

探讨人工智能在通信网络故障溯源方面的应用研究
电子说
描述
1
概述
全球运营商相继发布网络演进和转型战略,希望能够通过引入 SDN/NFV、云计算、区块链、5G 等新技术,减少对专有硬件的依赖,实现新业务的快速部署,满足用户多样化的需求,提升核心竞争力。但在转型过程中通信运营商面临着多种挑战,一方面是联网设备数量快速增长以及设备之间沟通产生的数据洪流,另一方面是随着电信网络设备日趋虚拟化、自动化和智能化,网络复杂度指数型增长。这些挑战无疑使网络运维变得日益繁杂和困难,运维人员一方面必须面对各种高度集成设备产生的大量实时信息,另一方面需要处理海量的告警数据,并且为了不降低用户感知,需要快速解决问题。现有的系统已经无法在异常状况发生时为运维人员提供足够的支持,导致许多问题不能被及时发现而不断传播升级,直至影响所有业务。如果发生异常告警时需要花费大量时间去寻找问题根源及解决办法,那么即使是细微的问题也会迅速地升级扩大。
人工智能(AI)的发展可追溯到 1956 年达特茅斯会议(Dartmouth Conference)[1]。人工智能可以定义为机器能够实现的智能,是与人类和其他动物表现出的人类智能和自然智能相对的概念。也可引用“人工智能之父”Marvin Minsky对人工智能的理解来定义它—“人工智能就是让机器来完成那些如果由人来做则需要智能的事情的科学”。网络人工智能(Network AI)[2]是将人工智能技术应用在网络中,使用机器替代或优化目前依靠人工进行的工作,使运营商能够更加便捷地提供更加优质的网络服务。
本文以人工智能技术为基础,结合现有网络运维技术,提出故障溯源整体解决方案。希望通过对告警信息进行合适的过滤、筛选、匹配、分类等流程确认告警信息,并根据各个告警之间的关系来进行告警溯源,屏蔽不重要或衍生的告警,实现对网络故障的快速诊断。同时配合相应的通信业务模型和网络拓扑结构实现故障的精准定位。最后通过实践中的具体案例分析,给出人工智能应用于网络故障溯源的结论和展望。
2
国内外研究现状
著名的 IT研究与顾问咨询公司 Gartner在 2016年提出 AIOps(Artificial Intelligence for IT Operations)的概念[3],即通过人工智能的方式来支撑现在日益复杂的运维工作。AIOps 可以在深度集成 DevOps 工具链的基础上获取系统数据,然后通过机器学习算法进行数据分析,更深度地解析数据中所蕴藏的运维信息。Gartner的报告指出预计到2020年,50%的企业将会在他们的业务和 IT 运维方面采用 AIOps,远超现在的10%。同时,国内外各大公司如AT&T、Microsoft、Facebook、百度、阿里巴巴等都在他们的运维系统中实验或部署了机器学习算法,助力某些运维任务智能化。
