

基于TMS320C6000系列DSP的维特比译码程序优化设计
接口/时钟/PLL
描述
摘要:在软件无线电技术中,经常采用DSP芯片实现信道解码,但维特比译码算法在DSP上的运行速度限制了DSP译码在高速实时系统中的应用。针对TMS320C6000系列DSP的特点,提出了一种优化的译码程序设计方案。利用DSP的并行运算能力,极大地缩短了译码器中“加比选”单元的运算时间。优化后的程序比优化前的译码速度上提高约4倍。当在167MHz的TMS320C6701上运行的时候,对(2,1,7)卷积码的译码速度可以达到870kbps。
卷积码因为其编码器简单、编码增益高以及具有很强的纠正随机错误的能力,在通信系统中得到了广泛的应用。基于最大似然准则的维特比算法(VA)是在加性高斯白噪声(AWGN)信道下性能最佳的卷积码译码算法,也是常用的一种算法。
一般来说,实现软判决维特比译码可以有三种方案供选择:专用集成电路(ASIC)芯片、可编程逻辑阵列(FPGA)芯片以及数字信号处理器(DSP)芯片。参考文献[3]对这三种方案的优劣做了详细的比较。使用DSP芯片实现译码是最为灵活的一种方案,但速度也是最慢的,因为整个译码过程都是由软件来实现的。
在近年来兴起的软件无线电技术中,要求采用可编程能力强的的器件(DSP、CPU等)代替专用的数字电路。对信道编解码而言,这样做的优点在于只需要在程序上加以少量改动,就可以适应不同的编码速率以及各种通信系统所要求的不同的编解码方法。然而速度的瓶颈限制了DSP译码在实时系统中的应用,因此提高DSP的译码速度对于软件无线电有着重要的意义。本文的目的就是通过对译码程序结构优化,来提高DSP芯片执行VA算法的速度。
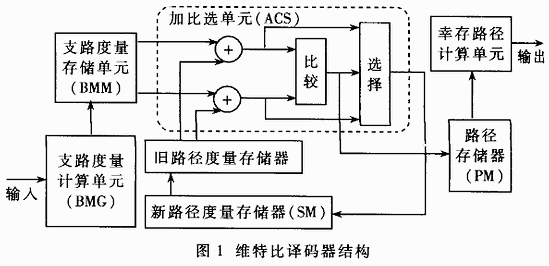
1 维特比译码器
首先,需要定义两个将在本文中用到的术语:
输入帧--每次输入译码器的比特;
输出帧--对应一个输入帧,译码器输出的比特。
图1所示是卷积码译码器(VA算法)的一种典型结构。
以(2,1,7)卷积码为例(输入帧含2比特,输出帧为1比特),来说明译码器的三个主要部分。
1.1支路度量计算单元(BMG)
计算当前输入帧对应的128条支路的路径度量值,并将其存人支路度量存储单元(BMM)。
1.2加比选单元(ACS)
将支路度量值与相连的前面的路径度量值相加得到延伸后的新路径的度量值;比较连接在同一个状态上的两条新路径的度量值;选择其中度量值较小的那条路径(幸存路径),并将它的度量值存储到新路径度量存储器(SM)中,幸存路径值(对应编码状态的输入比特)存储到路径存储器(PM)中。
1.3幸存路径计算单元
找到64条幸存路径中度量值最小的一个(最大似然路径),通过回溯操作(Traceback)在PM中找出该路径对应的所有输入比特,依次输出即为译码结果。
每输出一帧,都对应着一次支路单元计算和64次ACS操作。ACS操作在总的运算时间里占了很大的比例。程序优化的主要工作就是设法减少每个ACS操作所需要的时钟周期数。
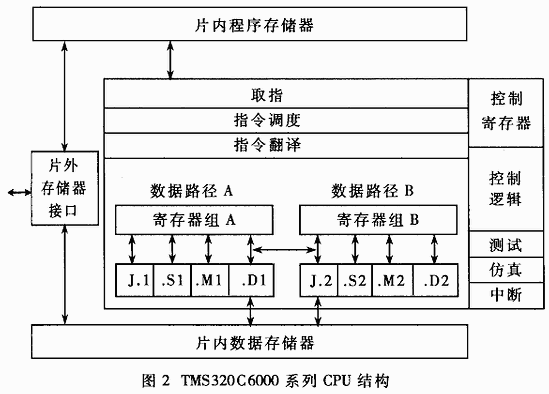
2 TMS320C6000 DSP芯片的特点
TMS320C6000系列DSP是基于TMS320C6000平台的32位浮点DSP处理器。它包含两个子系列:用于定点计算的TMS320C62x系列和用于浮点计算的TMS320C67x系列TMS320C6000系列CPU结构如图2所示。时钟频率最高可达到250MHz。该系列DSP包含两个通用的寄存器组A和B,每组有16个32位的寄存器。芯片内含8个运算功能单元:两个乘法器(.M1和.M2);六个算术逻辑单元(.L1.L2.S1.S2.D1.D2)。所有单元都能独立并行操作。以TM320C6701为例,它的工作频率最高为167MHz,最快速度可达8×167=1336MIPS。
实际上,要实现这个速度存在很多瓶颈,主要有下面几种限制:
(1)功能模块的限制 8个功能模块能够执行的指令不尽相同。在实际程序中,由于程序流程的限制,指令的位置不能随便调换,因此不可能在每一个时钟周期都让8个模块同时工作。程序优化的主要手段就是要提高指令的并行程度,即平均每一周期内同时执行的指令数。
(2)交叉路径(Cross Path)的限制 每一个功能模块都只能对其所属的寄存器组中的寄存器进行直接操作。例如.L1只能将结果直接写入寄存器组A。如果要对另一个寄存器组执行读或写操作,需要用到"交叉路径",而整个CPU中只有两条交叉路径。也就是说,一个周期内至多能同时容纳两个相反方向的交叉读写。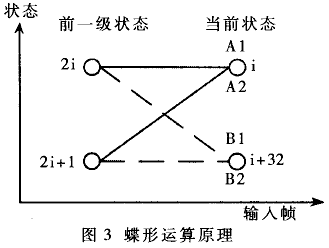
(3)多周期指令的限制 LD命令的功能是将数据从存储器读到寄存器中,由.D模块执行。但执行LD命令后必须等待4个周期才能得到需要的数据。类似这样的需要多个周期才能完成的命令(例如跳转指令B)都成为提高指令并行处理程度的障碍。
(4)对长数据操作的限制 C6000指令集只能以8比特、16比特、32比特或者40比特为单位对数据进行操作。
3 VA在DSP上的优化实现
ACS操作是整个VA算法中运算量最大的部分。在通常的程序设计中,使用一种对称的蝶形运算实现ACS操作,每次可以完成两个ACS操作。因此优化的核心任务就是减少每个蝶形运算所消耗的运算周期数。
蝶形运算的原理请参见图3。对前一级的两个相邻状态2i和2i+1,一共有四条支路。计算出四条支路与接收信号的欧氏距离,与两个前一级状态2i和2i+1中存储的以前路径的度量值相加得到四条路径A1、A2、B1、B2的度量值。然后在对应的两个当前状态i和i+32下两两比较,每个当前状态都留下度量值较小的一条路径(幸存路径),同时将当前状态的度量值以及与幸存路径对应的输入比特存人相应的位置,准备下一级计算。
每个蝶形运算包括:三次加载数据操作(load),因为可以证明一个蝶形中的四条支路的度量具有相同的绝对值,所以每次只需要加载一个由BMU预先计算的结果;四次加法操作;两次比较操作;比较之后的四次存储操作。其中,四次加法操作可以在一个周期内同时完成;状态i和i+32的幸存路径则是独立计算和存储的。
针对前面提到的提高并行处理程度的几个障碍,可以用以下的方法分别加以解决:
(1)解决功能模块的限制 可以用不同的命令相互替代。例如赋值操作MV只能用.L、.S和.D功能模块完成,如果这些模块都被其它的并行指令占用,可以用乘1的方法实现赋值,而乘法指令MPY是用.M单元实现的。类似地,也可以用加零或减零的指令代替MV指令。
(2)解决交叉路径的限制 需要依靠寄存器的分配和倒换,让同一指令涉及到的寄存器尽量处在同一个寄存器组中,减少需要用到交叉路径的机会。 (3)解决多周期指令的限制 加载数据的结果需要在4个周期以后才能得到。为了有效地利用等待的这段时间,在程序设计中把加载数据的指令放在前面的蝶形运算中执行,当进入本次蝶形运算时,就能立即使用加载的新数据。同样,本次蝶形运算也要执行为下一个蝶形运算加载数据的指令。B指令(跳转指令)的问题可以用类似的方法来处理。
(4)解决对长数据操作的限制 在(2,1,7)卷积码的VA译码器中,幸存路径存储在PM里。每一个输入帧对应64个可能的状态,会产生64比特的幸存路径比较结果。但TMS320C6701不能直接对64比特长的数据进行读写操作,所以把PM分成两个相同的32位数组PMO和PMl。前者用来存储状态0-31对应的幸存路径;后者存储状态32-64对应的幸存路径。PM0[i]和PM1[i]合在一起表示第i级网格的所有64条幸存路径。当编码约束长度更大时,也可以用同样的办法来分开存储。例如(2,1,9)卷.积码的PM就可以分成8个32位的数组来存储256个状态的信息。回溯操作的时候,先确定路径经过哪一个状态,就可以从相应的某一个数组中读出路径值,只需要一次LD(加载)操作。
