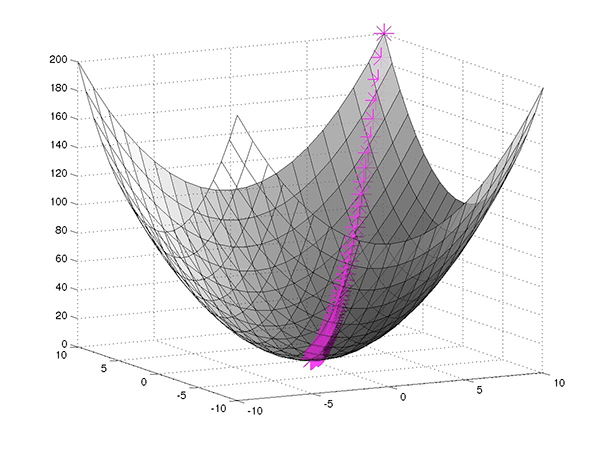
图2:神经网络训练寻求找到最小化损失函数的参数集(预期输出和计算输出之间的差异),使用梯度下降找到最小损失点的最快路径。 (图片来源:Mathworks)
在任何曲线上,从任何特定点到最小点的变化方向和速率当然由曲线上该点的切线斜率来描述,即其导数(或其中的偏导数)多维参数空间)。例如,对于在多维表面上具有值w和正偏导数p的某个假设参数,可以通过设置w = w-αp将参数移向最小值,其中α是一个术语,称为学习率,用于帮助避免p太大以至于wp单独跳过最小值而永不收敛的情况。
神经网络训练算法使用这种技术,称为梯度下降或其变化,在计算后修改模型参数每个时代的损失函数。通过计算每个时期的最小损失的最短路径,训练算法最终可以找到传递最小损失的特定模型参数,或者足够接近最小损失的模型参数,通过附加历元的迭代将对结果几乎没有增加。/p>
复杂神经网络
这种通用训练过程在概念上适用于任何神经网络,无论它是否类似于图1所示的基本架构,在深度神经网络(DNN)设计中增加了许多隐藏层,或使用完全不同的架构。开发人员可以找到任意数量的神经网络架构,旨在解决特定的应用问题。其中,CNN架构已成为图像识别的首选方法。
CNN设计用于需要高级识别图像,手写和其他复杂表示的应用,CNN使用管道方法学习重要特征在所提供的输入中,并在其输出处对这些特征进行分类(图3)。
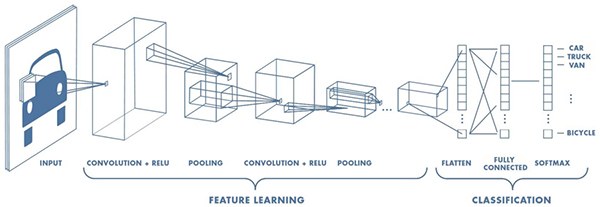
图3:CNN结合了一个功能学习阶段,包括通过多个感受域过滤图像的转换,以及将这些结果重新组合成分类阶段的分类阶段。最终输出层。 (图像来源:Mathworks)
CNN以用于预处理图像的输入层开始。特征学习阶段通常包括多层卷积,整流线性单元(ReLU)和池化功能,这些功能组合起来识别图像的边缘,颜色分组和其他独特元素等特征。
执行在这种识别中,卷积层用多组神经元检查图像的输入体积,称为深度列,它们都连接到输入图像中的相同局部区域(它们的感受野)并接收其所有颜色通道。为了产生卷积,这组神经元(称为滤波器或内核)将其感知场滑过图像。在此过程中,内核计算前面描述的相同类型的输入加权和。类似地,ReLU层用作前面描述的激活功能。池化层提供了一种专门的功能,可以有效地对从连接的内核接收的结果进行采样。
CNN的最终分类阶段重新连接所有单个内核输出,并生成输出,指示输入图像对应于在标记图像训练期间使用的特定标签之一的概率。
开发人员可以找到具体的CNN架构的例子,从原始的LeNet,AlexNet和CIFAR ConvNet等相对较浅的模型,到22层模型GoogleNet架构等大型模型,以及每年在ImageNet大规模视觉中常用的数百层的非常深的模型认可比赛。诸如此类的DNN能够进行显着的非线性变换,以提取特征并以非常低的错误率对复杂图像进行分类。
然而,直到最近,实施CNN的能力需要深入了解概率,统计和线性代数的基础数学至少是。今天,开发人员可以利用基于软件堆栈的复杂机器学习框架,显着简化包括CNN在内的复杂神经网络架构的实现。
ML框架