华为诺亚方舟实验室开发了智能故障诊断系统,利用网络故障的历史记录数据自动构建通信领域知识图谱[4],并在知识图谱上进行概率推理,以自动问答的形式帮助工程师找出故障的根本原因。微软分别在会议NSDI’09和SIGCOMM’16发表了2篇基于机器学习的故障检测系统的论文[5-6]。其中,2009 年发表的论文中提到针对家庭网络配置问题诊断的NetPrints系统。该系统通过学习明确针对应用的正确配置,在用户的某个应用发生错误时,可以通过检测用户的配置来为用户选择一个最小代价的调整策略恢复应用工作。同时,由于系统的特殊设计,一些系统原本无法解决的问题可以通过用户的协作更新到诊断系统中,实现了用户间的知识共享,提高系统的可用性。
2016年微软发表的论文中提到针对微软数据中心的错误定位问题的 NetPoirot 系统。该系统仅通过观察主机侧的 TCP数据就可以定位故障的发生位置,并且对于未训练过的错误也具有很高的故障位置识别率。但是,该系统只能诊断发生在主机、网络或服务器中的错误,无法精确地定位到设备也很难精确定位具体错误。针对移动设备的视频传输问题,加泰罗尼亚理工大学的研究者在 2015 年的 CoNEXT 上提出了解决方案[7]。该方案通过收集和处理服务中部分位置的设备数据,可实现视频流QoE的预测和故障定位。
3
故障溯源相关应用场景研究
结合电信网络的实际业务场景,剖析运维过程中的实际问题,更有益于将最新的AI技术运用到电信网络的运维和故障溯源中去,从而提升运维人员的运维效率和运维体验。目前典型的业务场景有以下几个。
3.1 场景1:瞬断告警
瞬断告警定义为告警的发生时间和清除时间很短,小于一定的阈值。这类告警因为生命周期比较短,对运维人员没有太大的价值,而且会导致告警量激增,从而掩盖真正需要关注的告警,增加运维人员识别难度。
3.2 场景2:频发告警
如果一定时间内发生的相同告警/事件达到一定的数目,可以认为这些告警/事件之间存在一定的相关性。通过设置告警/事件频次分析规则,当某一段时间内发生的设定告警/事件的数目超过了预先设置的阈值,则认为这些告警/事件之间存在相关性。如同一网元同一单板的单板温度过高或过低告警X分钟出现Y次,合并生成一条新告警,说明单板温度异常。
3.3 场景3:同网元内故障影响分析
