

谷歌 | AI再突破,Efficientnets有望成为计算机视觉任务的新基础!
电子说
描述
谷歌人工智能研究部门的科学家认为Efficientnets通过宽度、深度、分辨率三个维度的复合扩展,展现出比现行的CNN更高的精度和效率,将成为未来计算机视觉任务的新基础。
卷积神经网络(CNN)作为人工神经网络的一种,是当下语音分析和图像识别领域的研究热点。
它的人工神经元可以响应一部分覆盖范围内的周围单元,所以对于大型图像处理有出色表现,但是如果要某一点上提高准确性,就需要进行较为繁琐的优化调整。
针对这一现象,谷歌人工智能研究部门的科学家正在研究一种“更结构化”的方式,用以“缩放”CNN,期望获得更好的精度和效率。
最近,他们在Arxiv.org上发表的一篇论文(EfficientNet : Rethinking Model Scaling for Convolutional Neural Networks)并附带了一篇博客文章中对其进行描述。他们声称,这个被称为“Efficientnets”的AI系统,超过了最先进的精度,并且提升了10倍的效率。
这篇论文的作者工程师Mingxing Tan 和谷歌人工智能首席科学家Quocv.le都来自谷歌大脑。
他们认为,模型缩放的传统做法是任意增加CNN的深度或宽度,或者使用更大的输入图像分辨率进行训练和评估。区别于传统方法,他们采用了一组固定的缩放系数来均匀缩放每个尺寸。
图中最右侧就是他们的方案,在宽度、深度、分辨率三个维度进行复合扩展。单一调整一个维度能够获得精度提升,但是随着参数调的越大,精度增益越平滑,改进将会不明显。而联合调整就能够获得相对更好的精度增益曲线。
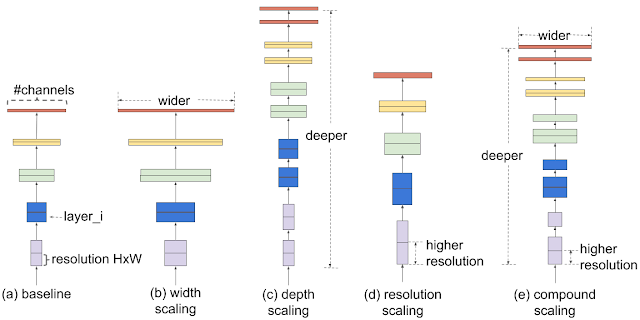
那么,它是如何做到的呢?
首先,在固定的资源约束下,通过进行栅栏搜索,识别基线网络不同维度之间的关系。例如,增加两倍的FLOPS。这决定了每一个维度适当的缩放系数,将应用于基线网络缩放至需要的模型尺寸或者计算预算。为了进一步提高性能,科研人员提出了一种新的基线网络,即MBConv,可以为EfficientNets模型体系提供种子。
在测试的过程中,Efficientnets展现出比现行的CNN更高的精度和效率,将参数大小和FLOPS减少了一个数量级。
其中,Efficientnet-B7比CNNgpipe小8.4倍,快6.1倍,分别在imagenet中上达到了Top-1(84.4%)和Top-5(97.1%)的精度。与resnet-50相比,EfficientNet-B4使top-1精度从ResNet-50的76.3%提高至82.6%。
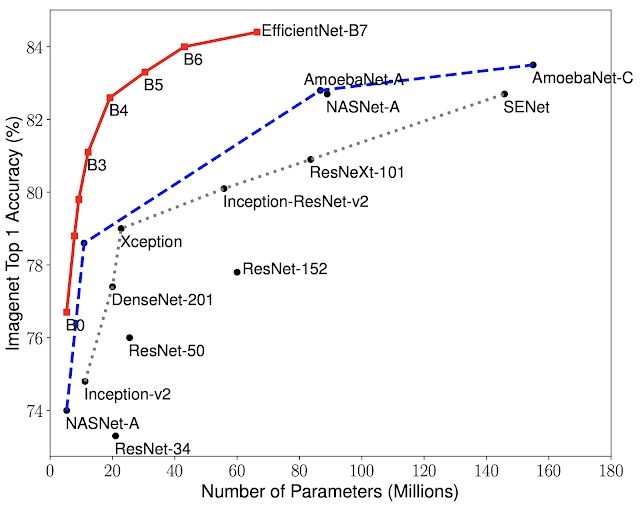
EfficientNets在其他数据集的表现也很好。在5/8的广泛使用的转移学习数据集中,EfficientNets都达到了最先进的精度,并且减少了21个参数。例如,CIFAR-100(91.7%)和Flowers(98.8%),这也表明EfficientNets有很好地转移。
两位作者表示,通过对模型效率的显著改进,EfficientNets有可能成为未来计算机视觉活动的新基础。他们开源了所有EfficientNet模型,希望这些模型可以使机器学习社区受益。
-
自动驾驶系统要完成哪些计算机视觉任务?2020-07-30 0
-
AI视野·今日CV 计算机视觉论文速览2021-07-07 0
-
深度学习在计算机视觉领域图像应用总结 精选资料下载2021-07-28 0
-
计算机视觉论文速览2021-08-31 0
-
谷歌推出新的移动框架MobileNetV2提高多种计算机视觉任务2018-04-07 9088
-
计算机视觉中的重要研究方向2020-11-19 10778
-
用于计算机视觉训练的图像数据集2022-02-12 1158
-
剖析计算机视觉识别简史2021-04-30 2359
-
计算机视觉相关概念总结2023-05-31 509
-
谷歌量子计算机新突破 可几秒内完成47年的任务2023-07-05 1350
-
谷歌披露量子计算机新突破2023-07-05 1178
-
计算机视觉的概念和主要任务2023-07-17 869
-
最适合AI应用的计算机视觉类型是什么?2023-11-15 230
-
什么是计算机视觉?计算机视觉的三种方法2023-11-16 3047
-
最适合 AI 应用的计算机视觉类型是什么?2023-12-18 6842
全部0条评论

快来发表一下你的评论吧 !
