

什么是AI芯片“存储墙”的解决方案?
描述
最近刚刚看了唐杉博士的《AI芯片的“冷”与“热”》,第一句就是“ 参加过去年硅谷的AI Hardware Summit的朋友,普遍反映这次在北京的会议没有那么火了”。 记得,自己在2016年威海参加中国体系结构年会的时候,孙所也说了一句调侃的话:“现在的AI很火,大家都往那边去,没有人太关心体系结构了,我要告诉那些追AI热点的,它都死了三回了!” 的确,作为从小学马列的中国人,我们最熟悉螺旋式上升的概念。对于计算和I/O来讲,和中国经济调控一样,都是“ 水多了加面,面多了加水”螺旋式上升。
Google在2017年发布了TPU V1之后,现在已经有越来越多的AI startup的芯片出现,大家基本上都是用标准的Resnet50,Googlenetv3 等网络为benchmark, 一次一次地刷新性能和功耗比,个人觉得很有可能在一天,AI芯片的性能和功耗比在特定的imagenet的任务上超过人脑,现在AI在准确率和性能上都超过了。对于AI的芯片来讲,有一个指标也是大家讨论比较多的。Roofline model
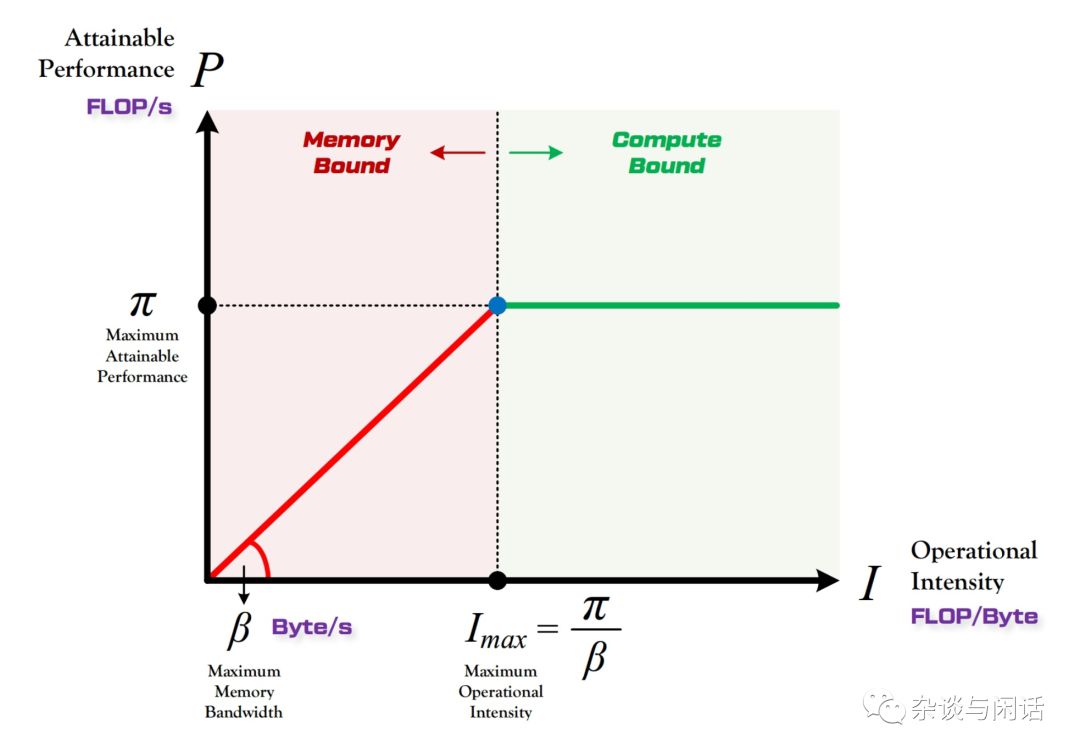
Y轴是P,代表算力,用来FLOP/s来表示,现在新出的AI ASIC往往在FLOP/s并不发力,因为从功耗比的角度上,算力肯定不是越高越好,而且大家都很难高过老黄的核弹。
代表了一个特定的计算平台的peak performance,就是最大算力。
就是特定的计算平台的I内存/O带宽,这个和该计算平台使用的DDR类型有关。
X轴是I,代表计算强度,就是在一个Byte上的计算量。因为对于一个特定的平台,我可以知道它的最大算力 和带宽,我们就可以知道它的最大的计算强度。
因此,和图上显示的一样,在点(Imax,),这个计算平台达到了完美。在它的左边,说明memory受限,在它的右边说明计算受限。
因为对于每一次访存都是32位的Float Point,因此整个内存的占用就是 260MB左右,而计算量是724MFLOPs, 因此Alexnet的计算强度就是724/260=2.7 operation/byte。
对于一个特定的平台,比如老黄家的新的GTX2080Ti 系列来讲:
对于计算性能,先不管老黄加各种Tensor Core,RTcore,从CUDA Core本身来讲,他是100TLOP/s,
它的内存带宽如下:
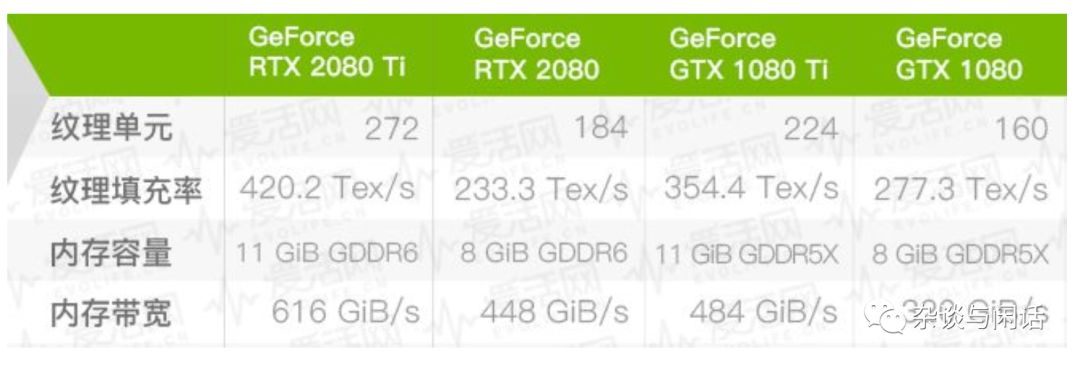
因此,作为2080Ti, 它的Imax就是 166 Operation/Byte.