指同一网元内某物理对象(单板、拓扑)上产生告警会导致该网元上其他物理对象和逻辑对象产生关联告警。
对于LTE设备,基站内单板之间以及单板和小区(逻辑对象)存在关联特性,因此单板故障往往会导致小区也存在异常。如图1所示,4槽BPN出现“光模块不可用告警”时,会导致51号RRU产生“RRU 断链告警”,而承载在该RRU上的小区也会上报“LTE小区退服告警”,即“光模块不可用告警”为根告警。
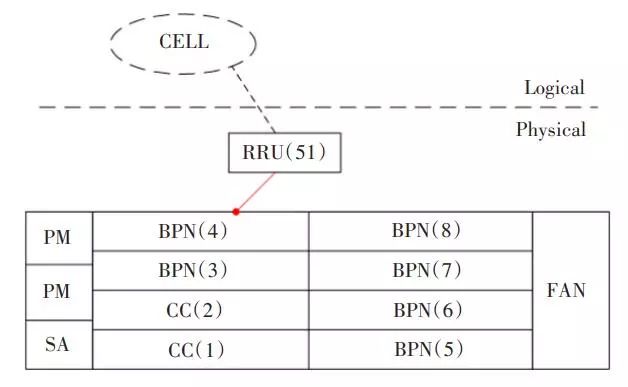
▲ 图1 某同网元内故障示意图
3.4 场景4:同专业网上下层业务故障影响分析
该场景体现为因为某一个故障导致大面积告警的现象,需要快速地获取故障原因。如图2所示,服务层告警会导致客户层告警的发生,如光纤出现断点,光纤所在端口会报LOS告警,导致上层的 TMS、隧道、伪线、业务都上报告警,此时光纤所在端口的LOS告警就是根告警。
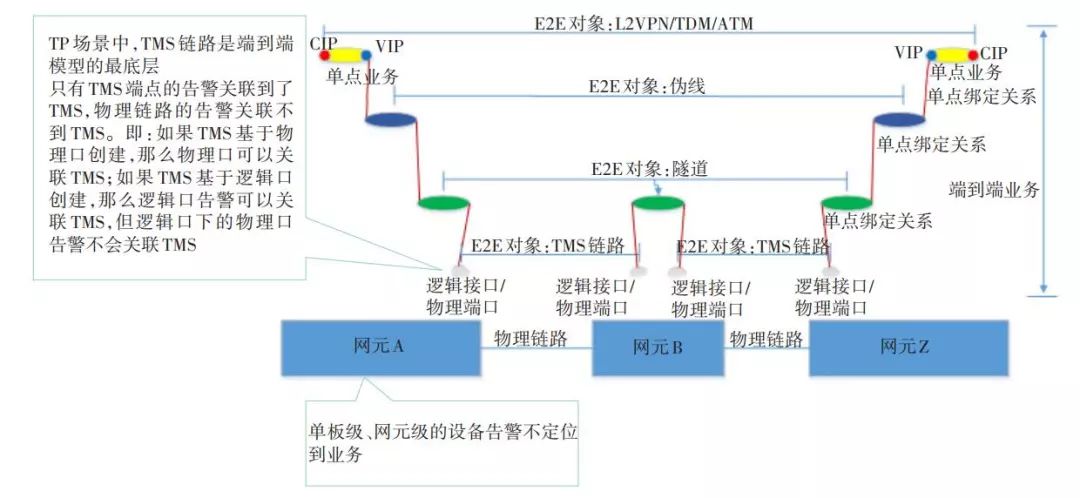
▲ 图2 某同专业网上下层业务故障示意图
3.5 场景5:跨专业网告警分析
传输包括光传输和微波传输,光传输节点会下挂很多微波节点,当一个链路中断会影响这条链路上的1个或多个站点,光传输节点断开导致所有下游的微波 BTS站点都会退服,中间微波某一跳断也会导致下游所有BTS退服(见图3)。
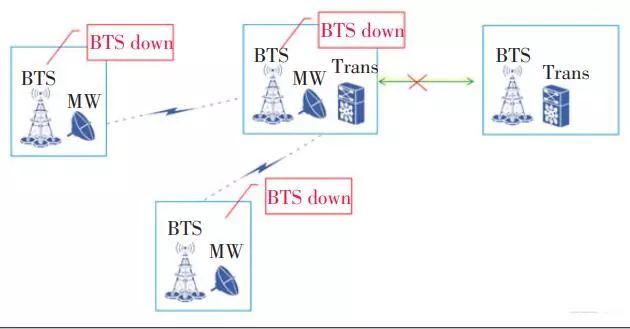
▲ 图3 某跨专业网故障示意图
3.6 场景6:综合故障诊断
故障的表现具有多样性,可能表现为告警、KPI异常或单纯业务不通,很多情况下告警并不能反映所有的故障点,所以也无法仅通过告警分析来定位故障。
比如网络升级后,某LTE业务不通,如图4所示的流程,根据经验,查看监控数据,进行各种诊断动作和配置检查,从而定位故障点,告警只是分析的一部分。
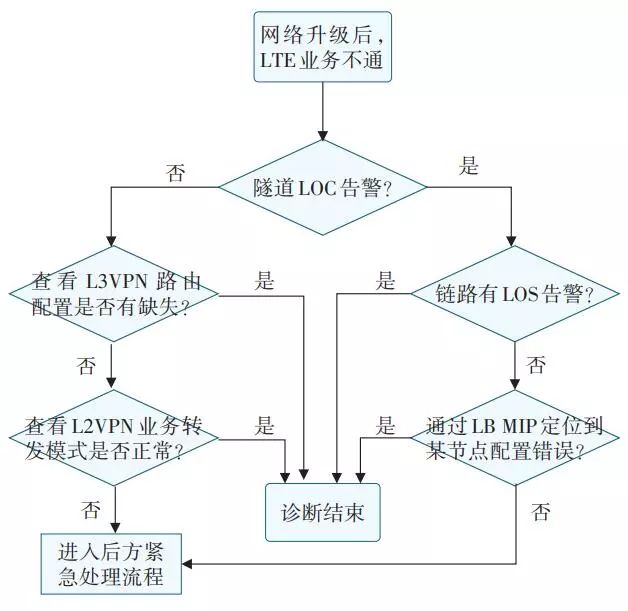
▲ 图4 某综合故障分析过程流程图
4
通信网络故障溯源整体解决方案研究
第3章所述业务场景要解决的问题就是如何智能地识别故障并做有效分析,故障分析模型是基于关联规则,而关联规则通常使用关联分析算法得到。
关联规则算法是从一个数据集中发现项与项之间的隐藏关系。只有从多个不同的维度分析告警数据,才能识别出它们之间的关联关系,如告警发生的模式或规律。
