

基于80251的嵌入式语音识别
电子说
描述
语音识别技术,广泛来说是指语意识别和声纹识别;从狭义上来说指语音语义的理解识别,也称为自动语音识别(ASR)。其关键技术包括选择识别单元、语音端点检测、特征参数提取、声学模型及语音模型的建立。语音识别技术目前在桌面系统、智能手机、导航设备等嵌入式领域均有一定程度的应用。其主要技术难题是识别系统的适应性较差、受背景噪声影响较大,未来的发展方向应是无限词汇量连续语音非特定人语音识别系统。
(1)信号处理及特征提取模块
该模块的主要任务是从输入信号中提取特征,供声学模型处理。同时,它一般也包括了一些信号处理技术,以尽可能降低环境噪声、信道、说话人等因素对特征造成的影响。
(2)统计声学模型
典型系统多采用基于一阶隐马尔科夫模型进行建模。
(3)发音词典
发音词典包含系统所能处理的词汇集及其发音。发音词典实际提供了声学模型建模单元与语言模型建模单元间的映射。
(4)语言模型
语言模型对系统所针对的语言进行建模。理论上,包括正则语言,上下文无关文法在内的各种语言模型都可以作为语言模型,但目前各种系统普遍采用的还是基于统计的N元文法及其变体。
(5)解码器
解码器是语音识别系统的核心之一,其任务是对输入的信号,根据声学、语言模型及词典,寻找能够以最大概率输出该信号的词串,从数学角度可以更加清楚的了解上述模块之间的关系。
当今语音识别技术的主流算法,主要有基于动态时间规整(DTW)算法、基于非参数模型的矢量量化(VQ)方法、基于参数模型的隐马尔可夫模型(HMM)的方法、基于人工神经网络(ANN)和支持向量机等语音识别方法。
对于语音识别技术实现的描述是相当完整的,而且其可以作为语音识别技术在资源紧缺型嵌入式平台实现的一个较好的参考。
语音识别技术介绍
1.应用分类
(1)特定人与非特定人识别,特定人识别相对简单,训练者的识别率高,但非训练者的识别率很低。而非特定人不受此影响,但实现复杂,识别率也相对低一些。
(2)语音识别与身份识别,前者提取各个命令者发出的语音的共性特征,而后者提取差异性特征。基于语音的身份识别主要应用于门禁等安全领域。语音识别广泛应用于词语识别,工业控制等领域。
(3)连续与非连续(孤立词)语音识别,很明显,连续语音识别难度较大。嵌入式产品集中在孤立词语音识别方面。
(4)小词汇量和大词汇量语音识别。两者选择的方法是不一样的,会在识别率和识别速度上折中考虑。
(5)关键词识别,如在一段语音中抽取带有某个关键词的句子,或者根据哼的曲子旋律去搜索对应的歌曲等等。
本系统受限80251的计算和存储性能,主要实现基于特定人的孤立词语音识别。
2. 实现原理
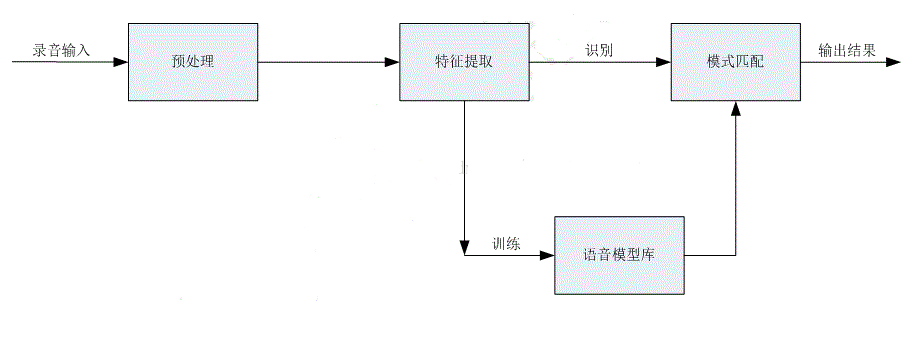
语音识别主要包括:预处理、特征提取、训练和识别四个部分。
预处理主要包括去噪、预加重(去除口鼻辐射)、端点检测(检测有效语音段)等过程。
特征提取是对经过预处理后的语音信号进行特征参数分析。该过程就是从原始语音信号中抽取出能够反映语音本质的特征参数,形成特征矢量序列。主要的特征参数包括:线性预测编码参数(LPC)、线性预测倒谱参数(LPCC)、MEL倒谱参数(MFCC)等。
语音模式库:即声学参数模板,它是用聚类分析等方法,从一个讲话者或多个讲话者多次重复的语音参数中经过长时间训练得到的。
语音模式匹配:将输入语音的特征参数同训练得到的语音模式库进行比较分析,从而得到识别结果。常用的方法包括:动态时间规整(DTW)、神经网络(ANN)、隐马尔科夫(HMM)等。DTW比较简单实用,适用于孤立词语音识别。HMM比较复杂,适用于大词汇量连续语音识别。
三、嵌入式语音识别难点
