

PAKDD 2019 AutoML挑战赛结果出炉:国内团队DeepBlueAI斩获第一名
电子说
描述
近日,数据挖掘领域顶会PAKDD的AutoML挑战赛结果出炉,DeepBlueAI、微软&北航、清华大学等团队斩获前三名。本文带来冠军团队解决方案的技术分享。
PAKDD 2019 AutoML挑战赛结果出炉:国内团队 DeepBlueAI 斩获第一名,微软亚洲研究院&北航组成的ML Intelligence团队获得第二名,清华大学Meta_Learners团队获得第三。
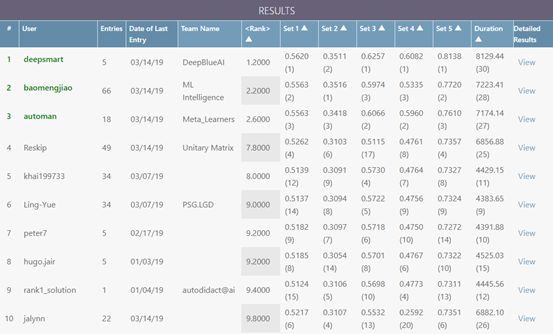
Feedback phase 排行榜
PAKDD 全称亚太地区知识发现与数据挖掘国际会议(Pacific Asia Knowledge Discovery and Data Mining),是亚太地区数据挖掘领域的顶级国际会议。该会议在全球数据挖掘领域享有盛誉,一直受到业内各国科学家的高度重视和广泛认可。
PAKDD 2019 第 4 届自动机器学习挑战赛(AutoML Challenge)的主题是“AutoML for Lifelong Machine Learning”,要求参赛选手创建一个自动预测模型(没有任何人为干预),并在一个终身机器学习(Lifelong Machine Learning)设置中训练和评估该模型。
AutoML,全称为 Automated Machine Learning,是机器学习领域的一个新兴方向。旨在自动化整个机器学习的流程,降低数据预处理、特征工程、模型选择、参数调节等环节中的人工成本。
随着机器学习系统的日益复杂化,AutoML 得到了产学研各界的广泛关注,已成为人工智能领域最热门的研究方向之一。
据悉,本次竞赛共有 127 个队伍参加,共收到 550 多个方案,最终有 31 个队伍进入决赛。
最终获胜的队伍为:
冠军:DeepBlueAI,罗志鹏,黄坚强,陈明健
亚军:ML Intelligence,包梦蛟,Hui Xue,Yihuan Mao,Yujing Wang
季军:Meta_Learners,熊铮,蒋继研,张文鹏
接下来,本文带来冠军团队解决方案的分享。
冠军方案关键技术:自动特征工程和自动快速特征选择
如下图所示,研究团队实现了一个Lifelong AutoML 框架,包括自动特征工程和自动快速特征选择、自动模型调参、自动模型融合等步骤,在类别不平衡的处理上我们使用了自适应采样并在模型训练上有一定的创新,对概念漂移问题我们结合DNN的预训练和LightGBM的再训练以及针对性地设计特征来缓解概念漂移,并且利用了多种策略对运行时间和运行内存进行了有效的控制,以确保解决方案能在限制时间和内存下完成整个流程。
自动特征工程与快速特征选择:
与以往的AutoML框架所不同的是,我们的框架更加注重自动特征工程与特征选择,我们构建的自动特征工程不仅是基于时间特征、分类特征、数值特征、多值分类特征做特征间的高阶组合,同时我们自动提取跨时间、样本的高阶组合。
对于特征选择,我们结合特征重要性及序列后向选择算法实现了一个有效的快速特征选择,在忽略重要性低的特征上结合序列后向特征选择算法,对重要性极高的特征进行筛选,这能快速地筛选掉过拟合特征,从而大幅度提高模型性能。为了避免维度灾难,我们迭代地进行特征工程和特征选择,在低阶特征生成后,利用特征选择过滤大部分特征,在其基础上进行更高阶的特征组合,更有效地提取了高阶特征并避免了维度灾难。
缓解类别不平衡:
我们能够自动针对数据情况(数据大小,数据类型,以及正负样本比例),以及比赛时间的限制等各种因素的不同,自适应地对数据采取不同的采样方式和比例,既保证了效率的同时又保证了效果。传统的类别不平衡的数据训练方式,是通过提前对数据进行采样,缓解类别不平衡问题,然后将数据加入模型中训练。但是这样会损失大量的数据信息,所以我们在数据采样的时候,仍然保留大量的高比例样本,并且将其分批,在加入模型中训练时,让模型在梯度提升中轮流训练分批数据,这样能够尽可能保留更多的原始数据的信息,同时缓解了类别不平衡问题。
抗概念漂移处理:
针对数据大小,数据复杂度,自适应选择batch数目。同时,对于每个batch,加入了“不同batch间采样率随时间增加”机制。我们使用DNN模型对特征Embedding进行预训练,迁移到新的数据批上进行再训练,有效地缓解了概念漂移和增强了特征表达。