基于人工智能的故障诊断和溯源就是在结合大数据关联规则分析及人工智能技术的基础上,根据系统中的网络、业务上下游关系,综合所有监控数据(包括告警、性能)、操作日志以及故障解决历史记录,输出故障特征与故障原因之间的一系列规则。本方案旨在采用人工智能和大数据挖掘技术,研究开发智能故障诊断系统(见图 5)。在实际网络运维中,根据故障特征自动匹配诊断规则进行诊断,自动得出故障点及相关处理建议。
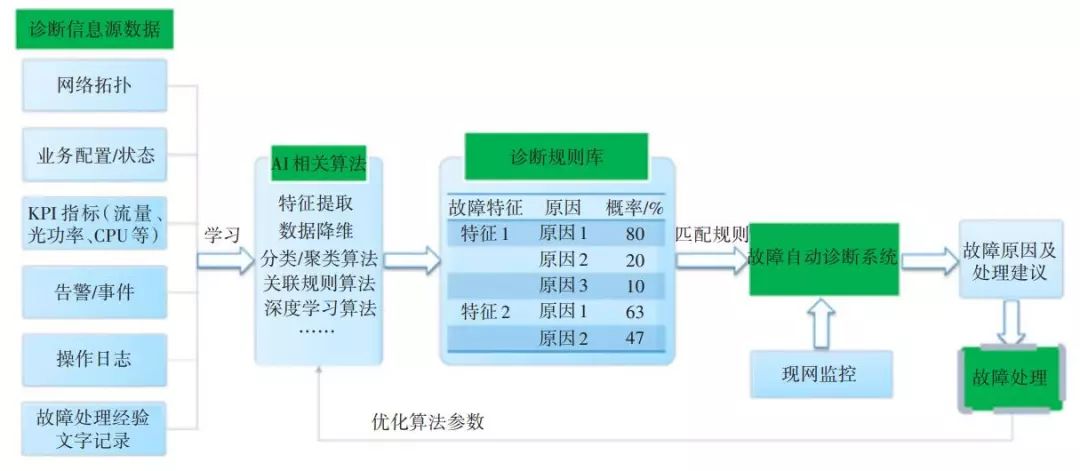
▲ 图5 智能故障诊断系统示意图
本文所提出的智能故障诊断系统要先基于AI学习生成诊断规则库,然后根据规则进行故障分析。
4.1 基于AI学习生成诊断规则库
4.1.1 诊断信息获取
诊断信息越丰富,诊断效果越好,所以系统应具有自动获取整个周期(当前、历史)的网络状态信息的功能。即在现网运行中,除了记录操作日志、告警、KPI、故障处理建议这种日常监控数据外,对于网络拓扑、业务配置、业务状态这些只记录当前状态的数据,也要定时采样,作为学习的素材。
4.1.2 建立自学习能力
提取故障特征,比如PWE3-CES的包丢失表示2G业务不通,分析其附近的KPI、操作日志、丢包情况、业务配置,业务状态等信息,获取故障特征。此处可使用数据降维,分类算法。
根据故障产生与消失这段时间的操作日志、故障文字记录、其他告警的产生消失情况等相关数据,分析原因。此处可使用关联算法、深度学习算法。
分析足够多的案例,得到所有可能的原因,并计算原因概率。此处可使用概率论的相关算法。
4.2 诊断规则的运行
现网监控:实时监控告警,并且对流量、丢包情况定时采样,并记录操作日志。
匹配故障特征,进行故障诊断:对现网监控数据实时进行匹配,一旦匹配成功,立即开始诊断。将故障的原因按概率从大到小排序,逐个诊断,当确认某个原因存在时,就可以定位故障并给出处理建议。
故障修复确认,反向修正诊断规则库:故障在自动恢复或派单修复后,反馈派单中原因是否有效,修正诊断规则库的原因概率。
相比传统的故障溯源方案,本方案结合运维中的多种数据源,包括并不限于告警、性能、拓扑资源、日志以及侦测命令,这使本方案溯源结果更加精确,并且更具有可参考性。
5
中国联通IPRAN告警智能化分析识别
5.1 案例背景和目的
IPRAN网络主要用于承载3G/4G移动业务以及大客户专线业务,主要采用IP/MPLS动态协议技术。IP RAN网络协议以及网络的逻辑连接的复杂性,使IP RAN网管系统每天接收到大量的设备告警消息,其中很多告警信息都是由根源告警信息引起。
目前处理告警数据的相关规则多依赖于专家经验,通过规则过滤掉不关键的告警信息。这种方法的缺点是过滤能力有限且有些规则无法被发现。