语音识别的关键是识别率的高低。PC语音识别的识别率主要受限于系统选择的方法,如端点检测的精确度、特征参数的有效性、模式匹配方法的有效性等。而嵌入式的语音识别不仅受选择方法的影响,而且受算法运算精度的影响。PC机主要采用浮点数,而嵌入式主要是采用定点算法,因此运算精度、误差控制非常重要。语音识别算法包括多个模块,多个算法运算过程,累积误差对结果的影响是致命的。所以在算法设计过程中必须要仔细考虑定点数值的精度,既要尽量提高精度,又要防止运算结果溢出。
嵌入式语音识别还需要考虑识别速度。PC机运行速度比较快,中等词汇量语音识别的用户体验还是蛮好的。但在嵌入式语音识别中,词汇量的大小对用户体验的影响是相当严重的。即使识别率高,但识别速度很慢,那这个产品很难推广。所以嵌入式语音识别需要在识别率和识别速度上折中考虑。识别速度不仅受限于选取算法的运算复杂度,还受嵌入式硬件的影响,如数据空间大小。如果数据RAM空间不够大,那就需要以其他介质(如FLASH/CARD)作为缓存。后续处理频繁范围该介质将会严重影响识别速度。所以识别速度也受限于硬件条件。
四、80251平台语音识别的硬件条件及其考虑
1. 80251平台语音识别的硬件条件
这里我们假定SOC集成了251内核,而其能实现录音的功能,这是语音识别的最基本要求。语音识别的硬件条件就是系统分配给录音应用的所有资源。
录音应用的资源一般包括:
1) audio buffer(512字节),其主要是作为audio录音时采样处理后的数据缓存,即采样后audio会把512字节录音数据放到该BUFFER,应用再调用文件系统写接口把该BUFFER数据写到FLASH。
2) EDATA变量数据空间(1024字节),其主要是录音应用和中间件模块的变量数据空间。录音应用和中间件已经用掉622字节,剩下402字节。
3) PCMRAM(12K字节), 其主要是用于录音时的数据采样处理。
4) 代码空间(9K字节),录音应用和中间件代码运行空间。
2. 80251平台语音识别可用资源
在80251平台上实现语音识别就需要在录音应用基础上增加语音识别功能,因此语音识别需要与录音应用共享以上资源。语音识别分预处理、特征提取、训练和匹配识别四个子过程,四个子过程在运行的时间上是不重复的。以下根据各个子过程的运行时间考虑以上资源的复用性。考虑到80251采用硬件BANK机制,所以语音识别的代码空间不受影响。因此着重考虑数据空间的复用性。另外,语音识别一般是对PCM数据进行处理,80251的PCM数据的量化比特数为16BIT,即2个字节。人的有效语音频率在4KHZ以下,所以采用率选择8KHZ,满足奈奎斯特采样定理。
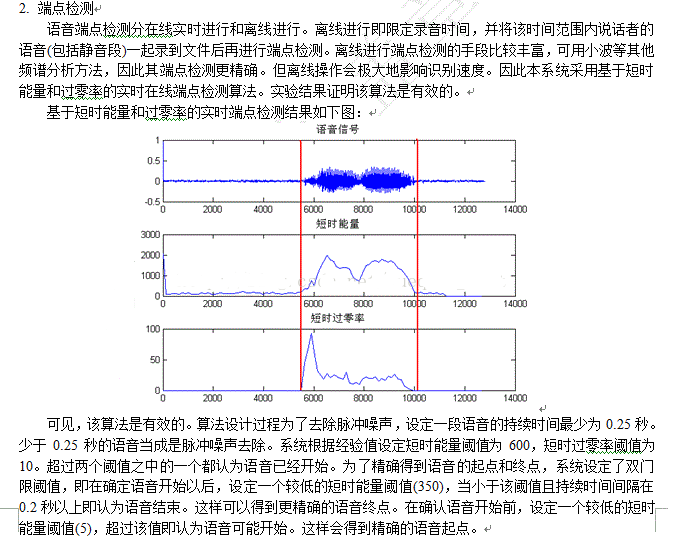
预处理的预加重比较简单,是一个低通滤波器,不需占用额外的数据空间。对于去噪,本系统暂时不予考虑。预处理主要的部分在于语音端点检测,即去除静音段,保留有效语音段。类似于录音中的声控录音,但语音识别的语音端点检测比声控录音更加复杂,也要求更加精确。本系统采用实时在线的端点检测算法,因此在端点检测过程(即在侦听命令的录音过程)需要实时地对audio buffer的数据进行处理,检测是否为有效语音。在这个过程,audio buffer和PCMRAM都是不可使用的。能够使用的就是402字节的EDATA空间。由于语音识别各个过程都要进行分帧处理(后续再讲),本系统设定每帧128点,因此需要申请一个256字节的帧处理BUFFER。剩下402-256 = 146字节作为语音识别的变量数据空间。
