

和谷歌研究人员一起探索数据并行的边界极限
电子说
描述
在过去的几年里,神经网络在图像分类、机器翻译和语音识别等领域获得了长足的进步,取得了十分优异的结果。这样的成绩离不开软件和硬件的对训练过程的加速和改进。更快速的训练使得模型质量飞速提升,不仅在相同的时间内可以处理更多的数据,也使得研究人员得以迅速尝试更多的想法,研究出更好的模型。
随着软硬件和数据中心云计算的迅速发展,支撑神经网络的算力大幅提升,让模型训练地又好又快。但该如何利用这前所未有的算力来得到更好的结果是摆在所有研究人员面前的一个问题,我们是否应该用更大的算力来实现更快的训练呢?
并行计算
分布式计算是使用大规模算力最常用的方法,可以同时使用不同平台和不同架构的处理器。在训练神经网络的时候,一般会使用模型并行和数据并行两种方式。其中模型并行会将模型分别置于不同的计算单元上,使得大规模的模型训练成为可能,但通常需要对网络架构进行裁剪以适应不同的处理器。而数据并行着是将训练样本分散在多个计算单元上,并将训练结果进行同步。
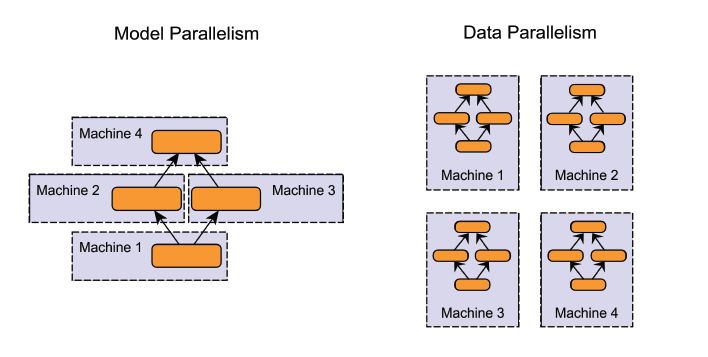
数据并行几乎可以用于任何模型的训练加速,它是目前使用最为广泛也最为简单的神经网络并行训练手段。对于想SGD等常见的训练优化算法来说,数据并行的规模与训练样本的批量大小息息相关。我们需要探索对于数据并行方法的局限性,以及如何充分利用数据并行方法来加速训练。
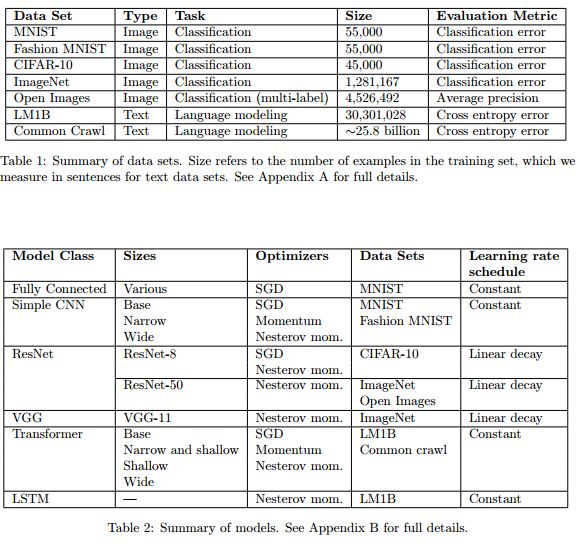
实验中使用的模型、数据集和优化器。
谷歌的研究人员在先前的研究中评测了数据并行对于神经网络训练的影响,深入探索了批次(batch)的大小与训练时间的关系,并在六种不同的神经网络/数据集上利用三种不同的优化方法进行了测试。在实验中研究人员在约450个负载上训练了超过100k个模型并发现了训练时间与批量大小的关系。
研究人员分别从数据集、网络架构、优化器等角度探索了这一关系的变化,发现在不同的负载上训练时间和批量大小的关系发生了剧烈的变化。研究结果中包含了71M个模型的测评结果,完整的描绘了100k个模型的训练曲线,并在论文中的24个图中充分体现了出来。
训练时间与批量大小间的普遍联系
在理想的数据并行系统中,模型间的同步时间可忽略不计,训练时间可以使用训练的步数(steps)来测定。在这一假设下,研究人员从实验的结果中发现了三个区间的关系:在完美区间内训练时间随着批量大小线性减小,随之而来的是递减拐点,最后将达到最大数据并行的极限,无论如何增大批量的大小即使不考虑硬件,模型的训练时间也不会明显减小。
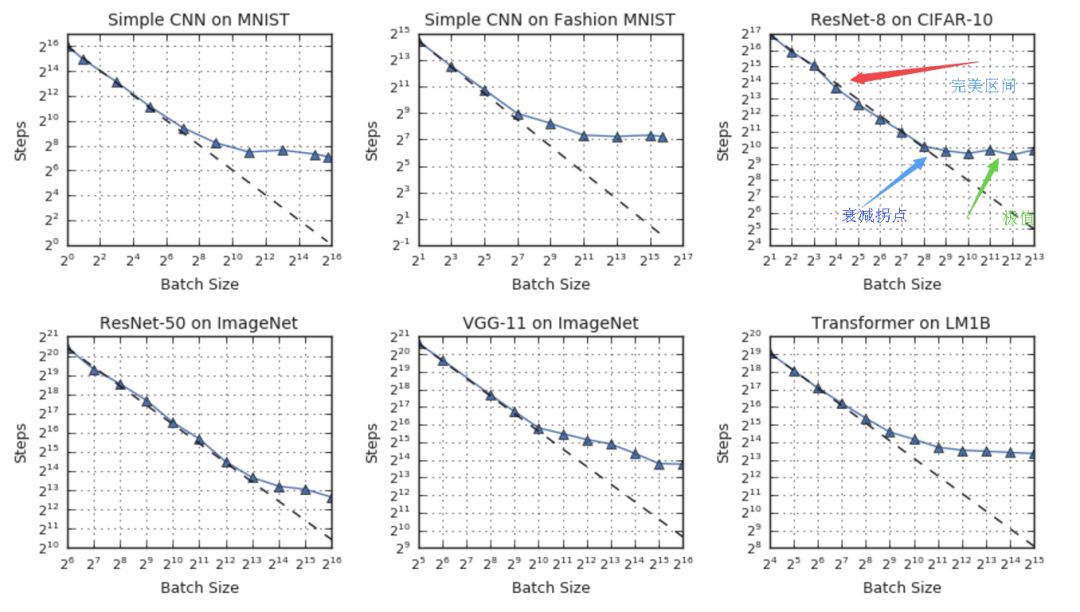
