

DMVST-Net如何巧妙处理复杂的交通问题
电子说
描述
摘要
在智慧城市的建设中,出租车需求预测是一个及其重要的问题。准确的预测需求能够帮助城市预分配交通资源,提前避免交通拥堵,从而缓解交通压力,同时降低出租车空载率,提高出租车司机收入。传统的出租车需求预测往往基于时序预测技术(time series forcasting techniques),无法对复杂的非线性时空关系进行建模。深度学习技术的突破为交通预测问题带来了曙光,但是现存的深度学习网络架构,往往只单一考虑了时间关系或者空间关系,没有把两者结合起来进行建模。
本文提出了 DMVST-Net(Deep Multi-View Spatial-Temporal Network),同时对时间关系和空间更新进行建模。更具体地,该模型同时从三个角度出发(分别是 temporal view, spatial view,semantic view),综合考虑了出租车需求在路网上分布的时空关系,并利用语义信息,对相似区域的时空模式进行了建模。
值得一提的是,本文运用图网络 和 Local CNN 的方法,对由数万路段组成的大型道路交通网,进行了特征提取,这一举措,将图网络的运用拓宽到一个新的层次,使得大型交通网的建模有了新的解决思路。
主要贡献
1、提出了一个多视角模型,该模型同时考虑了 spatial,temporal 和 semantic 信息。
2、提出了 Local CNN 的方法,用于捕获区域的局部特征,该特征受到所捕获区域邻近区域的影响。
3、基于不同区域之间的时空模式的相似性,构建了一个 region graph,用于表达区域特征的语义信息。
4、利用滴滴出行的出租车订单数据进行实验,验证了模型的有效性和先进性
模型架构(DMVST-Net)
在介绍模型之前,先用通俗易懂的语言介绍一下论文的主要思路,先用一个易理解的例子来说明:
小明想预测整个广州市对出租车的使用需求,可是掐指一算,整个广州市有几万条道路,简单的用一维向量去表示它的话,会丢失空间关系;用图网络去构建交通网的话,得到的图尺寸相当大,瞅瞅自己只有四块 GPU,怕是带不动;转念一想啊,好多前辈都是用一个个规则的格网来表示城市的不同区域,再用 CNN 时空图像处理的方法建模,可是前辈们做了呀,这可咋整呢。于是小明想了一个办法:我用传统的格网去表示城市区域,每个格网的值就代表这个区域出租车的需求量,但是我分别对每个格网构建一个CNN网络。我再用图网络的方法,把城市中每个格网给连接起来,这样不就能够表示每个格网(城市区域)之间的联系了吗?
模型架构(DMVST-Net)
给小明同学鼓个掌,下面就是小明同学提出的模型。
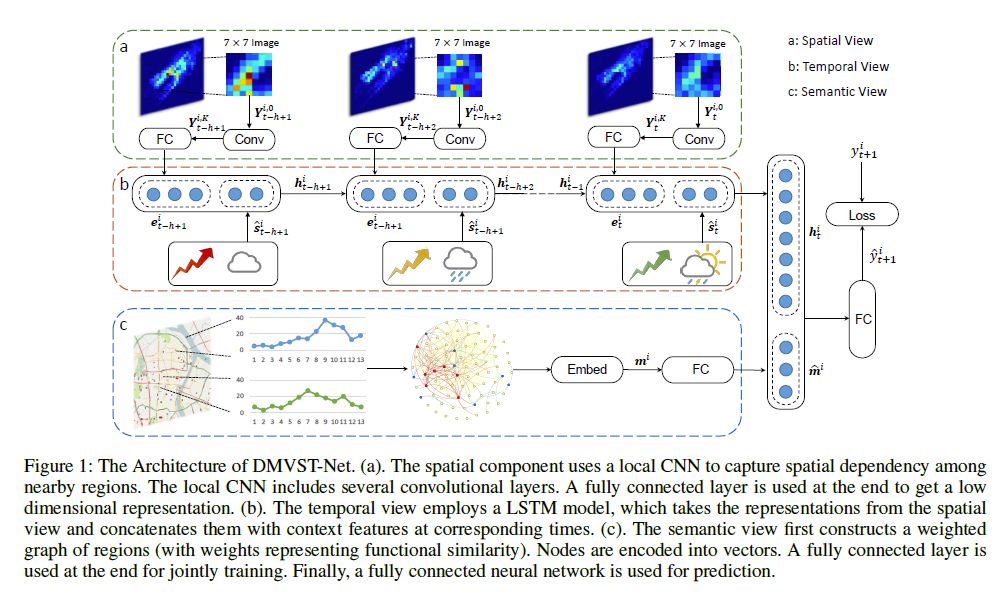
DMVST-Net 分为三个部分,分别是 Spatial View,Temporal View 和 Semantic View。
Spatial View:Local CNN
什么是Local CNN呢?举个例子,如下图所示,我要对 (a)提取特征,最常见的一种方式是把(a)这整张图像送入到CNN中,进行卷积运算;而另一种方式就是把(a)分块,把划分后的每一小块分别送入到CNN中,也就是每次只对(b)进行卷积运算,最后把每个部分的结果进行综合,这就是 Local CNN。
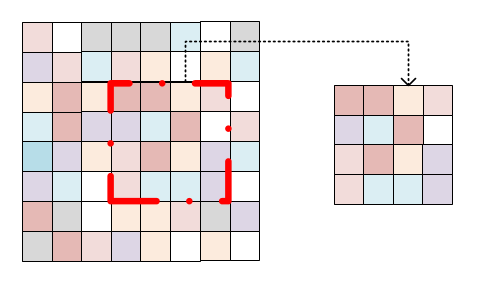
提出该方法的动机是地理学第一定律——near things are more related than distant things。举个例子,相比于湖北省和河北省的人民,湖北省和湖南省的人民生活习惯要更相似,这是因为他俩靠的近。小明同学在这里把广州市分成了20 x 20个区域,每个区域是0.7km x 0.7km,用7 x 7的二维图像来表示每一个区域,图像中每个像素点的灰度值代表出租车的需求量。每张图像可以用  表示,其中 S=7 。
表示,其中 S=7 。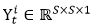 经过K个卷积层后得到
经过K个卷积层后得到 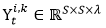 ,进行 flatten 操作得到
,进行 flatten 操作得到  ,最后进行降维得到
,最后进行降维得到  具体公式如下:
具体公式如下:


最终我们Spatial View的输出是  。
。
Temporal View: LSTM
小明同学在这里学习了牛顿的思想:“站在巨人肩膀上”。在该部分,小明同学直接利用了传统的时序预测利器——LSTM。LSTM 网络是一种特殊的 RNN 网络,该网络的全称是 Long Short-Term Memory network(长短期记忆网络)。LSTM 网络可以说是为时序预测所量身打造的,该网络不仅能够捕获近期的时间关系,还能记忆长期的时间模式,由于遗忘机制的引入,可以使得 LSTM 网络对长时序列也有较好的处理能力。在这里,我们不做推导,直接把公式放出来,有兴趣的朋友们可以参见文末的相应链接【4】。
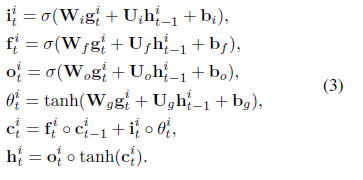
值得注意的是这里的 LSTM 网络的输入是  其中
其中  是 Spatial View 的输出,而
是 Spatial View 的输出,而  是天气、节假日等元数据特征,
是天气、节假日等元数据特征, 表示的是联合操作。最终我们 Temporal View 的输出是
表示的是联合操作。最终我们 Temporal View 的输出是  。
。
Semantic View: Structural Embedding
接下来到了我们最期待的一步,如何利用图网络的方法,构建城市各个区域的关系网络,从而给我们的深度学习任务提供更高层次的特征。首先,小明同学根据一个直觉:具有相同功能的地点应该具有相似的出租车需求模式,然而具有相同功能的地点在空间上不一定相邻。举个栗子,北京海淀区的一处 CBD 和朝阳区的一处 CBD 在很大程度上功能相似,但是这俩个地方隔得老远,可是却可能有着相似的出租车需求模式。基于这个直觉,小明同学构建了区域和区域之间的全连接网络  ,
,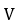 代表节点(即区域,总数为 20 x 20),
代表节点(即区域,总数为 20 x 20), 代表每两个节点的边,
代表每两个节点的边, 为相似性矩阵,
为相似性矩阵, 代表节点 i 和 j 的相似性。
代表节点 i 和 j 的相似性。
那么问题来了,这个相似性基于什么特征衡量呢?用什么方法去衡量呢?
我们的小明同学非常的聪明,他将每个节点的需求序列进行整合,计算每周的平均需求量,作为节点的特征,然后采用了动态时间规整(DTW)【5】的方法来衡量节点之间的相似性。