在端点检测过程中,根据当前帧的短时能量或者过零率确认语音开始时,对该帧数据的处理有两种,一是将当前512字节数据(一个扇区)COPY到一段语音BUFFER,另一种是调用文件系统写接口写到FLASH中。对于前者,其速度肯定优于后者,因为其不需要在处理的过程中调用文件系统接口。还有,突然的脉冲噪声也会让系统误认为语音的开始,所以在确认噪声后又需重新开始检查。如果有一块大的语音BUFFER,语音识别的性能将会大幅提高。一般认为一个人说出的孤立词语音持续时间在2秒以内,即2×8000×2 ≈ 32K字节。但80251平台明显没有这个资源。所以选择了将当前扇区数据写入文件,即用FLASH作为语音BUFFER使用。另外,80251文件有个缺陷,写操作不能调用FSEEK。这样会带来端点检测速度的下降。如前所讲,脉冲噪声会满足语音开始的条件,因此脉冲噪声起始点之后的一段声音数据都会写入到FLASH文件中,检测算法后来发现前面是脉冲噪声会将之前的数据冲掉,冲头再写。如果能调用FSEEK,那一条语句就完成。但因为该缺陷,因此需要调用FSCLOSE关闭文件,再调用FS_REMOVE删除文件,接着调用FS_CREATE重新创建一个文件。
语音识别后面的3个子过程运行在非录音时态,因此可以利用audio buffer和PCMRAM。由于后续的处理过程都需要从FLASH的文件中读取数据来处理,每次一个扇区,所以用audio buffer作为缓冲。因此语音识别的后续过程可采用的数据空间即是12K字节的PCMRAM。
语音识别的特征提取过程主要需要一个缓冲特征参数的BUFFER。其他需要申请的BUFFER都可以放到FAR DATA空间(即代码空间当数据用,但只允许当前BANK代码能够使用)。如果在对语音分帧进行特征提取并立刻写数据到FLASH特征文件,那也不需要缓冲特征参数的BUFFER,但目前80251平台的文件系统暂不支持一边读一边写,所以必须给特征参数分配缓存BUFFER,等每个语音命令处理后再一起写进FLASH特征文件。以一个命令语音最长2秒计,帧移为64点,则共有2×8000/64 = 250帧,而每帧数据的LPC特征参数个数选16(即算法选16阶LPC,每个参数2个字节),因此共需250×16×2 = 8000字节。考虑到在做模式匹配识别时需要缓冲模块库的一个参考词条的特征参数和待识别词条的特征参数,2个8000字节将超过12K的PCMRAM。所以特征参数的缓冲BUFFER最多只能分配6K。有两个选择,一是特征参数个数选16,那最大的有效语音持续时间为:6×1024/(2×16×(8000/64) = 1.536秒。正常一个人说一个命令的时间约束是可以满足在1.5秒以内的。另一个办法是缩小每帧数据的LPC参数个数,一般语音识别选12阶,本程序为了处理更快,选的是16阶。如果选8阶那会更快,但精度下降。
语音识别的模式匹配过程主要是需要以上讲述的两个缓冲特征参数的BUFFER。由于采用DTW算法,因此算法涉及的中间缓存都分配在FAR DATA空间。
综上所述,80251平台能够在速度受限的情况下实现语音识别功能。
五、语音识别算法设计



六、PC端语音识别算法设计
任何一个移植到嵌入式平台的算法都应该在PC环境上调试验证通过后再进行移植,而为了移植的高效,PC环境的算法设计应该建立在熟悉目标平台的硬件结构和编译集成环境的基础上。尽可能深刻地熟悉两者,将为后面的移植带来极大的好处,否则事倍功半。
1.模拟80251录音过程进行端点检测
PC机用读文件的形式模拟80251录音的过程,详细的端点检测过程如下图:
为了数据的一致性,PC机调试的文件都是80251录出来的录音文件(8K,PCM,16BIT,单声道)。另外,因为80251是分BANK处理语音识别的四个子过程,为了让各个模块去耦合,在WAV文件头的一些保留区写入语音端点检测的有效帧数。这样参数提取过程就可以从文件中直接读出该参数并进行处理。
