

一位网友便利用StyleGAN耗时5天创作出了999幅抽象派画作!
电子说
描述
英伟达推出的StyleGAN在前不久大火了一把。今日,Reddit一位网友便利用StyleGAN耗时5天创作出了999幅抽象派画作!不仅如此,他还将创作过程无私的分享给了大家,引来众网友的一致好评。
人人都能当抽象派画作大师了!
去年,佳士得拍卖会上拍卖了一副由AI创作的肖像画——《爱德蒙·贝拉米的肖像》,该画最终售价43.25万美元(301万元人民币),远远超过了7000到1万美元的预计售价,同时也引发了人们对人工智能作画的热烈探讨。
爱德蒙·贝拉米的肖像
今天,Reddit上一位网友利用StyleGAN训练生成了999幅抽象派画作!
生成的其中一幅画作
这项工作使得其他网友们羡慕不已:

那么,这999幅AI生成的画作中,是否又会出现天价作品呢?值得拭目以待。
利用StyleGAN训练生成抽象派画作
这位名为“_COD32_”的网友在Reddit上毫无保留的分享了这项工作的创作过程。
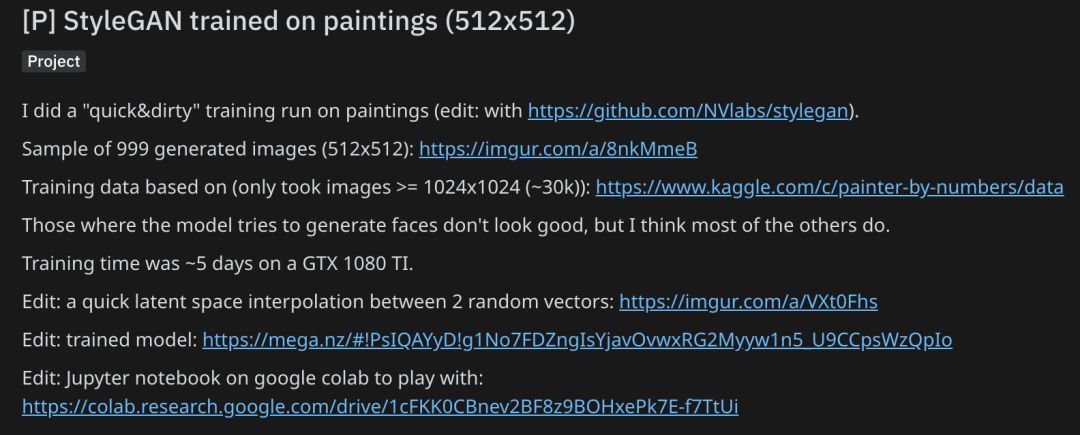
Reddit地址:
https://www.reddit.com/r/MachineLearning/comments/bagnq6/p_stylegan_trained_on_paintings_512x512/
在模型方面,采用的依旧是去年英伟达爆款StyleGAN,这是一种新的生成器架构,基于风格迁移,将面部细节分离出来,由模型进行单独调整,从而大幅度超越传统GAN等模型。
英伟达StyleGAN GitHub官方地址:
https://github.com/NVlabs/stylegan
在数据方面,采用的是Kaggle上名为”Painter by Numbers“项目中的数据集,其中大部分的图像数据来源于WikiArt.org网站。
Kaggle地址:
https://www.kaggle.com/c/painter-by-numbers/data
其中,只采用了≥1024X2014的图像。在GTX 1080 TI上的训练时间大约是5天。
不过作者表示,该模型试图生成人脸的部分并不是很完美,但其它部分还算可以。
例如下面两个随机向量之间的快速隐空间差值(latent space interpolation):
同时,作者也给出了训练好的模型和Jupyter Notebook地址:
https://mega.nz/#!PsIQAYyD!g1No7FDZngIsYjavOvwxRG2Myyw1n5_U9CCpsWzQpIo
https://colab.research.google.com/drive/1cFKK0CBnev2BF8z9BOHxePk7E-f7TtUi
英伟达“造假”黑科技:StyleGAN简介
StyleGAN是英伟达提出的一种用于生成对抗网络的替代生成器体系结构,该结构借鉴了样式迁移学习的成果。新结构能够实现自动学习,以及无监督的高级属性分离(比如在使用人脸图像训练时区分姿势和身份属性)和生成的图像(如雀斑,头发)的随机变化,并能在图像合成和控制上实现直观化和规模化。
新模型在传统的分布质量指标方面实现了提升,并且更好地解决了潜在的变量因素。为了对插值质量和分解进行量化,本模型提出了两种适用于任何生成架构的自动化新方法。以及一个新的、高度多样化、高质量的人脸数据集。
英伟达研究人员在论文中写道,他们提出的新架构可以完成自动学习,无监督地分离高级属性(例如在人脸上训练时的姿势和身份)以及生成图像中的随机变化,并且可以对合成进行更直观且特定于比例的控制。
换句话说,这种新的GAN在生成和混合图像,特别是人脸图像时,可以更好地感知图像之间有意义的变化,并且在各种尺度上针对这些变化做出引导。
例如,研究人员使用的旧系统可能产生两个“不同”的面部,这两个面部其实大致相同,只是一个人的耳朵被抹去了,两人的衬衫是不同的颜色。而这些并不是真正的面部特异性特征,不过系统并不知道这些是无需重点关注的变化,而当成了两个人来处理。
在上面的动图中,其实面部已经完全变了,但“源”和“样式”的明显标记显然都得到了保留,例如最底下一排图片的蓝色衬衫。为什么会这样?请注意,所有这些都是完全可变的,这里说的变量不仅仅是A + B = C,而且A和B的所有方面都可以存在/不存在,具体取决于设置的调整方式。
下面这些由计算机生成的图像都不是真人。但如果我告诉你这些图像是真人的照片,你可能也不会怀疑:
效果如此出众的StyleGAN一经开源就成了“网红”,由该模型生成的假脸几乎完全可以乱真,即使是放大了仔细看,大多数情况下依然难以分清,其难度堪比“大家来找茬”。
为此,有人甚至专门写了一篇指南,专门指点那些有兴趣“鉴脸”的人,该文总结出了StyleGAN生成假脸的几处常见的破绽。不过,这些破绽大部分是在图片背景、配饰、衣物等附加元素上找到的,面部本身的破绽虽然也有,但显著性和易见性都要下降一个档次。
上图的StyleGAN生成图像在面部上几乎无破绽,但左右耳的首饰不对称
被玩坏的StyleGAN:从“假人脸”到“假房子”,生成世间万物
StyleGAN生成假脸图像的逼真程度令人惊艳,但这么厉害的模型只能用来生成假人脸吗?显然不是。很快,越来越多的吃瓜群众发现了StyleGAN的更多潜力。比如生成假的出租房。
前不久,就有好事者利用StyleGAN生成了一个假的Airbnb租房网站,上面从房源图片、地址、再到租客的评论和打分没有一个是真实的,全是StyleGAN的杰作。
假房生成网站 thisairbnbdoesnotexist.com,每次刷新都会出现一个虚假的房源,网页上的照片、文字描述、发布人头像均由计算机自动生成。由于使用的模型非常简单,文字描述多有不合逻辑之处,但乍看上去还是能以假乱真。来源:假房生成网站 thisairbnbdoesnotexist.com
AirBNB网站截图,避免广告嫌疑做了虚化处理
根据Christopher Schmidt在Twitter的介绍,生成每个网页用一块GPU只需0.5秒,相关代码开源,你可以在这里找到:
https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/shakespeare_with_tpu_and_keras.ipynb
这个“假房源”网站是怎么做的?
网站上的图像当然由著名的图像生成模型StyleGAN生成,文本则来自在一个AirBNB列表(文末链接[1])上训练的语言模型,主要基于Tensorflow的“Predict Shakespeare with Cloud TPU”(https://t.co/sJoUbwZ2UL)。
这个文本生成模型似乎是个两层的前馈LSTM(文末链接[2]),主要是用它来独立训练生成房屋列表中的标题、描述、房主姓名、地理位置等,然后组合生成综合列表。
每个模型的输出都是预先生成的,每5秒创建一个新的列表(网页)。唯一的修改是根据文本稍微调整序列大小。
下面是Christopher Schmidt在Twitter上对这个“假房子”网站的简要介绍,包括灵感来源、大致结构、构建页面使用的框架和训练方式等。
本页面在开发时主要使用以下几种模型:在构建图片和卧室照片时使用StyleGAN,一些文本网络的训练使用了tf.keras来生成地点名称、房主姓名、标题和描述。此外还使用了Tensorflow的实例代码)
所有的数据训练过程都在谷歌的Colab上完成,该平台上可以免费使用GPU和TPU来训练和生成数据。

