

语音识别技术在智能语音机器人中的应用
电子说
描述
语音识别技术作为当前人工智能落地最成熟的产品,在AI席卷全球时,围绕语音交互的产品之争正愈演愈烈,大到国内外科技巨头、小到个人的创业团队都在暗流涌动,各种智能解决方案层出不穷。也正是因为这种趋势,才造就了人工智能领域内语音交互技术的不断完善和成熟,在技术和深度学习下,不断登上新的高度。
但还是有人会不断询问:现在语音识别真的可以我们比吗?在我们生活中,语言最重要的功能是传递信息,让其他人知道我们的目的。在AI的领域里其实也是这一个功能,只是我们要机器人知道我们要做什么,怎么做。也许这就是关注的语音交互的关键,语音交互之所以越来越被重视,是因为互联网、智能硬件的普及,改变互联网的入口方式,而语音就是最简单的,最直接的交互方式,是通用的互联网输入模式。
AI智能语音技术有力地推动了人工智能与传统电销的深度融合发展。百灵语音机器人作为先进的智能外呼方案,可以自动多路外呼,高并发,效率更高,每日可完成5-10倍的工作量;另外,百灵语音机器人还可以帮助销售人员进行话术设计,保障沟通的有效性,不仅增强了客户的服务体验,还提高了销售人员的工作积极性,全身心地投身到销售工作中。
百灵语音机器人每天可模仿销售精英打1000通次以上电话,筛选、分类、标签意向客户、筛选出来意向客户、自动添加微信,成功率更高,公司销售人员只需要跟进意向客户及后续签单维护工作,帮助用户解决催收,客服,房地产,贷款,保险,教育等行业招人难、留人难、管理难等一系类问题。
除了语音识别,AI在语音合成、对话管理,问答等方面也做了很多工作,还包括在不同端上的信号处理,例如麦克风阵列等等都是要去实践的。这样才能完成语音交互的完整过程。百灵语音机器人拥有前沿技术,和全方位的售后服务。在当前技术下,百灵语音机器人支持支持对话打断,多种线路对接,也可以对接到移动端,还可以转接人工,而随着技术的不断升级,大数据话术库也在不断累积沉淀,百灵语音机器人也在不断自我深度学习,各种新功能将会不断完善,更加完美。
未来语音交互技术可能会大规模应用,这是发展的趋势,并不是每个人都是算法或者人工智能领域的资深专家,需要一个不断学习和迭代的过程。AI技术的应用是一个系统工程,要有足够的耐心去打通产品和体验的优化链路,在应用中不断提升效果。
语音识别技术在智能语音机器人中的应用,一般语音机器人的设计开发主要着眼于“能听会说”,力图利用语音识别和语音合成等技术,将模拟的听说能力赋予机器人并生动地展示给观众,主要应用于展厅博物馆等场景,需考虑到机器人所处环境非常嘈杂,因此对系统的稳定性和抗噪性能都提出了较高的要求。此外,由于参与的观众来自全国各地,涉及不同性别、年龄、地域口音,所以系统声学模型的分类设计、调练和自动切换也是一个重要的设计要素。
智能语音机器人的总体设计
智能机器人与观众采用相互问答的小型对话形式进行交流。为实现上方便,可把问答对话的领域进行合理的限制。除迎宾和问候语外,可以设计4个问题域:有关时间、日期和星期的问答,有关全世界各大城市所在时区和当地时间的问答,100以内的数学四则运算题目的问答,没有关系机器人的身世、本领等自身情况的问答。对于每个限定的问题域,相应词汇表的大小是有限的。在限定领域、有限词汇的条件下,机器人基本可以与观众进行自由问答,并可以在不同的问题与之间相互切换。系统工作流程图如下。
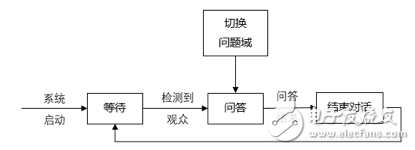
系统启动并初始化后处于等待状态,如果没有观众靠近,机器人就定时反复播放自我介绍。如果有观众参观(由红外探测配合),系统检测到语音信号,便会从等待状态进入问答状态。在观众预先选定的问题域内,机器人将和观众进行“自由”问答,在回答观众提问的同时,机器人会有协调的动作加以配合:针对不同观众对机器人所提问题的不同回答,机器人会有不同的相应,并以此决定下一步的动作。在某些问题域内,机器人在对文档话过程中还会向观众提出一些问题,并等待观众回答。如果观众回答正确,机器人将表示祝贺,否则机器人将给出合理的提示(如噪声太大,讲话声音要大点,没有听清楚或者你的答案不正确等)。多次回答不正确时,机器人将给出正确答案,机器人与观众对话结束后,向观众道别,再次转入等待状态。
核心语音模块及关键技术
语音模块是智能机器人的核心构件,它完成的功能包括:机器人从外界接收观众的语街,送入语音识别器进行识别,再从识别结果中提取若干关键词,而后通过对这些关词的分析,将其映射为某个问题:机器人再针对此问题生成回答,最后将文本形式的答案合成为语音,输出给观众。如果观众的问题超出限定的对话范围或者识别结果可信度不高,则在答案生成阶段给出错误提示,并由语音合成器输出。如果机器人想向观众提出问题,也要由语音合成器合成后输出,模块的整体框架如下图所示。
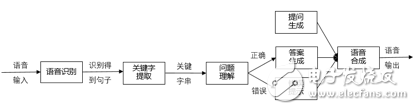
1.问题域相关的数据组织