80251录音结束时会自动准备好文件头所属的一个扇区数据,而这个文件头是包括直接的静音段,所以最后写入文件头时需要对文件头的一些参数(如文件长度)进行修改再写入。
其实,语音数据完全可以作为一个单独的二进制文件存在,并不需要文件头信息。但为了调试的有效性,仍然写入正确的文件头,这样语音端点检测结果仍然是一个WAV文件,通过听这个WAV文件就知道算法是否有效。
算法的结果如果能够图形化那会比较直观,所以借助了MATLAB工具进行画图,以辅助调试,加快调试进度。
2.数据处理精度
80251平台的PCM数据为16比特量化,但事实上语音处理时采用8比特量化就足够了。因此对录音数据的处理都是取高8位。这样减少了一半的运算量,也防止计算溢出。
虽然采用高8位数据进行处理,但为了程序的整体运算平滑过渡,仍然用一个16位有符号短整型去表述每一个采样点。VC为short int,80251为signed int。其获取的特征参数也选用16位有符号短整型去表述。而在运算过程有时会采用32位有符号整型以提高运算精度。
3.类型移植
如上节所讲,为了方便移植,必须让VC中程序的变量和KEIL代码的变量的类型一致。因此在VC中需要重定义一份KEIL环境的typeext.h文件。如:
#define int16signed short int
#define int32signed int
等等。
这样VC的主要算法可以不做任何改动就可以放入KEIL环境进行编译调试。
4.浮点算法定点化
这是语音识别的最关键部分。如果在浮点算法定点化的过程中控制好累积误差,是本系统最关键的问题。第四部分所阐述的算法都是浮点算法。PC上语音识别的识别率很高很大程度一部分原因是因为其选择复杂的算法,另一部分原因是因为它使用浮点数,较好地控制了累积误差。其所有的参数均通过归一化使得运算都在-1到1之间进行。
浮点库对于嵌入式平台是一个极大的负担,而且运算速度很慢。所以嵌入式产品的关键也在于浮点算法定点化过程中如何更好地控制误差。控制误差的一个很有效的方法就是提高数据运算精度,但是一味地提高运算精度会导致运算溢出,所以必须在两者之间折中考虑,以获得一个平衡。
调试此部分功能时曾遇到一个很大的困难就是求取LPC参数时的对E的处理,因为其在循环过程中曾被作为除数进行处理,如果在循环的过程中没做好误差控制,那其就会在某次运算过程中为0,所以造成结果溢出。调试过程还算比较艰辛,曾经让自己想起要不用浮点库试试。但最后还是坚持下来用定点算法继续调试。
针对本系统的算法,浮点算法定点化过程主要做了以下几个方面的考虑。
1. 如5.2节所讲,录音数据采用高8位进行处理。
2. LPC算法的自相关系统进行归一化处理,取12比特有效数据,即R(0) = 4096。而且在运算过程中若发现累积和大于0x7fff时就进行相应移位,保证累积和在0x7fff以内。因为所有自相关系统同时除以一个值,对后面的结果没有影响。
3. LPC算法的E取32位有符号数,算法运算的中间变量也取32位。
4. LPC算的a,k等参数取12位有效数值,即在4096以内。
5. LPC算法中的除法精度到0.5以内,即考虑余数与除数的关系。
6. DTW算法运算使用32位运算精度。
浮点算法定点化调试的一个好的经验时在VC中用两个工程分别实现浮点算法和定点算法,然后跟踪每一步的运算结果。发现误差过大就及时修改调整。
5.速度优化
算法设计时考虑到80251的乘除运算能力有限,所以尽肯能地采用移位,查表操作,以提高运算速度。举例如下:
1. 预加重等过程需要乘以0.9375,就先乘120,再右移7位,即除以128。