尽管上述的基本关系在不同测试中成立,但研究人员发现上述过程中的拐点在不同数据集和神经网络架构中的表现十分不同。这意味着简单的数据并行可以再当今硬件极限的基础上为某些工作提供加速,但除此之外有些工作也许还需要其他方法来充分利用大规模算力。
在上面的例子中可以看到,ResNet-8在CIFAR-10并不能从超过1024的批大小中获得明显的加速,而ResNet-50在ImageNet上则可以一直将批大小提升到65536以上来减小训练时间。
优化任务
如果可以预测出哪一种负载最适合于数据并行训练,我们就可以针对性的修改任务负载以充分利用硬件算力。但遗憾的是实验结果并没有给出一个明确的计算最大有效批次的方法。拐点与网络架构、数据集、优化器都有着密切的关系。例如在相同的数据集和优化器上,不同的架构可能会有截然不同的最大可用批次数量。
研究人员认为这主要来源于网络宽度和深度的不同,但对于某些网络来说甚至没有深度和宽度的概念,所以无法得到一个较为清晰的关系来计算最大可用批次数量。甚至当我们发现有的网络架构可以接受更大的批次,但在不同数据集上的表现又无法得到统一的结论,有时小数据集上大批次的表现甚至要好于大数据上的结果。
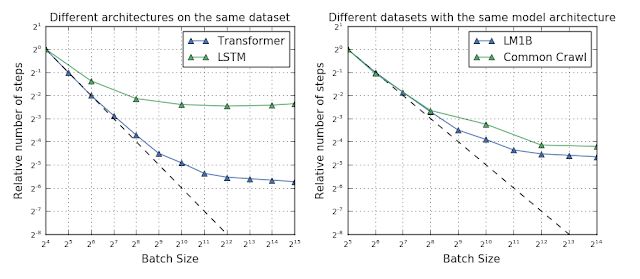
fig 4图中显示了迁移模型和LSTM模型在相同数据集上最大批次的不同,右图则显示了较大的数据集与最大batch也没有绝对的相关性,LM1B规模较小但可以达到较大的batch。但毋庸置疑的是,在优化算法上的微小改动都会使得训练结果在增加批量大小的过程中发生极大的变化。这意味着我们可以通过设计新的优化器来最大化的利用数据并行的能力。
未来的工作
虽然利用通过增加批量大小来提高数据并行能力是提速的有效手段,但由于衰减效应的存在无法达到硬件的极限能力。研究表明优化算法也许可以指导我们找到充分利用硬件算力的解决方案。研究人员未来的工作将集中于对于不同优化器的测评,探索恩能够加速数据并行能力的新方法,尽可能的延伸批量大小对应训练时间的加速范围。
如果想探索研究人员们在千百个模型上训练出的数据,可以直接访问colab:https://colab.research.google.com/github/google-research/google-research/blob/master/batch_science/reproduce_paper_plots.ipynb详细过程见论文包含了24个丰富完整的测评图,描绘了神经网络训练过程各种参数随批量变化的完整过程:https://arxiv.org/pdf/1811.03600.pdf
ref:https://ai.googleblog.com/2019/03/measuring-limits-of-data-parallel.html
