

基于动量的迭代算法来构造对抗扰动以攻击黑盒和白盒模型
电子说
描述
编者按:深度模型的精度和速度长期以来成为了评价模型性能的核心标准,但即使性能优越的深度神经网络也很容易被对抗样本攻击。因此,寻找到合适的对抗攻击策略可有效提升模型本身的鲁棒性。本文作者提出了基于动量的迭代算法来构造对抗扰动,有效地减轻了白盒攻击成功率和迁移性能之间的耦合,并能够同时成功攻击白盒和黑盒模型。
一、研究动机
深度神经网络虽然在语音识别、图像分类、物体检测等诸多领域取得了显著效果,但是却很容易受到对抗样本的攻击。对抗样本是指向原始样本中添加微小的噪声,使得深度学习模型错误分类,但是对于人类观察者来说,却很难发现对抗样本和正常样本之间的区别。
生成对抗样本的场景主要分为两种:白盒攻击和黑盒攻击。对于白盒攻击,攻击者知道目标网络的结构和参数,可以利用基于梯度的方法构造对抗样本。由于所构造的对抗样本具有一定的迁移性能(即对于一个模型构造的对抗样本也可以欺骗另一个模型),所以其可以被用来攻击未知结构和参数的黑盒模型,即黑盒攻击。
然而,在实际的应用过程中,攻击一个黑盒模型十分困难,尤其对于具有一定防御措施的模型更加难以黑盒攻击成功。造成此现象的根本原因在于现有攻击方法的白盒攻击成功率和迁移性能之间的耦合与限制,使得没有能够同时达到很好的白盒攻击成功率和迁移性能的方法。
具体地,对于一步迭代的快速梯度符号算法(FGSM),虽然这种方法构造的对抗样本的迁移性能很好,其攻击白盒模型的成功率受到了很大的限制,不能有效地攻击黑盒模型;另一方面,对于多步迭代的方法(I-FGSM),虽然可以很好地攻击白盒模型,但是所构造对抗样本的迁移性能很差,也不能有效地攻击黑盒模型。所以我们提出了一类新的攻击方法,可以有效地减轻白盒攻击成功率和转移性能之间的耦合,同时成功攻击白盒和黑盒模型。
图1:对抗样本示例
二、研究方案
2.1 问题定义
生成对抗噪声本质上可以归结为一个优化问题。对于单个模型f(x),攻击者希望生成满足L_∞限制的无目标对抗样本,即生成对抗样本x^*,使得f(x^*)≠y且‖x^*-x‖_∞≤ϵ,其中y为真实样本x所对应的真实类别、ϵ为所允许的噪声规模。所对应的优化目标为
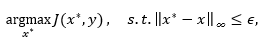
其中J为模型的损失函数,通常定义为交叉信息熵损失。
2.2 相关工作
为了求解此优化问题,Goodfellow等人首先提出了快速梯度符号法(FGSM),仅通过一次梯度迭代即可以生成对抗样本:
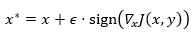
此方法白盒攻击成功率较低。为了提升成功率,迭代式攻击方法(I-FGSM)通过多步更新,可以更好地生成对抗样本,即
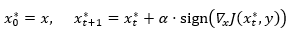
此方法虽然白盒攻击成功率较高,但是迁移能力较差,也不利用攻击其它的黑盒模型。
2.3 动量攻击算法
我们提出在基础的迭代式攻击方法上加入动量项,避免在迭代过程中可能出现的更新震荡和落入较差的局部极值,得到能够成功欺骗目标网络的对抗样本。由于迭代方法在迭代过程中的每一步计算当前的梯度,并贪恋地将梯度结果加到对抗样本上,使得所生成的对抗样本仅能欺骗直接攻击的白盒模型,而不能欺骗未知的黑盒模型,在实际的应用中受到了很大的限制。
在一般优化算法中,动量项可以加速收敛、避免较差的局部极值、同时使得更新方向更加平稳。受到一般优化算法中动量项的启发,在生成对抗样本的迭代方法中加入动量项,可以使得生成的对抗样本不仅能有效欺骗白盒模型,也能欺骗未知的黑盒模型,达到更好的攻击效果。
基于动量的迭代式快速梯度符号算法(MI-FGSM)可以用来解决上述问题,算法为:
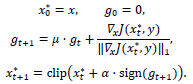
假设以上迭代过程共迭代T轮,为了满足限制‖x^*-x‖_∞≤ϵ,定义每一步的步长α=ϵ/T。μ为动量值g的衰减系数。通过以上迭代过程对一个真实样本x逐步添加噪声,可以得到能够欺骗模型f(x)的对抗样本x^*,同时x^*也能转移到其他未知模型上,导致多个模型发生分类错误。此方法可以被扩展到有目标攻击和基于L_2度量下的攻击。
2.4 攻击多个模型
为了进一步提升黑盒攻击的成功率,我们可以同时攻击多个白盒模型,以提升对抗样本的迁移性能。对于K个不同的模型,目标是使得构造的对抗样本同时攻击成功所有K个模型。为了达到上述目标,首先将K个模型的未归一化概率值进行加权平均,即