每个模型都可以做出独立的预测,所以会经常出现各部分信息不相配的情况,比如描述信息中说某套房子有一间卧室,但列表信息中显示有四件卧室,或者外观和名字排列不齐等。
但总的来看,这个过程是比较理想的,我在这个学习过程中也获得了不少乐趣,进一步掌握了一些模型的使用技巧。这里要感谢Colab平台,更感谢StyleGAN社群的出色研究成果。
有了这个思路,应用方向什么的就不用愁了,基于StyleGAN模型的假简历、假食物、假猫咪等等如雨后春笋一样不断涌现。甚至有人把这些“造假成果”汇总到了一个网站,叫“这些东西都不存在”。
这样看来,StyleGAN已经火到了几乎要被“玩坏”的程度。未来再出现什么样的假货,可能已经不取决于模型本身,而是程序员们的脑洞了。
介绍了这么多,大家是不是也想玩一玩StyleGAN呢?打开下方链接,快去尝鲜吧!
-
如果我用一台机器随机创作了一幅艺术品,那么版权属于谁?2015-12-07 0
-
转:使用MDK5软件,想从PE中导入KEIL工程的网友注意2016-06-06 0
-
请问是否可以用GIOA口中某一位代替GIOB的某一位?2018-05-22 0
-
没想到,有一天AI也会被「调戏」!2018-07-23 0
-
如何利用C语言的位域操作去实现对寄存器每一位的控制2022-02-25 0
-
中国企业为全球消费电子行业作出了巨大贡献2010-01-11 464
-
国家对申请照明产品范围及条件、申请企业条件等作出了规定2017-12-29 4306
-
加州对言论机器人作出了规管措施,影响政治的社交媒体“机器人”非法2018-09-10 720
-
NVIDIA利用StyleGAN算法创造不存在的人脸图像2019-02-19 5351
-
英伟达公开了StyleGAN的源代码,作为生成对抗网络的基于Style的生成器架构2019-03-05 12115
-
部分网友反映小爱无法使用,小米回应正在修复2020-06-15 4507
-
韩国法院安对首尔半导体诉亿光一案作出了判决2020-09-09 1660
全部0条评论

快来发表一下你的评论吧 !