Paper: https://arxiv.org/pdf/1811.03600.pdf
代码:https://colab.research.google.com/github/google-research/google-research/blob/master/batch_science/reproduce_paper_plots.ipynb
https://blog.skymind.ai/distributed-deep-learning-part-1-an-introduction-to-distributed-training-of-neural-networks/https://blog.inten.to/hardware-for-deep-learning-part-3-gpu-8906c1644664?gi=bdd1e2e4331ehttps://ai.googleblog.com/2019/03/measuring-limits-of-data-parallel.htmlhttps://blog.csdn.net/xbinworld/article/details/74781605
Headpic from: https://dribbble.com/shots/4038074-Data-Center
-
日研究人员新发现:光纤也能变身太阳能电池2009-04-14 0
-
美国普渡大学和哈佛大学的研究人员推出了一项新发明 新...2013-02-03 0
-
研究:面部识别技术目前并不可靠2016-06-28 0
-
泰克仪器助力研究人员首次通过太赫兹复用器实现超高速数据传输2018-08-31 0
-
微软和谷歌研究人员又披露了新漏洞变体42018-05-25 3754
-
斯坦福大学研究人员建立了一个名为Tabula Muris的开源数据库2018-10-11 4551
-
研究人员们提出了一系列新的点云处理模块2019-08-02 2748
-
Facebook向研究人员发布友谊数据2020-04-22 3153
-
研究人员研发出小型无人机,可自主探索未知的环境2020-04-27 2294
-
研究人员开源RAD以改进及强化智能学习算法2020-05-11 1202
-
研究人员已经使用机器学习来开发血液测试2020-05-21 1799
-
陆军研究人员在现实环境中演示了第一支人类机器人团队2020-09-09 1674
-
特斯拉研究人员探讨如何突破无负极锂金属电池的极限2020-09-12 2163
-
俄亥俄州立大学的研究人员有望突破自动驾驶技术的极限2021-08-02 1750
-
谷歌研究人员利用现有的耳机来测量心率2023-11-09 332
全部0条评论

快来发表一下你的评论吧 !
