

利用强化学习来更好地进行商品搜索的项目
电子说
描述
南京大学LAMDA Jing-Cheng Shi、俞扬等人团队的最新研究,描述了在淘宝这个大型在线零售平台、同时也是一个采样成本较高的物理环境中,利用强化学习来更好地进行商品搜索的项目。
在物理世界的任务中应用强化学习是极具挑战性的。根据当前强化学习方法的要求,在物理环境中进行大量实验是不可行的。
南京大学LAMDA 侍竞成、俞扬等人团队最近发表在 AAAI 2019 的论文,描述了在淘宝这个大型在线零售平台、同时也是一个采样成本较高的物理环境中,利用强化学习来更好地进行商品搜索的项目。

论文地址:https://arxiv.org/pdf/1805.10000.pdf
他们没有直接在淘宝上训练强化学习,而是提出了一个环境构建方法:先构建虚拟淘宝(Virtual-Taobao),这是一个从历史客户行为数据中学习的模拟器,然后在虚拟淘宝上训练策略,不需要实物采样成本。
此外,本研究的贡献如下:
为了提高仿真精度,我们提出了 GAN-SD (GAN for simulation distribution),用于更好地匹配分布的客户特征生成;
我们还提出 MAIL(Multiagent Adversarial Imitation Learning) 来产生更好的一般化的客户行为。
为了进一步避免过拟合模拟器的缺陷,我们提出了 ANC(Action Norm Constraint) 策略来规范策略模型。
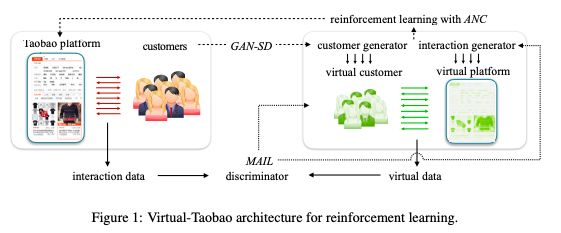
为强化学习构建的Virtual-Taobao架构
在实验中, Virtual-Taobao 是从数以亿计的真实淘宝客户记录中训练出来的。与真实淘宝相比,虚拟淘宝忠实地还原了真实环境的重要属性。
该研究进一步证明,纯粹在虚拟淘宝上训练的策略,通过在线 A/B 测试,其物理采样成本为零,可以显著优于传统的监督方法在现实世界中的性能。
研究人员希望这项工作可以为在复杂物理环境中应用强化学习提供一些启示。
此外,Virtual-Taobao模型也已经开源:
https://github.com/eyounx/VirtualTaobao
接下来,新智元带来这篇论文的翻译解读:
在物理世界应用 RL 为何重要
随着深度神经网络的融合,强化学习 (RL) 最近取得了许多重要进展,在游戏、机器人、自然语言处理等领域取得了很多成功。然而,关于 RL 在物理世界任务中的应用的研究较少,如与客户交互的大型在线系统,这可能对用户体验和社会财富产生很大的影响。
大型在线系统虽然很少与 RL 方法相结合,但确实追求应用 RL。实际上,许多在线系统都涉及到序列决策和延迟反馈。
例如,自动化交易系统需要根据历史指标和所有相关信息高频率地管理投资组合,并通过分析长期收益仔细调整其策略。
同样的,电子商务搜索引擎也会观察到买家的需求,并将排名好的商品页面显示给买家,然后在得到用户反馈后更新其决策模型,追求收益最大化。在这期间,如果买家继续浏览,它会根据买家的最新信息不断显示新的页面。
以往的解决方案主要基于监督学习。它们无法学习序列决策和最大化长期回报。因此,RL 解决方案非常有吸引力。
三大算法克服虚拟淘宝应用RL的障碍
在这些场景中直接应用 RL 的一个主要障碍是,当前的 RL 算法通常需要与环境进行大量的交互,这需要很高的物理成本,比如实际的金钱、几天到几个月的时间、糟糕的用户体验,甚至是生命 (医疗任务中)。
