

当Faster RCNN遇到FPGA 自动驾驶技术起飞了
可编程逻辑
描述
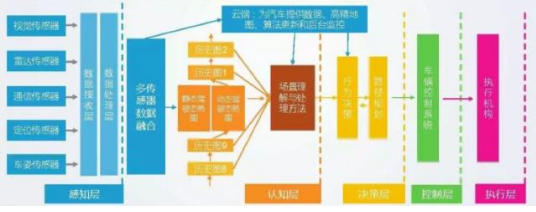
当今的自动驾驶行业是一个百舸争流的局面,总体来看,还是西方引导东方的探索摸索,以 google 为主的以激光雷达为主的流派和以 Tesla 为主的机器视觉流派引导了整个市场。从发展趋势来看,两种方法正在进一步融合,最终会各取优势而相互补充发展。对整个自动驾驶领域,其核心技术是个拟人化的实现过程,即:感知->认知->决策->控制->执行五部分。感知,是所有智能体所要拥有的基本属性,自动驾驶要解决的第一个问题,就是汽车的感知系统,AI 算法的核心就是要解决感知问题。汽车的感知系统是多种传感器融合的系统。
多传感器融合共同组成自动驾驶的感知层已经成为行业共识,这是一个复杂的技术体系,本文主要讨论最主要的感知部分:机器视觉,以摄像头为主的计算机视觉解决方案,为汽车加上「眼睛」,能有效识别周边环境及物体属性。随着 AI 算法的蓬勃发展, 机器视觉由基于规则向基于 CNN 神经网络转变。
国内的主要发展方向集中在视觉上的突破,一种原因是激光雷达和毫米波雷达被国外几个大公司控制,核心技术短期内难以突破,成本居高不下。而做机器视觉, 则成本低廉,且容易上手,国内摄像头的供应链很完善,所以在这种情况下,国内厂商更倾向于 CNN 网络的机器视觉能做更多的事情,其实这种选择是正确的,国内厂商突破的最好的一个点就是视觉突破,视觉方案相对成熟和完善,可以利用国内的一些特点,找到差异化竞争的突破口,快速形成优势,再逐步迭代更新技术。
如开车时任意变道的行为,这个国外的汽车检测方式是等尾部进入车道内再进行检测,这明显不符合国情,所以算法本土化,解决国人开车遇到的问题,就是差异化竞争,这也更需要对算法有自己的把控能力。
所以机器视觉的好的方案已经不单单是好的算法,而是一个在合理的硬件成本里得到一个最优算法的求解问题。由算法来保证识别精度,由硬件来保证算法的实现速度,由成本来保证两者都需要性价比最优的搭配,这才是正确的解决思路。当然,想同时实现上述几点,并非易事。路,要一步一步的走,坑,要一个一个的趟,我们上述的问题一个一个的分析。
在整个 AI 算法的大环境下,车载视觉系统的算法也是基于 CNN 的分割算法,这就引出目前主要的两个算法 Faster RCNN 系列和 yolo 系列,两者各有千秋,前者精度更准,后者速度更快。前者是 two-stage 的方案,即先用最好的网络来找出特征值,然后再调整框来检测目标。后者是 one-stage 的方案,即找特征值和画框在一个网络里完成。
通俗的理解,Faster RCNN 更符合人类「强强联合」的概念,即:找出目前性能最好的网络,然后再组装成一起,产生更优的效果,它是基于多网络融合的方案,所以它的特点就很明确:算的准,但是算的慢。yolo 的诞生,恰恰是解决了这个问题,yolo 的最大的特点就是快到没朋友,但在精度方面却逊色于 Faster RCNN。
这两种方法都有很多变体,one-stage 的方法在精度上不断想与 two-stage 的方法抗衡,two-stage 不断的在加快计算速度,但在数据集上的结论以及越来越快的 Faster R-CNN 变体的可以说明,Faster R-CNN 的 检测精度始终保持领先。但在速度上,yolo 是遥遥领先的。
正是 Yolo 在速度上明显提高,YOLO 的确受到车载系统的青睐,Yolo 真的是车载系统的首选吗?答案未必,正如上文所述,Faster RCNN 的精度是最好的,如果能将其速度也提上去,岂不是更好的选择。首先,前景背景分离的区别。Faster RCNN 是有前景背景分离的。这会要求在训练该网络时需要进行正负样本都要训练,也就是说正确的范畴我要负责,错误的范畴我也要负责。这会大大减少误检率的概率,所以 Faster RCNN 的查全率(recall)会特别的高。
而 yolo 则没有这样的算法结构,它只有正样本训练,不会区分前景和背景的区别。其实这一点是对自动驾驶不太友好的,例如之前 Tesla 的自动驾驶事故就是因为检测算法没有区分前景和背景,将迎面开来的白色卡车和背景中的白云混为一体,从而导致事故发生。
-
汽车自动驾驶技术2016-04-14 0
-
【话题】特斯拉首起自动驾驶致命车祸,自动驾驶的冬天来了?2016-07-05 0
-
自动驾驶真的会来吗?2016-07-21 0
-
细说关于自动驾驶那些事儿2017-05-15 0
-
自动驾驶的到来2017-06-08 0
-
AI/自动驾驶领域的巅峰会议—国际AI自动驾驶高峰论坛2017-09-13 0
-
自动驾驶汽车的定位技术2019-05-09 0
-
如何让自动驾驶更加安全?2019-05-13 0
-
怎么运行Faster RCNN的tensorflow代码2020-06-15 0
-
联网安全接受度成自动驾驶的关键2020-08-26 0
-
自动驾驶系统设计及应用的相关资料分享2021-08-30 0
-
自动驾驶技术的实现2021-09-03 0
-
行业 | 当Faster RCNN遇到FPGA,自动驾驶开始起飞!2019-06-28 3075
-
FPGA技术在自动驾驶的应用2019-08-10 2701
-
都2023年了,Faster-RCNN还能用吗?2023-10-11 387
全部0条评论

快来发表一下你的评论吧 !