机器人与观众的问答将限定在某个问题域内进行,针对每个问题域,我们确定了有限大小的“词汇表”,并通过大量的语料训练出相应的基于词类的统计“语言模型”“关键词表”可以从“词汇表”中提炼得到,它记录的是对于理解问题有实质作用的词汇及其相关信息,此外还要在“关键词表”的基础上形成“关键词类型组合模板库”,其中每个模板代表问题域内的一类具体问题。
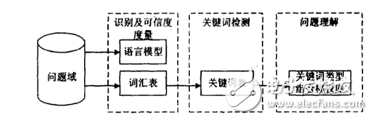
2.识别结果的可信度度量及拒识
从以上框图可以看到,语音识别器的识别结果作为“关键词提取”和“问题理解等后续各个步骤的原始输入,它的正确与否直接影响到整个系的性能。
在限定领域限定词汇量的条件下,如果观众的提问或回答不超出限定的词汇,识别结果的正确率可以达到95%以上。但是,一旦问题超出限定的领域或者出现了集外词,识别器的性能就会严重下降。因此对识别器识别结果的可信度进行度量就显得非常重要,它可以降低集外词(OOV)带来的不利影响。
我们采取的方法是利用统计语言模型衡量识别所得到的整个句子的可信度。如果一个句子的词误识率比较低,构成这个句子的众多三元短语(w1w2,w3),会比较多的出现在统计语言模型Trigram中;反之如果出现较多的识别错误,那么句子中大部分的词w1和元短语(wl,w2)将出现在Unigram或Bigram中,很少有三元短语命中Trigram对于一个由若干词W,W2,,Wi,…Wn构成的句子,我们根据各个词及它所构成的知语在统计语言模型中出现的情况对其中每个词打分。出现在Trigram中的可信度高,因而得分较高,出现在Bigram或Unigram中的可信度低,因而得分较低。再在各个词得分的基础上得到整个句子的可信度得分。若得分低于某个门限,则认为句子中包含较多的识别错误或者集外词,可信度较低,应当被拒识。
3.关键词检测
从识别器得到的识别结果,是由一个个词构成的词序列,其中某些词对于理解整个句子有着非常重要的作用,这就是我们所说的关键词。在这步要做的就是提取出这些关键词,形成一个关键词串,作为下一步问题理解”的输入,这种处理同时也是为了降低“问题理解”时的难度。针对上面提到的四个问题域,我们分别设计了关键词表,预先规定了在这一问题域内的关键词。这个关键表是语音识别系统中相应问题域下的词汇表的子集,记录了每个关键词的汉字串,类标识和词序号等信息。在提取关键词时,只需要在句子中进行搜索,检测到出现在关键间表的关键词,记录它们出现的位置和次序。比如一个句子“请问现在纽约的当地时间是几点钟?”我们可以提取出关键汉字串“现在纽约当地时间几点钟”以及对应的关键词类型串NOWCITY+LOCALTIME+CCLOCK”。对于不包含关键词的句子我们把它视作无效或者错误的输入,给出相应的提示。
4.问题理解和答案生成
“关键词提取”得到的关键词汉字串以及类型串将用于问题理解和答案生成。
在“问题理解”时,主要用到关键词类型串,通过与模板组合库中的模板对照,可以把它映射到某一类具体问题上。比如上面例子中的“NOW+CITY+LOCALTIME+OCLOCK”,就可以映射为“询问某城市的当地时间这类问题。在系统中针对每个不同的问题域,设计了许多关键字类型组合的模板,每个模板对应一类问题。如果关键字类型串成功映射为某类问题,即可转入“答案生成”,否则我们认为问题无效和错误在“答案生成”时,已经明确了问题的类型,相应回答的基本句式就已经确定,所需要的就是给句式赋予具体的内容。利用“关键词提取”得到的关键字汉字串和词序号等信息,可以唯一地确定问题的具体内容,并由此得到问题的最终答案。
以上介绍的是系统的总体结构和流程设计,针对机器人将要长期展出的要求,以及其展出环境比较嘈杂观众类型复杂、年龄跨度大等特点,还有许多实际问题需要解决。比如,针对现场环境噪声和不同的观众类型需要现场采集数据,进行声学模型训练;根据说话人的不同声学特性,要对说话人进行聚类,设计分类的声学模型,并在线选择、切换;另外还要设计不同的问题域,并组织数据和训练相应的语言模型。
-
SPCE061A语音识别机器人应用方案2011-03-08 0
-
智能避障语音遥控机器人2013-10-26 0
-
会物体识别和语音识别的nao机器人2015-02-13 0
-
智能语音机器人2015-12-02 0
-
【龙邱Lark7618试用申请】智能语音机器人2016-05-30 0
-
机器人语音需求2017-06-28 0
-
请问电销机器人智能语音识别的原理是什么?2018-06-12 0
-
AI语音智能机器人开发实战2019-01-04 0
-
【 平头哥CB5654语音开发板试用连载】智能取货机器人语音交互模组2020-02-25 0
-
【 平头哥CB5654语音开发板试用连载】智能语音识别机器人2020-03-13 0
-
AI智能语音机器人 揭秘让企业电销轻松拓客神器2020-07-21 0
-
树莓派的智能语音控制系统2021-09-07 0
-
语音合成技术在智能机器人中的应用2015-12-25 342
-
智能语音机器人的使用误区你知道吗2019-07-04 1022
-
智能语音机器人的使用误区你中了几个2019-07-16 1586
全部0条评论

快来发表一下你的评论吧 !