为了避免物理成本,RL 训练经常使用模拟器。谷歌在数据中心冷却方面的应用 (Gao and Jamidar 2014) 就展示了一个很好的实践:用一个神经网络来模拟系统动态,然后通过一些最先进的 RL 算法在模拟环境中训练策略。
在这个淘宝商品搜索项目中,我们使用了类似的过程:建立一个模拟器,即 Virtual-Taobao,然后就可以在模拟器中离线训练策略,利用 RL 算法实现长期收益最大化。
理想情况下,这样获得的策略在真实环境中可以同样表现良好,或者至少可以为更便宜的在线调优提供良好的初始化。
然而,与模拟数据中心的动态不同,模拟数亿客户在动态环境中的行为更具挑战性。
我们处理了根据客户策略生成的客户行为数据。现有的模仿学习方法可以实现从数据中推导出一个策略。
行为克隆 (behavior cloning, BC) 方法 (Pomerleau 1992) 主要是从状态 - 行为数据中通过监督方法来学习策略。BC 要求对 RL 任务中不满足的演示数据进行 i.i.d. 假设。
逆强化学习 (IRL) 方法从数据中学习一个奖励函数,然后根据这个奖励函数训练一个策略。IRL 放松了数据的 i.i.d. 假设,但仍然假设环境是静态的。当环境 (即淘宝平台) 发生变化时,学习策略可能会失败。上述问题使得这些方法在构建虚拟淘宝时不太实用。
在这项工作中,我们通过生成客户和生成交互来构建虚拟淘宝。有搜索需求的客户进入淘宝并触发平台搜索引擎,这类搜索需求的分布非常复杂和广泛。
但是,从数据库中抽取的样本并不能生成数据之外的客户,从而导致最终模型的泛化程度较低。我们提出了 GAN-for-SimulatingDistribution (GAN-SD) 方法来生成虚拟客户,因为我们发现传统的方法,如 GMM 和 GAN,并不适合这种高维数据。
为了生成交互 (interactions),我们提出多主体对抗模仿学习 (Multi-agent Adversarial Imitation Learning, MAIL) 方法。我们可以直接在虚拟淘宝中调用淘宝平台策略,但这会导致创造一个无法适应真实环境变化的静态环境。因此,MAIL 同时学习客户策略和平台策略。
为了同时学习这两个策略,MAIL 采用了 GAIL (Ho and Ermon 2016) 的思想,使用生成对抗框架 (Goodfellow et al. 2014)。MAIL 训练一个鉴别器来区分模拟的交互和真实的交互;区别信号作为奖励反馈,以训练客户策略和平台策略,从而产生更真实的交互。
在生成客户和交互后,虚拟淘宝就完成了,接下来可以用于训练平台策略。然而,我们注意到强化学习算法的强大程度足以过拟合虚拟淘宝的不足,这意味着它可以在虚拟环境中做得很好,但在现实中却很差。因此,我们提出行动规范约束 (Action Norm Constraint, ANC) 来使策略规范化。
在实验中,我们从数以亿计的客户记录中构建了虚拟淘宝,并与真实环境进行对比。我们的结果显示,虚拟淘宝成功地重构了非常接近真实环境的属性。然后,我们利用虚拟淘宝训练平台策略,以实现收入最大化。
与传统的监督学习方法相比,虚拟淘宝训练的策略在真实环境下的收益提高了 2% 以上,物理实验成本为零。
接下来,本文继续介绍虚拟淘宝方法、离线和在线实验,以及结论。
如何构建一个虚拟淘宝?
问题描述
商品搜索是淘宝的核心业务。淘宝可以被视为搜索引擎与客户交互的系统。淘宝的搜索引擎负责处理对数十亿商品搜索请求的毫秒级响应,而客户对商品的偏好也丰富多样。从引擎的角度来看,淘宝平台的工作原理如下。客户访问,向搜索引擎发送搜索请求。