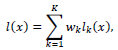
其中l_k (x)为第个模型的未归一化概率值(即网络最后一层softmax的输入);w_k为第k个模型的权重,满足w_k≥0且∑_(k=1)^K▒w_k =11。由此得到了一个集成模型,定义此模型的损失函数为softmax交叉信息熵损失:
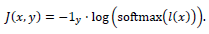
由此可以利用之前所述的基于动量的生成对抗样本的方法对此集成模型进行攻击。
三、算法流程图
算法流程图如图2所示。输入一张原始的图片,其可以被图片分类模型正确分类。通过所提出的基于动量的迭代算法构造对抗扰动并添加到原始样本上,得到了对抗图片,会被图片分类模型所错分。
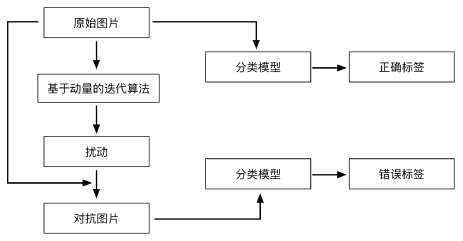
图2:算法流程图
四、实验结果
4.1 数据集
为了测试所提方法的有效性,针对图片分类任务进行对抗样本生成。首先选取7个模型作为研究对象,它们分别为Inception V3 (Inc-v3)、Inception V4 (Inc-v4)、Inception Resnet V2 (IncRes-v2)、Resnet v2-152 (Res-152)、Inc-v3ens3、Inc-v3ens4和IncRes-v2ens。这些模型均在大规模图像数据集ImageNet上训练得到,其中后三个模型为集成对抗训练得到的模型,具备一定的防御能力。本实施选取ImageNet验证集中1000张图片作为研究对象,衡量不同攻击方法的成功率,进而说明其攻击性能。
4.2 评测指标
这里我们选取攻击成功率作为评测指标,定义为原本可以被分类正确的图片中,添加了对抗噪声后被预测为错误标签的图片占的比率。
4.3 实验结果
基于所提方法,我们攻击了Inc-v3、Inc-v4、IncRes-v2和Res-152四个模型,并利用所产生的对抗样本输入所有的7个模型中,测试攻击的效果。为了比较所提出方法的效果,我们还选取了FGSM,I-FGSM两个方法作为基准方法进行比较。实验结果如表1所示:
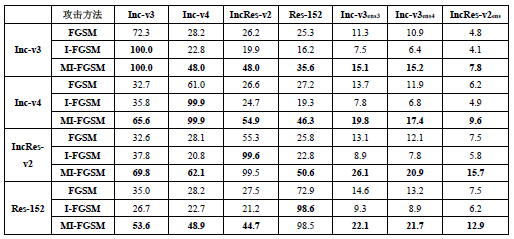
表1:攻击成功率结果
从表中可以看出,所提出的MI-FGSM方法可以显著地提升黑盒攻击的成功率,相比于I-FGSM,我们的方法可以将攻击成功率提升了一倍左右。我们还展示了集成攻击的效果。实验结果如表2所示。
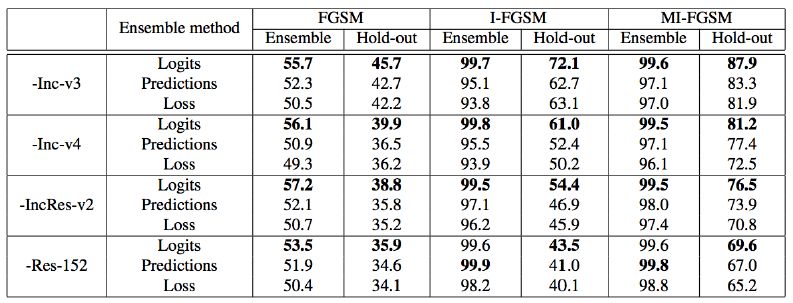
表2:集成攻击结果
从结果中可以看出,所提出的在模型未归一化概率值进行加权平均的方法效果最好。
五、结论与展望
本篇论文证明了深度学习模型在黑盒场景下的脆弱性,也证明了基于动量的攻击算法的有效性。实验中可以看出,所提出的方法对于具有防御机制的模型的攻击效果较差。我们在后续工作中还提出了平移不变的攻击算法(“Evading Defenses to Transferable Adversarial Examples by Translation-Invariant Attacks”, CVPR 2019, Oral),可以将防御模型的攻击效果进一步提升。
-
系统测试、验收测试、黑盒测试、白盒测试、单元测试、集成测试的区别2008-10-22 0
-
HUAWEI DevEco Testing注入攻击测试:以攻为守,守护OpenHarmony终端安全2022-09-15 0
-
简化的位置随机扰动粒子群算法2010-01-09 459
-
抑制非线性扰动的迭代学习控制系统研究2017-11-29 821
-
HIGHT算法的积分攻击2018-02-09 706
-
监测可信度的扰动源定位粒子群算法2018-03-28 742
-
机器学习算法之基于黑盒语音识别的目标对抗样本2018-05-28 3153
-
基于多元LDPC码迭代编码算法的混合校验矩阵构造算法2018-09-23 4462
-
如何用对抗样本修改图片,误导神经网络指鹿为马2018-11-22 5116
-
深度学习模型的对抗攻击及防御措施2021-03-12 935
-
基于SQAG模型的网络攻击建模优化算法2021-03-19 785
-
基于生成器的图像分类对抗样本生成模型2021-04-07 739
-
针对多媒体模型的对抗样本生成与防御方法2021-04-08 504
-
GAN图像对抗样本生成方法研究综述2021-04-28 655
全部0条评论

快来发表一下你的评论吧 !
