

深入分析这家成立20年的英国公司在人工智能领域的核心技术竞争力
电子说
描述
四月中旬,英特尔宣布收购一家名为Omnitek的英国公司,旨在“增强FPGA在视频(video)和视觉(vision)领域的产品组合”。对于很多人来说,Omnitek并不是一个非常熟悉的名字。那么,究竟它为何受到了英特尔的青睐,以及这次收购背后的深层技术逻辑为何,就让老石在本文为大家深入分析。
(Omnitek CEO与创始人,图片来自Omnitek)
Omnitek是何方神圣
Omnitek并不是一个传统意义上的初创公司,它成立于1998年,总部位于英格兰南部的贝辛斯托克(Basingstoke),见下图。
贝辛斯托克这个小城是英国比较有名的经济和科技中心之一,巴宝莉(Burberry)就起源与此。这里集中了不少世界知名的大公司的总部或欧洲总部,其中包括很多半导体和科技公司,比如索尼、摩托罗拉、意法-爱立信等,华为的欧洲总部也曾经设在这个小城。
虽然Omnitek已经成立了超过20年,但员工总数只有四十人左右,也没有公开的融资记录。从这些方面来看,Omnitek只能算是一个中型、甚至小型的公司。
然而,在这20年中,Omnitek开发和积累了超过220个FPGA硬件IP、对应的软件系统、以及开发平台,见下图。
(图片来自Omnitek)
这些FPGA IP主要集中在视频和图像处理领域,包括使用FPGA进行超高清视频图像的旋转、形变、3D映射、编解码等等各类处理,见下图。
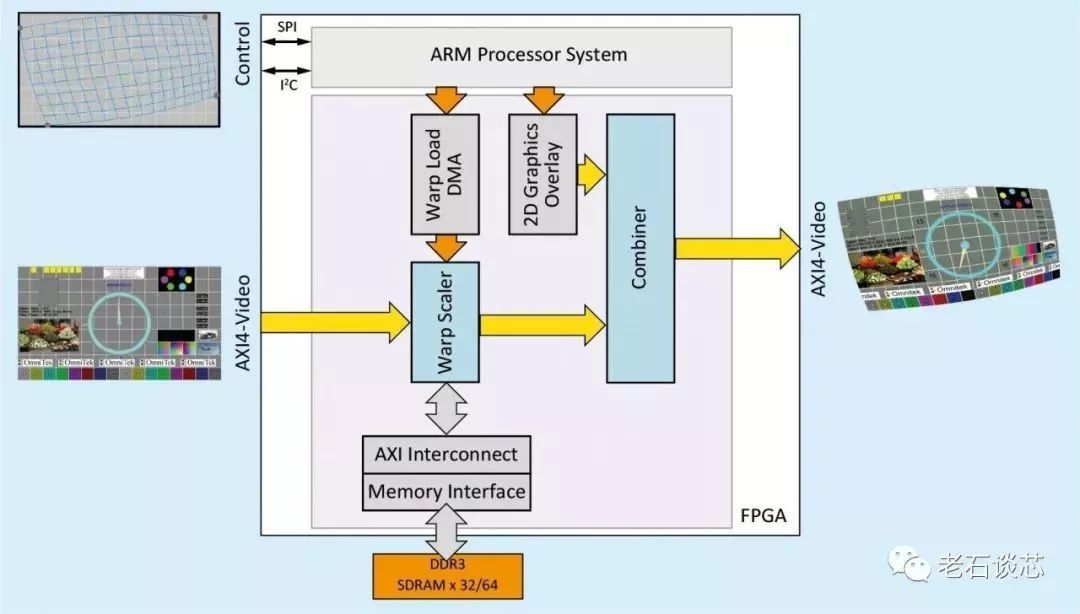
(图片来自Omnitek)
这些应用一直是FPGA的传统应用领域,特别是在诸如视频会议、投影、显示屏等场合。因此,就像在公布收购后的官方新闻稿中所说,这次收购将会极大的补强英特尔FPGA在视频和图像处理领域的IP资源。
然而,老石注意到,Omnitek在2018年底发布了一款自研的深度学习处理器(DPU)。与市面上任何基于FPGA的同类产品相比,Omnitek宣称这款DPU的性能有着50%的优势。同时,与GPU相比,这款DPU在给定的功耗或成本限制下也有着更加优异的性能。