然后,搜索引擎对相关商品进行排序,并向客户显示页面视图(PV),对搜索请求做出适当响应。客户给出反馈信号,比如买东西,然后转到下一页,或根据页面试图或买方自身意愿离开淘宝。搜索引擎接收反馈信号,并为下一个 PV 请求做出新的决定。淘宝的业务目标之一是通过优化显示 PV 的策略来实现销售量的最大化。
作为反馈信号,比如,会受之前的 PV 影响的客户行为,在优化搜索引擎策略时,将其视为多步骤决策问题,而不是单步监督学习问题,是更为合理的选择。因此,考虑到搜索引擎作为代理,以及客户的反馈作为相应的环境,淘宝中的商品搜索是一个连续决策问题。假设客户只记住有限数量的最新 PV,这是合理的,这意味着反馈信号仅受搜索代理的 m 个历史行为的影响。
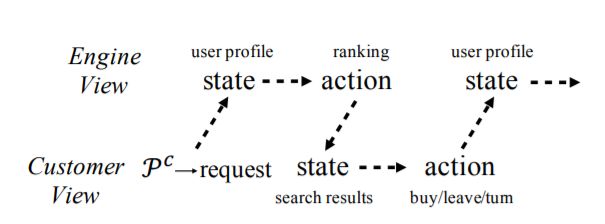
图 2:搜索引擎视角和客户视角下的淘宝搜索
注意,如果假设 m = 1,即客户的反馈仅受最后一个引擎行为的影响,这就是标准马尔可夫决策过程。
另一方面,如果我们将客户视为 agent,将搜索引擎视为环境,那么客户的购物流程也就可视作顺序决策流程。客户对排名后的商品,也就是搜索引擎的动作做出响应。客户的行为即反馈信号,它会受到最近 m 个 PV 的影响,这些 PV 由搜索引擎生成,并受到来自客户的最后反馈的影响。客户的行为也具有马尔可夫属性。为客户制定购物政策的过程可以视为对客户的淘宝购物偏好的优化过程。
如图 2 所示,搜索引擎和客户互为彼此的环境,二者的策略是耦合在一起的。
如果客户只是转向下一页而没有其他行为,那么负责记录客户特征和搜索请求的引擎的观察结果将保持不变。如果客户发送了另一个请求,或离开了淘宝,记录状态就会发生变化。
与搜索引擎相比,客户个人对环境往往更敏感,因此我们为客户进行了一些特别的设计。客户行为将受到 TA 想要的以及 TA 看到的内容的影响,分别用 S 和 A 表示,其中 S 是引擎观察结果,即包含请求的客户特征,A 是引擎动作,即向客户显示的页面视图。考虑到顾客的购买意图会随浏览页数的变化而变化,设 Sc = S×A×N,其中 N 表示页面索引空间。
Trasition 函数定义如下:

对于搜索引擎而言,如果客户买了东西,我们给引擎奖励为 1,否则为 0。对于客户,奖励函数目前尚不明确。
GAN-SD:生成客户特征
为了构建虚拟淘宝,需要首先生成客户特征,即对包括来自 P c 的请求的用户 U c 进行采样,以触发交互过程。生成的客户分布应与真实分布相似。
在高维空间中对分布进行学习很具有挑战性。像高斯混合模型(GMM)之类的经典方法很难实现这种相似分布。而众所周知,GAN 框架可以很好地生成接近于原始数据的样本,并在生成图像方面取得了巨大成功。
然而,传统的 GAN 判别器能够判定某一实例是否来自真实世界,但缺乏捕获客户分布架构的能力。为了生成分布而不是单个实例,我们提出了用于模拟分布的生成性对抗网络(GAN-SD),如算法 1 中所示。
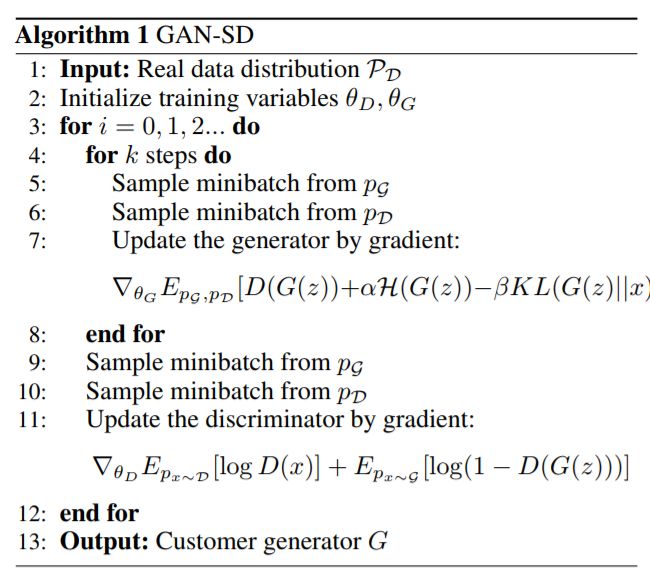
GAN-SD 算法伪代码示意图
与 GAN 类似,GAN-SD 也包括生成器 G 和判别器 D。其中,判别器试图通过最大化以下目标函数:
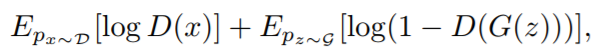
来正确区分生成的数据和训练数据。
而更新后的生成器则在实现以下目标函数的最大化:
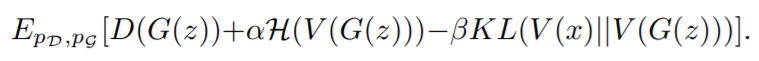
