

STM32芯片异常复位的原因有哪些
描述
问题描述
某STM32用户反馈,当使用STM32L4芯片的时候,程序运行一段时间后,会忽然复位。复位后程序继续运行,但是还会继续复位,原因不详。
问题解析
初步确定复位的原因,是硬件复位,如外部NRST被拉低,还是软件复位,包括软件直接调用复位,或者看门狗复位,还是低功耗模式如standby模式被唤醒时产生中断。
查看复位状态寄存器了解复位大方向,然后做进一步得拆解分析。
目前客户项目的复位原因是因为看门狗复位,即客户使用了IWDG,但由于某种原因没有及时喂狗,导致IWDG超时复位。初步怀疑由于客户软件的问题,程序跑飞,进入异常处理。
因为客户的异常处理函数中并没有做任何动作,导致独立看门狗IWDG复位。基于此,我们先关闭IWDG,然后在所有的异常处理中,先加入死循环并打上断点,对异常原因进行捕捉。
正如我们所猜测,的确是由于程序跑飞导致。程序停在了voidHardFault_Handler(void) 。
通过查看SP以及回溯栈里面的内容,找到了对应的LR,具体方法如下:
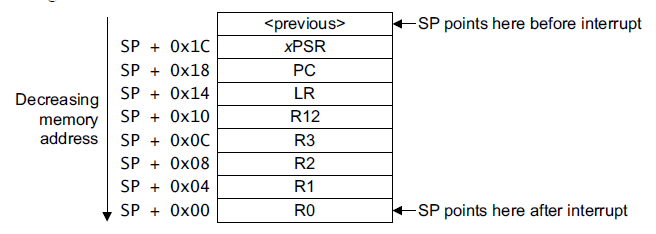
当中断产生时,按照上图所示的顺序进行压栈,同时栈指针SP--,即: R0, R1, R2, R3, R12, LR, PC, xPSR。

如上图所示,当产生异常时,如果call stack窗口显示不出来的话,只能根据core的寄存器手动回溯栈,以找到出错时的指针。根据ARM core的说明,SP+6,即红框的部分,为中断处理后LR和PC,据此可以追溯函数异常时的位置。
根据出错时的PC和LR,发现是浮点运算的函数,初步判断是因为浮点运算导致,比如没有对齐导致的Hardfault,但实际检查发现,并不是浮点运算的问题。
问题一时陷入了僵局。但有一点是确定的,是因为栈的区域被异常覆盖或者改写导致产生hardfault。
由于问题可以稳定复现,采取逐个排除法最终发现了问题的所在:
当把一个局部数组变量改为全局数组时,问题消失!
由于局部数组变量是保存在栈当中,所以怀疑是对这个局部数组变量使用不当导致了栈被覆盖或者改写。
追查这个局部变量数组:


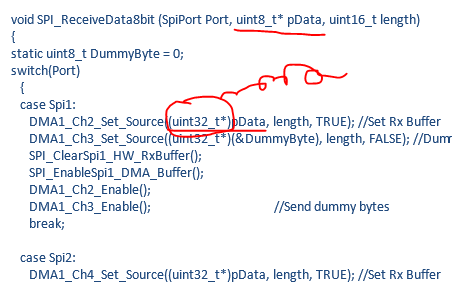
经检查发现,这个原先是8bit的局部变量的数组,在最后被强制转换成了uint32_t*类型的指针,由于是指针,在对其进行++或--操作时,都是按照4字节宽带操作的,这就相当于扩大了4倍,覆盖了后面的栈的内容,导致了程序跑飞。
小结当芯片异常复位或者进入异常处理 (如Hard fault, Mem Manage, Bus fault等)时,首先考虑的是,如何快速的复现这个问题,当问题被稳定复现的时候,可以通过调试工具在异常处理的地方打上断点停留,这样就可以获取到栈指针SP,通过SP去看栈里面的内容去回溯栈。当然,如果栈的内容被无端改写时,栈里面的内容,如保存的LR就没有太大的参考意义。不过,可以通过观察栈里面的内容,去估测是哪个模块或者函数异常修改了栈的内容,进而定位最终的问题源。
-
STM32F051K8U6芯片复位异常2022-12-19 0
-
STM32L476RET6复位电路异常是什么原因?2024-03-20 0
-
STM32F407ZG MCU控制器偶尔会出现异常复位,为什么?2024-04-01 0
-
分析一个关于STM32 芯片异常复位的经典案例!2019-04-07 0
-
stm32复位电路异常2019-05-12 0
-
导致MCU出现功能严重异常的几个原因分析2017-11-29 10878
-
STM32 Bootloader异常复位如何解决2019-03-23 9008
-
STM32引起电源和系统异常复位的原因2022-01-05 293
-
STM32学习笔记 | 引起电源和系统异常复位的原因2022-01-17 374
-
经典案例解析 | STM32芯片异常复位2022-02-10 891
-
STM32芯片的那些系统级复位功能2022-10-19 4202
-
基于STM32芯片特定外设复位的功能2023-06-22 1343
-
STM32单片机的应用笔记 奇怪的NRST 管脚异常复位问题2023-07-13 7540
-
STM32 Bootloader异常复位案例2023-09-25 114
-
单片机异常复位原因 简述单片机如何复位2023-10-17 2292
全部0条评论

快来发表一下你的评论吧 !