2. 窗化处理时如果按公式调用cos等数学函数,那代码量的增长和运算速度的影响都是致命的。在这里使用查表的方式进行处理。即在MATLAB中用hamming(128)得到127点信号点,由于该信号点是-1到1的小数,所以再将其放大1024倍,将这些数值保存到一张表中(使用FAR DATA空间),代码运算时先分别相乘,再右移10位就可以了。所以这里巧妙地避免了除法操作。
七、 80251平台语音识别实现
1.算法移植
由于PC端的算法已经尽可能地考虑了80251的录音过程和KEIL C环境约束,所以算法移植还算比较顺利,尤其是语音端点检测部分。几乎不做任何算法改动就实现了该部分功能。当然录音应用是需要进行调整的。主要的改动主要是UI控制和显示,以及中间件录音流程的修改。即在之前的写入操作前加入调用wav_vad函数进行端点检测,确定语音开始才写进FLASH录音文件。
对于特征提取、训练识别部分的调整,主要是分配好代码运行空间和FAR DATA空间。DTW算法运算过程中的中间变量近1k字节,但由于只有该部分使用,所以都分配在FAR DATA空间。
2. VC和KEIL C的比较
调试过程中还是发现了VC和KEIL C编译器有不一致的地方。但由于比较隐藏,所以发现这部分特性也花费了不少时间。列举几点:
1. int32 m = (int32)(int16 val1* int16 val2);VC会自动把32位的相乘结果赋给m,而KEIL C是将32位相乘结果的高16位清零再付给m。这个好像挺奇怪的,但事实就是这样。只有把前面的强制类型转换去掉才正确。所以有时强制类型转换也未必是好事。
2. VC中用到的一部分BUFFER会自动初始化为0,而KEIL C中不会。所以LPC算法运算结果出现偏差。因为小机和PC的识别率差别很大,所以只好用同一个文件在小机上和PC机上同时调试,以跟踪每一步结果,最终才发现这个问题。其实是编程习惯不够好,一般在使用某段BUFFER前都应该先清零才行。
3. VC中的short int左移会向32位扩展,而KEIL C左移时其数值范围并没有加大,即丢弃超过16位的数值,没能真正实现左移相乘的目的。
八、 80251平台语音识别结果及其分析
80251平台语音识别的识别率可以控制在93%以上(词汇量在50以下,凭经验),50以上还没测试过。
-
嵌入式语音识别技术2016-07-22 0
-
基于TI嵌入式语音识别库的TIDEP0066参考设计2019-03-01 0
-
怎么设计基于嵌入式系统的语音口令识别系统?2019-09-03 0
-
嵌入式语音识别系统与PC机语音识别系统相比有什么优点?2019-11-07 0
-
基于STM32嵌入式的孤立词语音识别系统设计2021-08-06 0
-
怎样去搭建一个基于kaldi的嵌入式在线语音识别系统2021-10-28 0
-
怎样去设计基于嵌入式Linux的语音识别系统2021-11-04 0
-
如何利用ARM实现嵌入式语音识别模块的设计2021-11-09 0
-
嵌入式语音识别系统中的电路设计是如何的2021-12-20 0
-
嵌入式语音识别系统在生活中的应用有哪些呢2021-12-23 0
-
怎样去搭建一个基于kaldi的嵌入式语音识别系统呢2021-12-23 0
-
如何去实现一种基于嵌入式的语音识别智能家居设计2021-12-23 0
-
嵌入式语音识别技术在80251内核中该如何去实现呢2021-12-23 0
-
怎样去搭建一种基于嵌入式平台的在线语音识别系统呢2021-12-23 0
-
分享一种基于嵌入式系统开发语音识别与语音合成应用2021-12-23 0
全部0条评论

快来发表一下你的评论吧 !
