

TensorFlow再填新功能!谷歌宣布推出TensorFlow.Text
电子说
描述
谷歌发布TensorFlow优化新功能TF.Text库,可对语言文本AI模型进行周期性预处理,大大节约了AI开发者对文本模型的训练时间,简化训练流程。
TensorFlow再填新功能!
谷歌宣布推出TensorFlow.Text,这是一个利用TensorFlow对语言文本模型进行预处理的库。TF官博第一时间发布了更新消息,并对TF.Text的新功能和特性进行了简要介绍。
TensorFlow一直以来致力于为用户提供更广泛的选择,帮助用户利用图像和视频数据构建模型。但是,许多模型是以文本开头的,从这些模型构建的语言模型需要进行一些预处理,才能将文本输入到模型中。比如关于使用IMDB数据集的文本分类教程,就是从已经转换为整数ID的文本数据开始入手的。
如果模型训练和推理的时间不一样,在训练过程以外完成的预处理可能会和模型产生偏差,这就需要额外投入更多的时间和精力对预处理的过程进行协调。
TensorFlow本次推出的TF.Text就是为了解决这个问题,TF.Text是一个TensorFlow 2.0库,可以使用PIP命令轻松安装。它可以在基于文本的模型中定期执行这些预处理过程,并提供TensorFlow核心组件中并未提供的、关于语言建模的更多功能和操作。
其中最常见的功能就是文本的词条化(tokenization)。词条化是将字符串分解为token的过程。这些token可能是单词、数字和标点符号,或是上述几种元素的组合。
TF.Text的Tokenizer使用RaggedTensors,这是一种用于识别文本的新型张量。
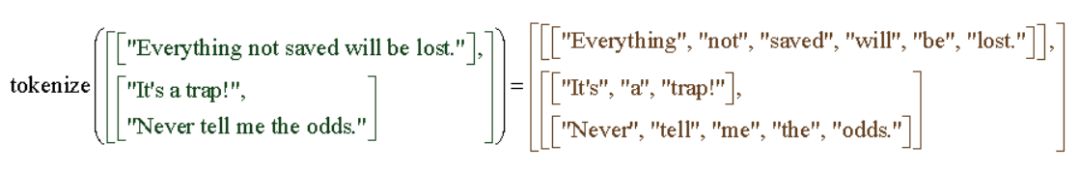
三个新的Tokenizer,系统解决文本AI模型预训练问题
TF.Text提供了三个新的tokenizer。其中最基本的是空白tokenizer,可以在ICU定义的空白字符(例如空格,制表符,换行符)上拆分UTF-8字符串。
tokenizer = tensorflow_text.WhitespaceTokenizer()tokens = tokenizer.tokenize(['everything not saved will be lost.', u'Sad☹'.encode('UTF-8')])print(tokens.to_list())
[['everything', 'not', 'saved', 'will', 'be', 'lost.'], ['Sadxe2x98xb9']]
此次发布的初始版本还包括一个面向unicode脚本的tokenizer,可以根据Unicode脚本边界拆分UTF-8字符串。值得注意的是,它和空白tokenizer很类似,最明显的区别在于后者可以从标准文本(如USCRIPT_LATIN,USCRIPT_CYRILLIC等)中分割出标点符号。
tokenizer = tensorflow_text.UnicodeScriptTokenizer()tokens = tokenizer.tokenize(['everything not saved will be lost.', u'Sad☹'.encode('UTF-8')])print(tokens.to_list())
[['everything', 'not', 'saved', 'will', 'be', 'lost', '.'], ['Sad', 'xe2x98xb9']]
TF.Text中提供的最后一个tokenizer是一个Wordpiece tokenizer。这是一个无监督的tokenizer,需要一个预先确定的词汇表,进一步将token分成子词(前缀和后缀)。Wordpiece常用于谷歌的BERT模型。
def _CreateTable(vocab, num_oov=1): init = tf.lookup.KeyValueTensorInitializer( vocab, tf.range(tf.size(vocab, out_type=tf.int64), dtype=tf.int64), key_dtype=tf.string, value_dtype=tf.int64) return tf.lookup.StaticVocabularyTable( init, num_oov, lookup_key_dtype=tf.string)vocab_table = _CreateTable(["great", "they", "the", "##'", "##re", "##est"])tokens = [["they're", "the", "greatest"]]tokenizer = tensorflow_text.WordpieceTokenizer( vocab_table, token_out_type=tf.string)result = tokenizer.tokenize(tokens)print(result.to_list())
[[['they', "##'", '##re'], ['the'], ['great', '##est']]]
每个Tokenizer都在UTF-8编码的字符串上进行标记,并提供了将字节偏移量转换为原始字符串的选项。调用者可以了解创建的token的原始字符串中的字节对齐。
此外,TF.Text库还包括归一化、n-gram和标记序列约束等功能。
新功能组件密集发布,TensorFlow大家庭日益完善
有关更深入的实例,可以查看Colab notebook内容,其中包含许多本文中未讨论的新的可用操作的各种代码段。未来计划继续提供更多新工具,让使用TensorFlow构建语言模型变得更加方便。
今年上半年,谷歌陆续发布了多个基于TensorFlow的新功能和新组件。5月,谷歌发布TensorFlow Graphics,让机器学习与图形和3D模型的关系更加密切。今年3月,谷歌发布旨在增强隐私保护的终端设备机器学习方法TensorFlow Federated。此外,TensorFlow框架面向JavaScript和iOS开发者的版本TensorFlow.js和TensorFlow Swift也于今年春天发布。
- 相关推荐
- 谷歌
- 模型
- tensorflow
-
关于 TensorFlow2018-03-30 0
-
谷歌深度学习插件tensorflow2018-07-04 0
-
谷歌语音助理服务新功能:可为用户整合日常有用信息2018-07-19 0
-
干货!教你怎么搭建TensorFlow深度学习开发环境!2018-09-27 0
-
深度学习框架TensorFlow&TensorFlow-GPU详解2018-12-25 0
-
情地使用Tensorflow吧!2020-07-22 0
-
TensorFlow是什么2020-07-22 0
-
TensorFlow的特点和基本的操作方式2020-11-23 0
-
TensorFlow是什么?如何启动并运行TensorFlow?2018-07-29 16209
-
谷歌推出了AdaNet,一个基于TensorFlow的轻量化框架2018-11-05 2921
-
TF下载量已超4600万!首届TensorFlow World大会,谷歌大牛Jeff Dean激情演讲2019-10-31 5405
-
谷歌推出开源的量子机器学习库TensorFlow Quantum2020-03-11 2257
-
谷歌TensorFlow 2.4 Mac M1优化版发布2020-12-04 1370
-
tensorflow和python的关系_tensorflow与pytorch的区别2020-12-04 18912
-
TensorFlow 2.4来了 带来了多项新特性和功能改进2020-12-26 2336
全部0条评论

快来发表一下你的评论吧 !