为了将每个节点的特征进行压缩,并同时维持网络的结构信息,小明同学又采用了graph embedding 的方法,将每个节点的特征压缩到更低的维度。为了构建一个端到端的神经网络模型,小明同学又将压缩后的特征送入到一个全连接层,最后得到了Semantic View 的输出 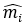 。
。
请注意,这里的代表的是节点 i 的语义特征,也就是说,Semantic View提取整个网络的特征,但是只把单个节点所学习到的特征送到主体模型中。
模型综合
最后就是模型综合部分了,简单的讲,就是把Spatial View,Temporal View 和 Semantic View 这三个部分的输出结果给联合起来,再通过一些神经网络层进一步提取特征,最后与真实值计算Loss,通过优化算法不断训练模型,最终得到一个较优的结果。这里简单列一下公式:
三个部分特征的综合: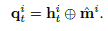
输出函数设计: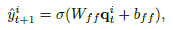
误差函数设计:
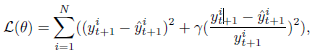
这里的 Loss Function 设计比较有趣,该公式由两部分组成,第一部分是均方误差(MSE),第二部分是平均绝对百分误差(MAPE),MSE更多的和大值相关,而MAPE对大值和小值一视同仁,引入MAPE能够避免训练过程被大值的样本所主导。
模型训练算法
在这里,直接把算法贴出来,算法的主要思想就是每个区域的需求预测都使用相同的网络结构,但是每个区域对应的网络有着不同的参数,对所有的网络结构都进行训练,直到满足停止条件。这里的算法不是重点,就不再叙述了,有兴趣的朋友可以看一下原文。

实验
数据集
在这里,将文章的数据集描述进行了整理,方便大家快速阅读

评价矩阵

主要结果
小明同学将自己的模型和当前的主流模型进行了对比,其中包括 Historical average,ARIMA,Ordinary least square regression,Ridge regression,Lasso,Multiple layer perceptron,XGBoost,ST-ResNet。
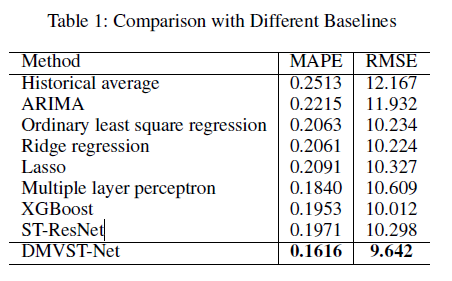
从表中可以看出,DMVST-Net的效果在两种评价指标上均为最优,证明了模型的有效性和先进性。
除此之外,小明同学还计算了各模型从工作日到休息日,相关误差的增长(RIE):

可以看到DMVST-Net的RIE最小,证明了模型鲁棒性很高
分别展示了周一到周日各天的预误差结果:

可以看到DMVST-Net每天的预测误差(MAPE)都比其他模型小。
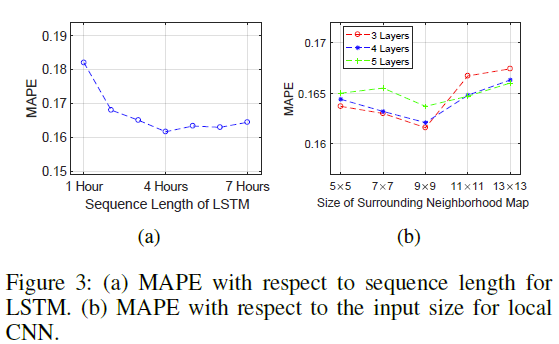
最后讨论了LSTM输入序列长度对模型结果的影响,及Local CNN输入图像尺寸的影响。
结语
这篇文章的作者说,该文的最大贡献在于从三个视角考虑了城市出租车的需求模式,提出了DMVST-Net,然而这种多视角的建模方式,早就老生常谈了。反到是对于图网络的巧妙运用,才成就了这篇论文:利用区域作为节点构图,而不是采用路段作为节点构图,不仅避免了城市尺度下图网络过大的问题,而且很好的利用图网络的特性,构建了不同区域之间的联系,从而提取了各区域的语义特征。这种大而化小的思想值得我们去学习,在图网络尚未解决计算复杂性的今天,或许这种小trick更加有利于加速产学研结合,将图网络应用到更多的地方!
-
.NET下不连续异步消息处理的研究2011-03-31 485
-
光电转换电路中对微弱信号的巧妙处理2013-03-17 0
-
永动机?设计很巧妙啊!2016-10-18 0
-
LabView导出.Net程序集的数组处理2017-10-12 0
-
vb.net实例教程下载2008-12-08 2592
-
ado.net入门知识教程2009-01-08 480
-
ADO.NET数据库实例教程2009-01-08 439
-
贵阳公共交通网络复杂性分析2010-01-15 655
-
汽车的蓄电池柱头松动的巧妙处理方法2009-11-06 2390
-
巧妙的点焊机电路2012-04-02 23148
-
电阻的巧妙用法2016-12-16 710
-
《ASP.net Ajax开发》基于AJAX的电子邮件处理2017-02-07 762
-
ADO.NET基础知识讲解2018-03-26 685
-
在Blackfin处理器上使用.NET Micro Framework缩短上市时间和开发成本2021-05-27 399
-
基于低耗散中兴迎风格式的复杂交通流模型求解2021-06-25 461
全部0条评论

快来发表一下你的评论吧 !