图4给出了优化后的蝶形运算流程图。每次循环需要4个时钟周期,分别为图中的E0-E3,对应着一次蝶形运算。除了一些关键的加比选运算之外,还需要一些辅助运算来实现循环以及寄存器的相互拷贝,平均下来每个时钟周期可并行执行6条指令。
4 优化的效果和推广
译码器输出一帧所需要的时钟周期数为
TBMC+n·TButter+Ttb
其中,TBMC、TButter和Ttb分别表示支路度量计算、蝶形运算以及回溯操作所需要的周期数,n表示每一输出帧对应的蝶形运算的次数。
对于(2,1,7)卷积码译码器,输出一个帧需要32次蝶形运算,因此n=32。在回溯幸存路径的时候,有两种方案输出译码结果:一种是输入一帧码序列,就输出一帧译码结果;另一种是输入N帧码序列,然后输出N帧译码结果。后一种方法输出每一帧所需要的周期数可以减小为Ttb/N,但同时延时也增大为(N-1) TButter/TCPS,其中TCPS是DSP每秒运行的时钟周期数,等于DSP的工作频率。
如果使用TI公司定义的线性汇编语言用图1所示的结构来实现(2,1,7)译码,经过CCS2软件编译并自动进行-o1级优化以后,每译出一个比特,大约需要1000个时钟周期(TButter =22,n=32),时钟为167MHz时译码速度不超过160kbps。
图4
在经过本文所述方法优化以后的程序中,仍然是(2,1,7)卷积码,TBMC =20,TButter =4,n=32;Ttb=700,选择N=16,因此译出一个比特的平均时间是128+20+(700/16)=192个时钟周期。以TMS320C6701为例,它工作在167MHz,该程序的译码速率能达到大约870kbps,而延时仅为18μS。显然,本文中的优化程序性能远远高于自动优化的效果。
对于不同编码约束长度的卷积码,例如WCDMA中用到的(2,1,9)码,蝶形运算单元的流程与(2,1,7)码是完全相同的。不同的地方在于每一级的状态数增加到了256个。因此只需要对程序中的存储和回溯路径的指令做一些改动就可以使用。
对于不同的DSP系统,因为在指令集、总线、寄存器等诸多方面存在差异,针对C6000系列的优化的汇编程序不能直接应用。但译码程序优化中遇到的问题也是大致相同的,优化的重点任务都是设法减少ACS的运算量,因此本文提出的程序流程的基本思想以及一些解决问题的技巧都可以继续加以运用。
- 相关推荐
- 热点推荐
- TMS320C6000
- 译码程序
- TMS320C6701
-
TMS320C6000 DSP外设概述参考指南2024-12-30 592
-
TMS320C6000 DSP EMAC/MDIO模块参考指南2024-12-21 609
-
TMS320C6000 DSP关断逻辑和模式参考指南2024-12-17 428
-
TMS320C6000 DSP的复位电路2024-10-28 786
-
TMS320C6000 EMIF到TMS320C6000主机端口接口2024-10-26 519
-
请问TMS320C6000系列dsp的未使用管脚如何处理?2019-01-14 2100
-
TMS320C6000系列DSP优化介绍2018-04-17 1401
-
基于TMS320C6000的优化策略分享2017-10-25 1482
-
TMS320C6000系列DSP主机引导方式的实现2017-10-20 1411
-
基于TMS320C6000系列DSP的Flash编程方法2017-10-19 1185
-
TMS320C6000系列DSP的CPU与外设2016-05-15 13020
-
TMs320C6000系列DSPs原理与应用2016-05-09 1146
-
急求TMS320C6000系列DSP的书2013-11-09 4386
-
TMS320C6000 系列DSP 的C 代码优化方法2009-05-15 693
全部0条评论

快来发表一下你的评论吧 !

{kind=link}