

智能语音助手的原理_预测智能语音助手的未来
人工智能
描述
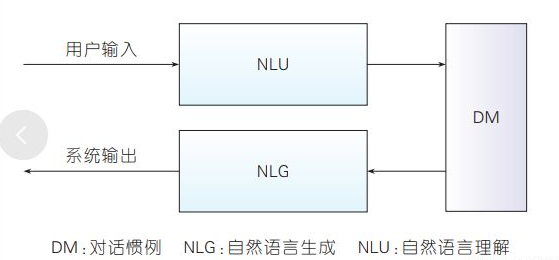
语音助手能和人类进行深度交谈的背后,离不开自然语言处理(NLP)和自然语言生成(NLG)这两种基础技术。机器学习的这两个分支使得语音助手能够将人类语言转换为计算机命令,反之亦然。
什么是NLP?
NLP指在计算机读取语言时将文本转换为结构化数据的过程。简而言之,NLP是计算机的阅读语言。可以粗略地说,在NLP中,系统摄取人语,将其分解,分析,确定适当的操作,并以人类理解的语言进行响应。NLP结合了计算机科学、人工智能和计算语言学,涵盖了以人类理解的方式解释和生成人类语言的所有机制:语言过滤、情感分析、主题分类、位置检测等。
什么是NLG?
自然语言处理由自然语言理解(NLU)和自然语言生成(NLG)构成。NLG是计算机的“编写语言”,它将结构化数据转换为文本,以人类语言表达。即能够根据一些关键信息及其在机器内部的表达形式,经过一个规划过程,来自动生成一段高质量的自然语言文本。
对于“AI语音识别”,每一个“语音识别”都是APP,这个APP里面内置着我们常用字的“标准发音字库“,同时,为了让软件能否识别我们“不标准的发音”,软件还需要AI编程语言对我们不标准的发音做评分,然后做比对,最后选择评分最高的那一个“标准发音”作为我们“不标准发音”的字库!
1.语音识别的基本原理
语音识别系统本质上是一种模式识别系统,包括特征提取、模式匹配、参考模式库等三个基本单元,它的基本结构如下图所示:
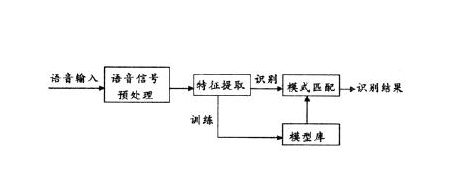
语音识别系统构建过程整体上包括两大部分:训练和识别。训练通常是离线完成的,对预先收集好的海量语音、语言数据库进行信号处理和知识挖掘,获取语音识别系统所需要的“声学模型”和“语言模型”;而识别过程通常是在线完成的,对用户实时的语音进行自动识别。自动语音识别技术有三个基本原理:首先语音信号中的语言信息是按照短时幅度谱的时间变化模式来编码;其次语音是可以阅读的,即它的声学信号可以在不考虑说话人试图传达的信息内容的情况下用数十个具有区别性的、离散的符号来表示;第三语音交互是一个认知过程,因而不能与语言的语法、语义和语用结构割裂开来。
2.工作原理
第一步,把帧识别成状态(难点)。
第二步,把状态组合成音素。
第三步,把音素组合成单词。
3.工作流程
一般来说,一套完整的语音识别系统其工作过程分为7步:
①对语音信号进行分析和处理,除去冗余信息。
②提取影响语音识别的关键信息和表达语言含义的特征信息。
③紧扣特征信息,用最小单元识别字词。
④按照不同语言的各自语法,依照先后次序识别字词。
⑤把前后意思当作辅助识别条件,有利于分析和识别。
⑥按照语义分析,给关键信息划分段落,取出所识别出的字词并连接起来,同时根据语句意思调整句子构成。
⑦结合语义,仔细分析上下文的相互联系,对当前正在处理的语句进行适当修正。
预测智能语音助手的未来
1.语境理解提供个性化回应:目前而言,市场上的智能助理大多缺乏语境理解。
2.语音区分:语音助理或将通过区分语音,提供更多个性化体验。
3.不仅是手机:Amazon Alexa副总裁Steve Rabuchin表示:“我们希望客户可以随时随地访问Alexa,这意味着客户可以通过语音遥控他们的汽车、冰箱、恒温器、灯具以及家中内外的各种设备。“
4.搜索行为的变化:语音搜索一直是热门话题。但语音的可见性将是巨大的挑战。
5.语音通知:在移动应用营销方面,语音智能也提出了新的挑战-用户参与度和维护度。
6.信息安全问题:随着语音支付越来越方便,更多用户选择语音支付。支持智能语音的智能家居设备等也涉及大量用户隐私和用户习惯,其安全性也成为用户关注的焦点。
语音助手
-
智能语音助手在教育行业的应用与挑战2024-01-19 2260
-
智能语音助手在医疗行业的应用与挑战2024-01-18 1390
-
语音数据集在智能语音助手中的应用与挑战2023-12-14 1626
-
亚马逊推可定制的智能语音助手服务Alexa2021-01-18 3456
-
小度智能语音的新旅程:智能语音助手背后的“马斯洛需求模型”2020-11-02 3635
-
智能家居设备有必要植入语音助手功能吗?2020-07-03 4239
-
【 平头哥CB5654语音开发板试用连载】智能声控语音助手2020-02-25 1280
-
索尼将开发用于PS5的智能语音助手2019-10-09 2536
-
语音助手的常见问题有哪些?2019-08-06 8392
-
用语音助手打电话订餐厅2019-06-03 3291
-
语音助手成智能电视标配 真的会用了就离不开语音助手吗?2017-06-12 12230
-
智能语音助手将成为智能家居用户入口2017-05-27 3350
全部0条评论

快来发表一下你的评论吧 !