利用 KL 分歧和熵约束,GAN-SD 从真实数据中学习具有更多引导信息的生成器,并且可以产生比传统 GAN 更好的分布。
MAIL:生成交互过程
通过模拟客户策略,在虚拟淘宝之间生成客户与平台之间的交互。本文通过基于 GAIL 思想的多智能体对抗模仿学习(MAIL)方法来实现这一目标。 GAIL 允许智能体在训练期间与环境交互,同时奖励功能也在不断优化。注意,在 GAIL 训练期间应该能够访问环境。但是,训练客户策略需要将引擎视为未知环境或动态环境。
与在静态环境中训练一个智能体策略的 GAIL 不同,MAIL 是一种面向多智能体的训练策略,可用于训练客户策略和引擎策略。以这种方式得到客户策略能够包含不同的搜索引擎策略。
由于 MAIL 将两个策略一起训练,即代理和环境,只需要历史数据,不需要访问真实环境。MAIL 算法伪代码如下图所示:

实验设定及结果
为了验证 “虚拟淘宝” 的效果,我们使用以下量度指标:
总营业额(TT):所售商品的总价值。
总量(TV):销售商品的数量。
购买页面的购买(R2P):产生购买行为的 PV 数量占总 PV 的比例。
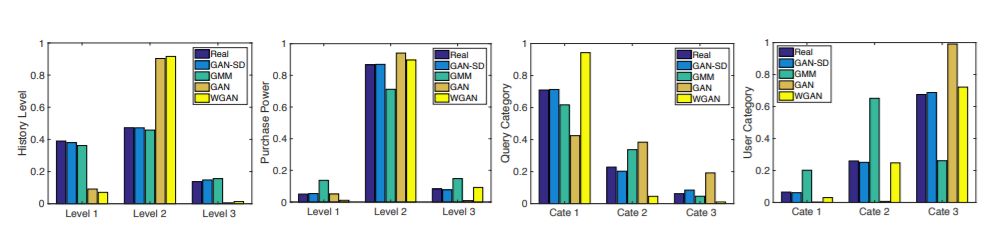
图 3:学习后的顾客分布的对比
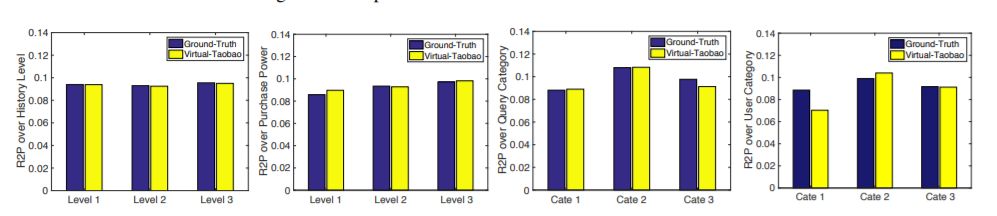
图 4:真实淘宝和虚拟淘宝之间的 R2P 对比
本文在线实验中采用了全部测量方式。在离线实验中只使用了 R2P 方法,因为我们没有对客户数量和商品价格做出预测。了便于在真实环境和虚拟环境之间比较这些指标,我们提前在真实环境(特别是淘宝网的在线 A/B 测试)中部署了随机引擎策略,并收集了相应的轨迹作为历史数据(约 4 亿条记录)。本文没有假设生成数据的引擎策略,也就是说,在构建虚拟环境时,可能采用的是任何未知的复杂模型。
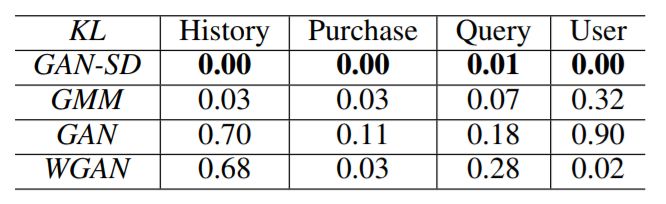
表 1:虚拟数据和真实数据之间的 KL 分歧

表 2:采用行为克隆和 MAIL 算法的模拟器随时间的 R2P 性能提升
结论
为了解决淘宝网站中面向商品搜索的强化学习的高成本问题,本文提出了一个 “虚拟淘宝模拟器”,根据历史数据进行训练的。首先通过 GAN-SD 生成虚拟客户,并通过 MAIL 生成虚拟交互过程。研究结果表明,“虚拟淘宝” 能够忠实反映真实环境中的特征。
本文提出通过 ANC 策略训练性能更高的平台策略,让新的策略具备比传统监督学习方法更好的真实环境下的性能。“虚拟淘宝” 具备实际应用意义,也颇具挑战性。希望这项工作能够为将强化学习应用于复杂物理任务提供一些启示。
开源模型:VirtualTaobao
VirtualTaobao开源项目提供了以淘宝的真实数据为基础训练的虚拟淘宝模拟器。在淘宝上,当客户输入一些查询时,推荐系统将根据查询和客户配置文件返回一个商品列表。该系统预计将返回一个良好的列表,让客户有很高的可能性点击这些商品。
使用 VirtualTaobao模拟器,用户可以像访问真实的淘宝环境一样访问“实时”环境。每次生成一次虚拟客户,虚拟客户启动查询,推荐系统需要返回一个商品列表。虚拟客户将决定是否单击列表中的商品,类似于真实客户。
本次开源的虚拟淘宝模型,用于推荐系统研究和强化学习研究(参见下面的监督学习和强化学习用例)。
目前,我们提供 VirtualTaobao V0 模型(VirtualTB-v0),该模型是在中等规模的匿名淘宝数据集进行训练的。更大型的模型即将发布。
安装
pip install -e .