可能到这个,就可以看出,对于Alex的2.7 来讲,远远没有达到2080ti的计算强度,主要是受限于内存带宽了。
在Google的TPU中,有一个图经常被大家引用。
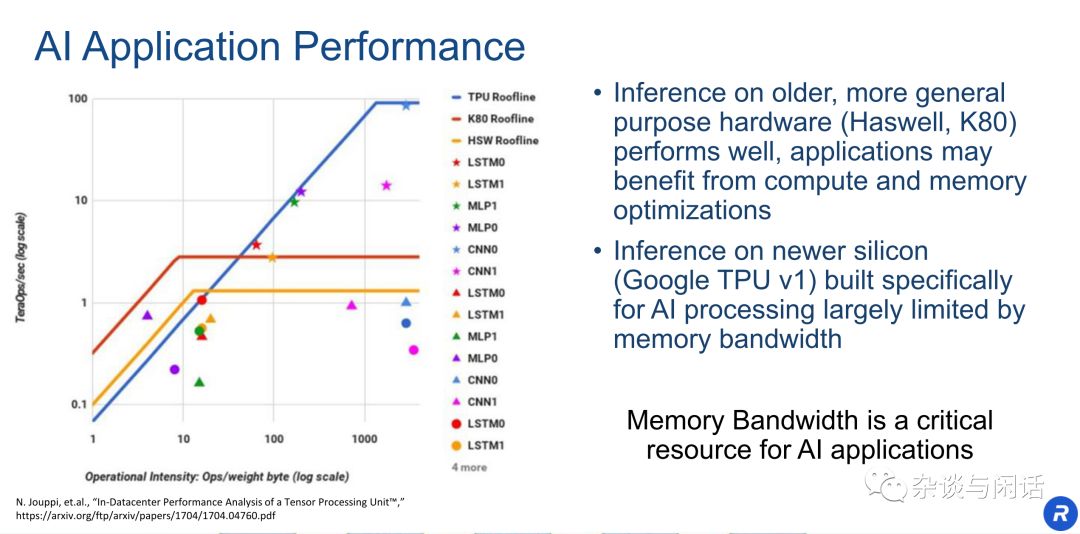
大家基本上可以看到,google的Imax差不多在1000左右,基本上没有什么网络可以完全用满TPU的peak performance。
怎么办,内存带宽的解决方案就是HBM,HBM2, HBM3不断加大带宽。记得在2017年的CNCC上,谢源教授讲,他在2010年左右提出了HBM的概念,他很快就看到了AMD,Nvidia以及Xilinx和Intel都在芯片上使用了HBM,证明了这条道路的正确性。他认为目前应该在AI芯片上摆脱这种”水多了加面,面多了加水“,in-memory 计算应该是下一个方向。
这个就引出了在Memory+会议上来自平头哥的段立德博士的topic,”Processing Near or In memory for deep learning".
-
立体智慧仓储解决方案.#云计算学习电子知识 2022-10-06
-
如何用MRAM和NVMe SSD构建未来的云存储的解决方案2021-01-11 0
-
单芯片FRAM存储解决方案是嵌入式设计的理想选择2021-03-04 0
-
基于AM335x的全彩LED显示墙异步控制卡方案2021-03-11 0
-
断电保持能源存储解决方案2022-09-22 0
-
新思科技发布业界首款全栈式AI驱动型EDA解决方案Synopsys.ai2023-04-03 0
-
存储解决方案(产品指南)2016-01-06 515
-
浅析AI芯片的挑战与解决方案2018-09-07 10471
-
华为发布了AI战略、AI全栈全场景解决方案以及2款华为AI芯片2018-10-11 1130
-
存储优先架构存在优势 或是AI芯片的未来2018-12-26 1810
-
聚焦 | 什么是AI芯片“存储墙”的解决方案?2019-06-18 3244
-
Galileo发布一种1PB存储解决方案 已与axis ai公司的软件集成2019-11-25 1564
-
讨论AI与存储器互连的挑战和解决方案2020-12-09 1144
-
AI系统供电电源芯片及解决方案2021-08-30 4705
-
中科曙光推出AI大模型存储解决方案2023-11-30 371
全部0条评论

快来发表一下你的评论吧 !