在当前各类人工智能处理器xPU层出不穷的时候,Omnitek这个官宣大胆而自信。老石认为,这也是英特尔收购Omnitek背后的主要逻辑。
(获取Omnitek深度学习处理器技术白皮书,及相关幻灯片及视频资料,请在“老石谈芯”后台回复“DPU”)
“地表最强”FPGA深度学习处理器
老石在之前的文章《FPGA在人工智能时代的独特优势》一文中讲过,使用FPGA对人工智能应用进行硬件加速主要有以下几个优点:
基于这些优点,Omnitek选择使用FPGA作为其深度学习处理器的主要实现平台,这与目前业界包括微软在内的很多公司不约而同,见下图。
(图片来自微软)
事实上,与微软在“脑波项目”中使用的DPU相比,Omnitek的DPU在使用模型上也有着很多相似之处。这类DPU,也称为Soft DPU,最主要的特点就是提供一个基础的硬件架构,用来进行深度神经网络的计算加速;同时提供完整的软件编程接口和编译器,使得上层用户使用高层语言对神经网络进行配置。
这种架构的最主要优点,就是实现了软硬件的完全解耦,这也让使用者无需掌握任何硬件相关的专业知识,从而只需要专注于算法和模型本身的设计,并可以通过诸如Python、C/C++等高层语言对模型进行调整和配置。
与高层次综合(HLS)相比,这种基于FPGA的DPU设计方法无论在性能、开发敏捷性、编译时间等各个领域都有着明显优势。
Omnitek DPU的主要特点
与微软DPU相比,Omnitek的DPU又有着自己独有的特点。它的系统架构图如下所示。
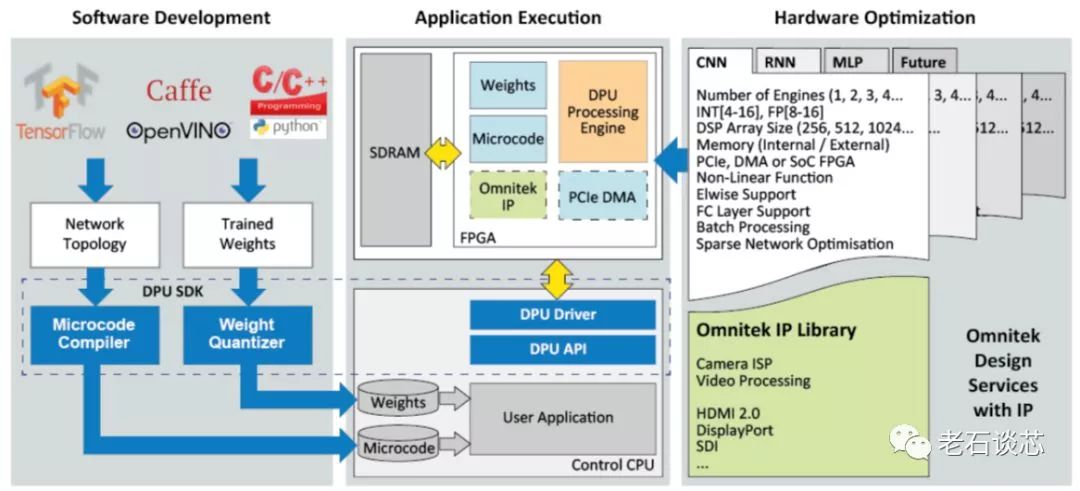
(图片来自Omnitek)
可以看到,用户可以使用TensorFlow、Caffe或者OpenVINO等主流机器学习框架构建的模型,或者是自己用高层语言编写的模型,通过DPU编译器生成特定的微代码(Microcode),这与微软DPU采用数据流图的方式不同。这些微代码将被用来配置FPGA上的DPU数据处理流水线,如下图所示。
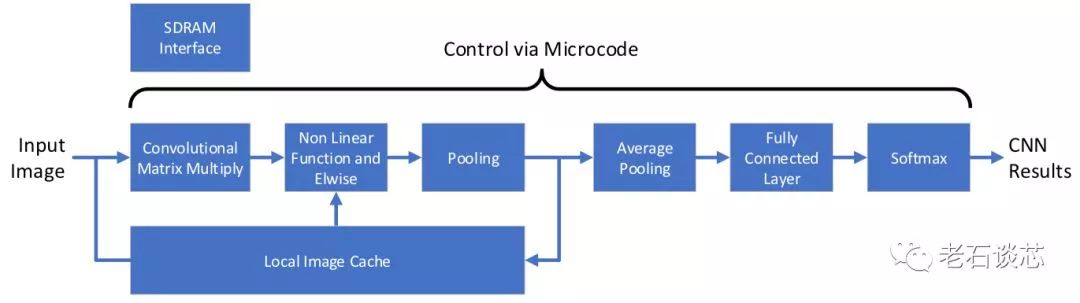
(图片来自Omnitek)