因此需要将人工智能技术应用于IPRAN网络告警根因溯源中,形成更高效的告警处理方法。
5.2 方案和效果分析
故障是产生告警的根本原因,当网络发生故障时,将产生大量告警,挖掘告警之间的关联规则对故障定位有着重要意义。总体方案思路如图6所示。
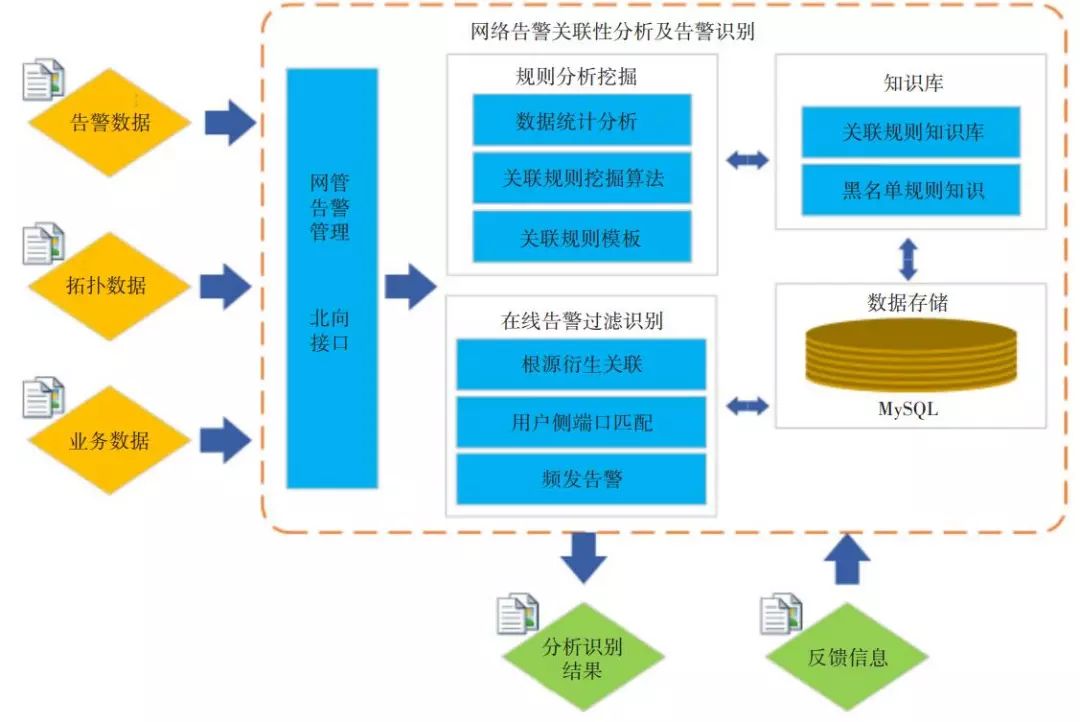
▲ 图6 告警根因溯源技术方案流程图
该方案流程总体可分为以下4个步骤。
a)数据预处理阶段,包括数据导入和清洗、用户端侧告警匹配、频发告警识别。输入数据为现网提取的历史告警数据、网络拓扑数据和业务数据3种,经过清洗和整合转变为可处理的数据格式。用户端侧告警匹配是根据以往运维经验去除不关心/无价值的告警。频发告警的具体描述见第3章中的场景2定义,该类告警的处理方式为对同一端口上连续10s内的相同告警进行压缩,仅留下频发告警的第1条告警,其他均标识为可过滤告警。
b)关联规则挖掘阶段,该部分核心算法为 Prefix-Span时间序列模式挖掘算法[8]。与Apriori、序列模式、时空模式等挖掘算法相比,该算法更适合本案例。但传统的 PrefixSpan 算法挖掘出来的规则不带有约束条件,导致专家也无法判断关联规则的正确性,如规则A[光模块不可用告警→ RRU 断链告警]。为解决该问题,改进了 PrefixSpan算法,这使其挖掘过程存在约束条件。此时规则A改进为[光模块不可用告警→ RRU断链告警,同网元],提升了算法规则挖掘的精确度。
c)关联规则确认与入库,其中包括已确认关联规则库和黑名单。通过多位专家确认上一步中挖掘出来的告警关联规则,将正确的规则存入已确认关联规则库中,以支撑下一步的告警识别工作。错误和不合理的规则自动导入黑名单,防止下次挖掘出同类规则。
d)根告警识别阶段,即给每个告警分别打上根告警、衍生告警、普通告警3种标签。根据8类不同约束条件对当前告警进行识别处理,约束条件分别为同一端口、同一网元、对应业务网元、同一业务ID关联、直连对端网元、直连对端端口、同环网元、对应业务ID关联。
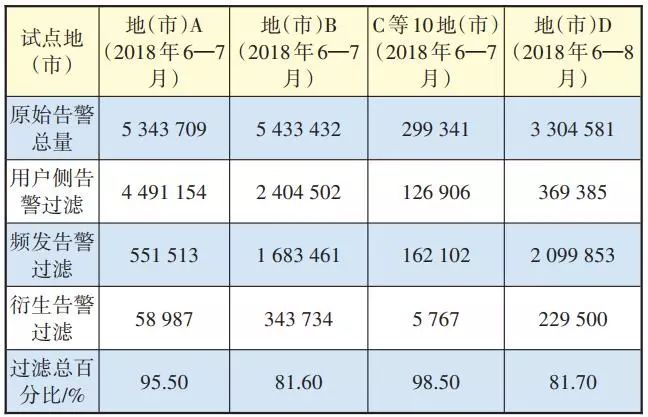
由于厂商和地域的差异性,目前还无法建立统一适用的关联规则数据库。现已建立了A设备商IPRAN的告警关联规则知识库,共计198条规则。通过已建立的知识库,在多个城市进行了试点,表1为相关告警分析的结果。
从表1中可以看到B市和D市处理效果较差,冗余告警(用户侧、频发、衍生)过滤百分比为81%左右,C市和A市结果较好,最高可达98%。产生该结果的原因有2方面:一是由于告警总数不同,其中无关联的普通告警数量也不同;二是地域的差异性,B市和D市的传输网络设备更多,无法根据人工规则去除无关告警。