机器学习框架,如MATLAB for Machine学习,Microsite的认知工具包,Google的TensorFlow,三星的Veles以及许多其他人提供设计,训练和部署神经网络模型所需的资源。在这些框架内,开发人员使用机器学习库(如Keras或TensorFlow Estimators)来描述神经网络层并实现训练算法。反过来,这些库使用优化的数学库(如NumPy)来处理用于梯度下降和损失函数计算的复杂矩阵运算。对于这些操作所需的特定数值计算,这些库构建在较低级别的库上,例如Basic Linear Algebra Subroutines(BLAS)。为了加速训练,这些环境通常严重依赖于具有相应GPU启用库的一个或多个图形处理单元(GPU),例如NumPy兼容CuPy,BLAS兼容cuBLAS或NVIDIA自己的CUDA深度神经网络库(cuDNN)等。最后,这些不同的库利用甚至更低级别的驱动程序,包括跨平台OpenCL或NVIDIA CUDA,用于支持GPU的环境。
这种对数字数学处理优化库的深度依赖反映了矩阵操作在神经网络发展。特别地,一般操作,一般矩阵乘法(gemm),主导神经网络中使用的计算类型,特别是CNN(图4)。
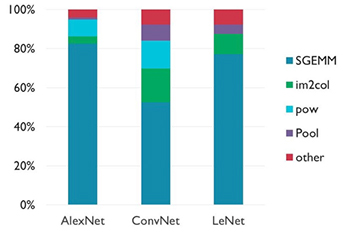
图4:虽然其影响的具体情况因CNN架构的不同而有所不同,但单精度浮动通用矩阵乘法(SGEMM)操作主导了培训和推理。 (图像来源:Arm ®)
鉴于矩阵运算的优势,底层硬件的功能在确定神经网络的训练时间和推理中起着核心作用完成模型的时间。实际上,这意味着如果目标应用程序具有适度的性能要求,即使是相对低级别的通用系统(如Raspberry Pi)也可用于CNN培训和推理。事实上,任何围绕通用处理器设计的系统,如Arm Cortex ® MCU都可以作为ML平台。
为了帮助开发人员在其Cortex MCU上部署神经网络,Arm提供针对Arm Cortex-A系列MCU优化的专用计算库,例如Texas Instruments Sitara MCU,NXP i.MX6 MCU和NXP i.MX8 MCU。对于基于Arm Cortex-M的MCU,Arm提供CMSIS-NN,这是针对Arm Cortex-M系列器件的Cortex微控制器软件接口标准(CMSIS)中的神经网络特定库(图5)。 CMSIS-NN库设计为Arm Cortex微控制器软件接口标准(CMSIS)的附加软件包,增强了CMSIS-CORE,优化了卷积层,池,激活(例如:ReLU)以及其他常用功能。神经网络模型。
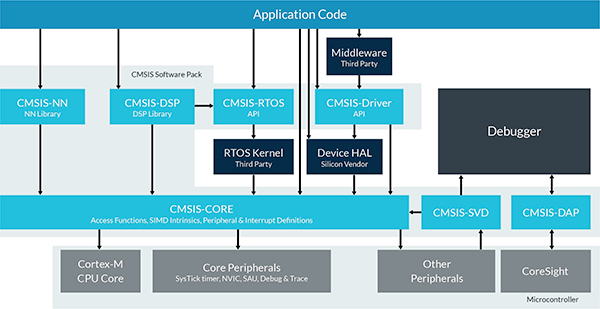
图5:CMSIS-NN库通过神经网络模型中常用的优化函数增强了CMSIS-CORE。 (图像源:Arm)
例如,使用CMSIS-NN库,开发人员可以在STMicroelectronics Mbed兼容的NUCLEO-F746ZG开发板上实现模型,该开发板使用基于Arm Cortex-M7的STM32F746ZG MCU 。