Omnitek DPU的另一个主要特点是可以通过编程,调整对不同DNN拓扑的支持效率。通常来讲,某种DNN硬件加速器往往是针对某种特定的DNN拓扑设计的。以谷歌的TPU为例,它对于阿尔法狗所使用的CNN模型(CNN0)有着很高的运行效率,高达78.2%,平均性能也可以达到86TOPS,见下图。然而对于另外的CNN模型,如GoogleNet(CNN1),谷歌TPU只能达到46.2%的运行效率,性能也骤降至14.1TOPS。
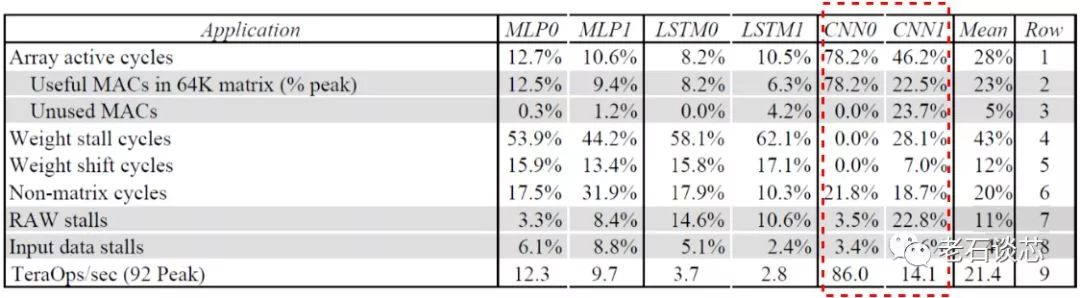
由此可见,不同CNN模型对于单一硬件架构的实际性能有着很大影响。除CNN之外,诸如RNN和MLP等其他DNN拓扑有着和CNN明显不同的特点。除此之外,随着人工智能理论研究的不断推进,想必会不断涌现出其他更加新颖的网络拓扑结构。因此,如果使用相同的硬件架构对这些DNN拓扑“一视同仁”,则必然不会得到满意的性能。
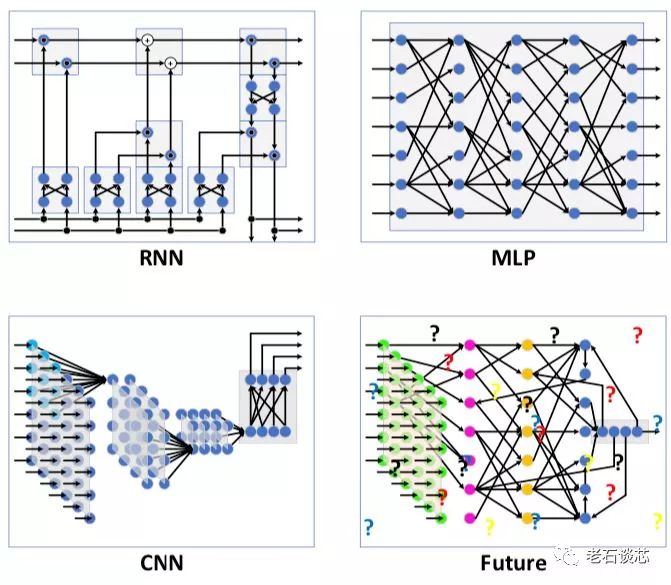
(图片来自Omnitek)
对于这种情况,也只有FPGA能够快速调整硬件结构,以适应不同的网络拓扑结构,这是ASIC或GPU都无法实现的。而这也是Omnitek DPU的另一个主要特点。
此外,Omnitek DPU还使用了“片上网络(NoC)”技术,将多个DPU进行互联和数据共享,如下图所示。NoC是目前在大型芯片上进行数据共享和高速传输的新型技术,在赛灵思最新的ACAP架构上,也使用了NoC技术,这在之前的文章《赛灵思下一代计算平台ACAP技术细节全揭秘》中有过深入解读,有兴趣的读者可以看看,在本文中就不再赘述。
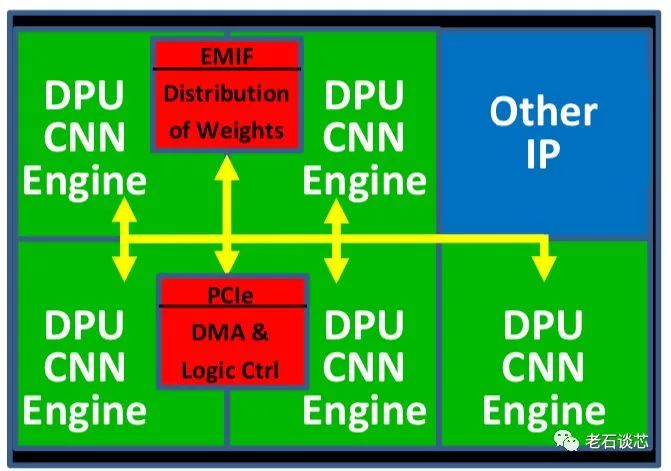
(图片来自Omnitek)
性能方面,Omnitek公布了在英特尔Arria10 GX1150 FPGA上实现的DPU性能数据,如下所示。
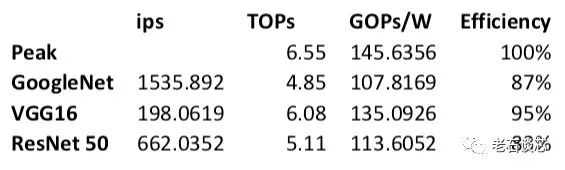
单就上面的数字来看,特别是TOPS一栏,只能说差强人意。不过性能功耗比(GOPS/W)比较高,能够体现FPGA的低功耗优势。同时考虑到Arria10是一款基于20nm工艺的FPGA,因此可以预期当使用更先进的FPGA,如Stratix 10(14纳米)或Agelix(10纳米)时,上面的数字将无疑会有大幅提升。