模拟环境
虚拟淘宝模拟客户、商品和推荐系统。
一个客户与13个静态属性和3个动态属性相关联。这里,静态/动态表示该属性是否会在交互过程中发生变化。属性信息包括客户年龄、客户性别、客户浏览历史等。
一个商品与27维属性相关联,这些属性指示价格、销售额、CTR等。
系统和客户之间的交互过程如下:
虚拟淘宝采用客户的特征向量,包括客户描述和客户查询。
系统根据整个商品集的查询表单检索一组相关的商品。
系统使用一个模型来分配与商品属性对应的权重向量。
系统计算每个商品的权重向量与商品属性的乘积,并选择值最高的前10个商品。
选定的10个商品将发送给客户。然后,客户将选择单击某些项(CTR++),浏览下一页,或离开平台。
在上述过程中,将训练步骤3中的模型。模型输入客户特征,输出27维权重向量。
监督学习的用法
数据集在:
virtualTB/SupervisedLearning/dataset.txt
数据集的每一行都包含一个特性、标签和单击次数的实例,由制表符分隔。
为了从数据集训练模型,下面的代码使用PyTorch进行了演示
virtualTB/SupervisedLearning/main.py
它包含从数据集加载、模型训练和模型测试的完整过程。
强化学习的用法
下面是一个使用VirtualTaobao作为强化学习环境的最简单示例。每一步都取样一个随机操作来执行推荐。
import gymimport virtualTBenv = gym.make('VirtualTB-v0')print(env.action_space)print(env.observation_space)print(env.observation_space.low)print(env.observation_space.high)state = env.reset()while True: env.render() action = env.action_space.sample() state, reward, done, info = env.step(action) if done: breakenv.render()
下面是一个采用DDPG强化学习算法和PyTorch的更完整的例子
virtualTB/ReinforcementLearning/main.py
-
反向强化学习的思路2019-04-03 0
-
深度强化学习实战2021-01-10 0
-
将深度学习和强化学习相结合的深度强化学习DRL2018-06-29 27631
-
萨顿科普了强化学习、深度强化学习,并谈到了这项技术的潜力和发展方向2017-12-27 10884
-
什么是强化学习?纯强化学习有意义吗?强化学习有什么的致命缺陷?2018-07-15 17151
-
一文详谈机器学习的强化学习2020-11-06 1568
-
4种解决旅行商问题的强化学习求解算法2021-03-17 1121
-
机器学习中的无模型强化学习算法及研究综述2021-04-08 721
-
模型化深度强化学习应用研究综述2021-04-12 730
-
使用Matlab进行强化学习电子版资源下载2021-07-16 773
-
《自动化学报》—多Agent深度强化学习综述2022-01-18 1242
-
强化学习的基础知识和6种基本算法解释2022-12-20 874
-
基于强化学习的目标检测算法案例2023-07-19 266
-
什么是强化学习2023-10-30 1489
全部0条评论

快来发表一下你的评论吧 !