专业的AI芯片最终将为神经网络和其他机器学习算法提供显着的性能增强,但是这些芯片仍然处于规划阶段,同时算法也在巩固。
需要增加的开发人员现在,性能可以转向现成的FPGA,例如Intel Arria 10 GX,Lattice Semiconductor iCE40 UltraPlus或Lattice ECP5。这类FPGA集成了能够加速GEMM操作的DSP模块,并嵌入了存储器模块以减少存储器访问瓶颈,从而限制了这些计算密集型操作的性能。
Lattice Semiconductor使基于FPGA的模型迈出了一步通过提供机器学习FPGA IP和神经网络编译器,进一步提高SensAI堆栈。使用SensAI,开发人员可以在可用的Lattice FPGA开发平台上实现高级神经网络,包括Lattice ICE40UP5K-MDP-EVN移动开发板和Lattice LF-EVDK1-EVN嵌入式视觉开发套件。
虽然速度更快硬件平台通常意味着更快的训练和推理时间,目标平台中有限的资源通常需要仔细平衡推理时间,延迟,内存占用和功耗。机器学习专家通过对每个神经网络架构的进一步改进来响应这些要求。诸如模型参数和激活函数的减少比特量化的方法导致早期方法的存储器占用减少3倍至4倍。进一步的改进继续减少模型大小和复杂性,以实现更快的计算,从而缩短推理时间,降低延迟并降低功耗。
创新模型架构,培训方法和专用硬件的结合继续使先进的机器学习方法更接近任何开发人员的优势。
结论
机器学习正在成为用户识别,对象识别以及智能产品中所需的许多其他功能的强大解决方案。尽管机器学习技术曾被人工智能专家限制使用,但机器学习框架的广泛应用为主流开发人员的广泛应用打开了大门。
即使机器学习能力继续快速发展,开发人员也可以已经开始将这些框架与通用处理器和FPGA结合使用,以便在广泛的应用中使用机器学习。
-
采用Xilinx FPGA加速机器学习应用2016-12-15 0
-
超低功耗FPGA解决方案助力机器学习2018-05-23 0
-
Project Trillium-提供业界最具扩展性、应用范围最广的机器学习计算平台2019-03-07 0
-
采用专用处理器实现电机驱动方案2019-07-26 0
-
如何正确使用处理器参数?2019-09-03 0
-
富媒体应用处理器ZMS-08怎么样?2019-10-10 0
-
机器学习处理器单元支持浮点的乘加运算2020-11-26 0
-
利用处理器FPGA与液晶显示模块的图形显示的编程技术2021-07-30 0
-
DSP处理器与通用处理器的比较2021-09-03 0
-
将DSP和ML功能融合到低功耗通用处理器中2023-08-23 0
-
ISM330DHCX中可用的机器学习内核功能信息2023-09-08 0
-
什么是通用处理器2010-01-12 4153
-
寒武纪科技将发布深度学习专用处理器2017-10-11 889
-
服务器处理器与家用处理器有什么区别2020-06-02 1445
-
一文读懂i.MX 91应用处理器:为边缘平台提供安全、高效的Linux计算能力!2023-06-09 638
全部0条评论

快来发表一下你的评论吧 !