事实上,Omnitek也有使用赛灵思16纳米UltraScale+ FPGA所取得的性能结果,比上面的数据有着明显提升,本文不再给出,有兴趣的读者欢迎在老石谈芯后台回复“DPU”查看。
结语
Omnitek作为一家做了20年的视频图像FPGA IP提供商,刚刚切入人工智能芯片领域,就依托技术积累开发出了地表最强的深度学习处理器,并随后被英特尔收购,这一系列操作实在让人眼花缭乱。
这次收购对于英特尔而言,不仅补强了其在视频和图像处理领域的FPGA IP组合,更是直接得到了Omnitek已经比较成熟的DPU软硬件方案。这无疑进一步扩展了英特尔在人工智能领域的产品布局和多样性。
Omnitek的官网上列出了很多公司的核心价值观,其中很有趣的一点,就是它允许员工有着灵活的工作时间,因为公司“理解对于所有员工来说,保持‘朝九晚五’的工作时间是很困难的”。这在996盛行的今天,无疑更加值得我们思考,工作和生活,哪个才是我们应该追求的福报。
-
EMC测试整改:提升产品合规性和市场竞争力?|深圳比创达电子2024-03-07 0
-
从天龙八部论嵌入式行业中个人与企业的核心竞争力2013-12-31 0
-
百度总裁:百度在人工智能领域已有重大突破2016-07-01 0
-
嵌入式开发的核心竞争力是什么2017-05-07 0
-
人工智能已经进入医疗领域2017-05-24 0
-
人工智能就业前景2018-03-29 0
-
人工智能的影响超乎你想象2018-06-22 0
-
“洗牌”当前 人工智能企业如何延续热度?2018-11-07 0
-
传感器在新零售时代下具有怎样的竞争力?2018-11-30 0
-
关于嵌入式的技术竞争力2019-05-16 0
-
各路大神对于嵌入式的核心竞争力的看法2019-07-18 0
-
人工智能在哪些方面可以对IT运营产生重大影响 精选资料分享2021-07-12 0
-
人工智能芯片是人工智能发展的2021-07-27 0
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 0
-
《通用人工智能:初心与未来》-试读报告2023-09-18 0
全部0条评论

快来发表一下你的评论吧 !