表1 多个试点城市的历史网络告警分析处理结果
为了更直观查看告警之间存在的拓扑及业务关联关系,系统可根据分析结果自动呈现告警关联分析拓扑图,通过不同颜色标记网元以区分根告警和衍生告警,并可通过查看历史告警、网元、端口等信息,辅助支撑运维人员更准确地定位故障、精准派单。
6
总结和展望
通过案例分析可以看出将人工智能技术引用到网络运维的故障溯源场景中是可行且有效的,基于运维数据智能化地识别告警之间的关联规则,解决了人工经验积累不足的问题,提升了运维效率。但现阶段仍存在一些问题,由于目前采用的是单一的数据挖掘算法,需要人工判断关联规则和结果是否正确,准确率和实时性仍无法保障,并未做到真正的智能。
为解决单一人工智能方法的不足,未来可采用多种诊断技术协同的新模式,即多智能体技术。基于多种具备不同功能的软件系统,将复杂的网络告警分解成单一、独立的成分和因素,各个系统协同合作,能整合包括网络状态信息、硬件信息、工单信息等更多的数据,实现自主学习、自主训练,不断提升系统性能,全面关联网络告警,准确定位网络故障。
-
人工智能医生未来或上线,人工智能医疗市场规模持续增长2019-02-24 0
-
人工智能后续以什么形式发展?2019-08-12 0
-
一文分析人工智能恐惧现象2021-01-26 0
-
在人工智能神经网络ADC设计方面各位有什么见解呢?2021-06-24 0
-
贸泽电子公司将在2021年度Empowering Innovation Together系列节目的下一集中探讨边缘人工智能背后的力量2021-07-09 0
-
人工智能在哪些方面可以对IT运营产生重大影响 精选资料分享2021-07-12 0
-
通信网络抗毁性量度研究2009-10-31 461
-
智能变电站通信网络故障诊断2018-02-08 833
-
探讨人工智能研究趋势及应用2018-10-30 4522
-
人工智能在智能仓储方面的运用2020-09-30 5069
-
相聚银川,共同探讨人工智能发展2020-11-04 1535
-
2020年及未来一年人工智能在网络安全方面的趋势2020-12-07 7131
-
人工智能在电网调控中的应用研究2021-02-14 2003
-
人工智能在网络安全中的优势及实施风险2022-10-21 1705
-
人工智能在工业领域的作用2023-12-21 414
全部0条评论

快来发表一下你的评论吧 !