挑战和改进
研究团队表示,不同特征类型的处理是本次大赛最棘手的挑战。
本次大赛数据由多种不同的数据类型组成,这些都是现实世界问题需要处理的真实数据。而现有的AutoML框架往往只支持数值类型,不能简单将现有框架应用到这些现实数据中。研究人员通过以往的大量竞赛及实际项目经验,在特征工程处理上加入了大量的先验知识,使得框架能支持不同特征类型的特征工程,以及能自动对这些不同类型特征做高阶组合以及特征选择。支持更多的数据类型而不仅仅是数值类型保证了AutoML能应用到更广泛的现实问题中,大大增强了AutoML的实用性。
团队表示,该解决方案有一些可以改进的方面:
首先,比赛所使用的数据仅来自于10个不同的任务,虽然我们在10个任务的数据集上都取得了很好的效果,但并不能保证我们的AutoML框架能应用到更广泛的不同现实世界问题中。
其次,比赛所提供的都是单表数据,而现实中的问题往往是多表关联的且关系复杂的,表间的关系往往包括多对多、一对多、多对一、一对一等多种关系。
为了更好地将AutoML应用到现实问题中,我们将设计并实现并实现支持多表联结数据以及不同数据类型的AutoML框架,将该框架应用到更多现实世界问题的数据上进行测试。
终生自动化机器学习:AutoML对现实世界问题的意义
这次比赛将AutoML扩展到了多种不同的数据类型上,其目标是实现一个支持不同数据类型并能适应概念漂移的终生自动化机器学习。
首先,现实世界问题的数据往往是多种不同数据类型的,需要特定领域的专家对这些数据进行大量的预处理及特征工程,而现有的自动化机器学习框架又仅支持数值类型,对其他类型不能有很好的支持,很难应用到各种现实世界问题中。在这次比赛中,我们团队设计的AutoML将自动化机器学习扩展到了多种数据类型,引入了不同类型的特征预处理以及不同类型特征的特征工程及特征组合,这样能在不需要专家的干预下將AutoML应用到更多的现实世界问题中。
其次,许多现实世界问题数据是根据时间逐渐获取的,数据间往往带有概念漂移,并存在大量的类别不平衡问题,模型需要不停地重复训练去适应概念漂移并需要专家去处理概念漂移及类别不平衡问题。我们团队设计的框架通过融合不同时期的数据以及结合DNN和LightGBM的训练来自适应概念漂移,引入了自适应采样以及对梯度提升模型的采样率进行改进来缓解类别不平衡,实现了终生机器学习。
我们设计的终生自动化机器学习框架可以应用到各种现实世界问题中,例如在推荐系统、异常检测、在线广告、欺诈检测、运输监控、计量经济学、病人监控等诸多领域中,无需领域专家的干预,我们的框架可以训练出一个性能高、时效性强、时间可行的模型,从而降低应用门槛,缩短项目开发周期,促进机器学习的大规模落地。
-
LabVIEW挑战赛正式开赛,台北总决赛等着你!2014-05-23 0
-
【LabVIEW挑战赛正式开赛】2014-07-17 0
-
【DIGILENT挑战赛】+电子相框2017-05-03 0
-
小小班机器人创新挑战赛走进武汉2017-05-05 0
-
5天通过VR学习原理图设计挑战赛2019-04-08 0
-
分享3天LabVIEW人脸识别挑战赛设计心得,赢取学院课程福利!2019-04-26 0
-
华为鸿蒙与安卓流畅度测试,鸿蒙OS仅排第八,与第一名差距悬殊2021-07-15 0
-
OpenHarmony成长计划挑战赛作品有奖征集2022-08-30 0
-
成长计划|解决方案学生挑战赛获奖名单公示2022-10-19 0
-
#Altium声源跟踪小车挑战赛 活动手册2022-10-31 0
-
【设计大赛】个人千元奖励!华秋PCB多层板设计挑战赛2022-11-04 0
-
【获奖公示】华秋PCB多层板设计挑战赛获奖名单2022-11-22 0
-
祝贺 | 鹏城实验室开源 EDA 团队勇夺 ICCAD 竞赛第一名2022-12-13 0
-
【获奖名单】瑞萨RA4M2物联网网关设计挑战赛获奖名单公布!2023-03-13 0
-
深兰科技DeepBlueAI团队斩获低分辨率视频行为识别挑战赛的冠军2021-06-30 1676
全部0条评论

快来发表一下你的评论吧 !
