

关于三星CPU架构细节分析介绍
电子说
描述
作为今年HotChips会议的重头戏之一,我们很高兴终于看到三星披官方披露了其今年最新新的CPU设计Exynos M3。
今年1月份,媒体首次报道了三星的新微架构的相关信息,从那时起我们就很清楚,这是一个不容忽视的关注点:因为三星在性能方面取得了巨大的提升,这在他们近些年来的硅设计产品上前所未见。
但在接下来的几个月中,对于新款Exynos 9810及其M3内核的披露却越来越少。中间我们有过很多探索,但总不能窥到其内心。当中更是没有三星的任何内容做参考。
回顾三星这系列架构的发展,对产业来说,这是一个很好的创新和推动。
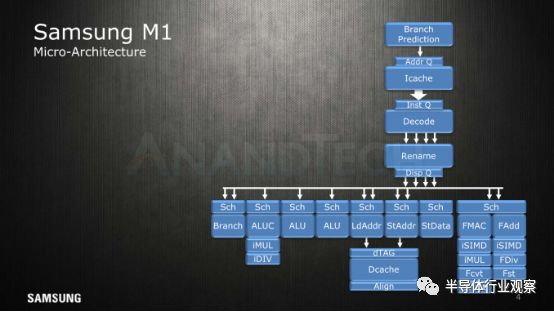
在2016年的HotChips上,三星首次展示了其初代微架构Exynos M1。据了解,三星的CPU IP是在德克萨斯州奥斯汀的“三星奥斯汀研发中心”(简称SARC)开发的,该中心成立于2010年,目标是为三星的S.LSI部门和Exynos芯片组建立内部IP。在这个中心里,有来自AMD,英特尔和其他公司和高等院校的、才华横溢的资深专家,后续的内存控制器和自定义互连的出现,就是他们的工作成果。当然,三星首款定制CPU,更是其中的明星。

据我们了解,三星在2012年就开始了Exynos M1的设计,在经历非常短的开发周期后,这款芯片就Tape-out了。它的首次亮相是在2016年推出的Galaxy S7上,当时这款机器搭载的Exynos 8890就用了这个架构。多年来,SARC一直在向外扩张,2017年,圣何塞的高级计算实验室(ACL)开业并加入了SARC的联合章程——为其设计组合中添加了定制GPU IP,他们希望在几年内将其实现产品化。
Exynos M1是一个从零开始的设计,因此我们很自然期待后续几代人能将其作为进一步开发的起点。随着M1的淘汰,SARC团队在2015年第一季度开始使用现有的M1 RTL设计M3。首先,这是一个增量开发,但在2016年第一季度,由于目标设定得更高,且有更大的性能推动,为此其计划后来有了比较大的变化。
后来三星又推出了M2 ,值得一提的是,由于M2在整个工作负载中有20%IPC改进,所以即使生产芯片的时钟速度降低了12%,但是这它的性能还是优于M1。三星在M2中实现了一些最初计划到M3的一些功能,这就使得新的M3设计变得更加激进。
在这里,三星明确指出了业界最无情的方面之一,那就是在发布周期内,IP和芯片必须同步。我们看到SoC多个供应商的产品,都是为了抓住新产品的商业发布窗口而紧急推向市场。
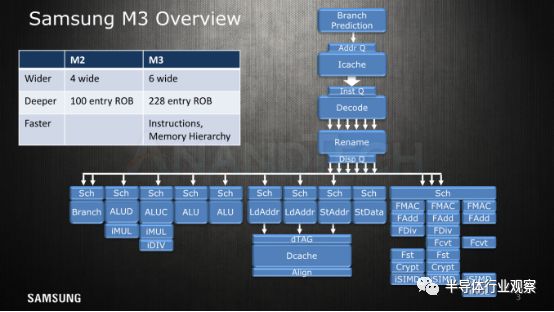
对比Exynos M3的概述以及M1的原始幻灯片,我们看到了很多的相似之处,但M3在桌面上增加了更多。SARC团队将微架构宽度从4宽解码单元(wide decode unit)增加到6,这是新μarch的整体核心特征。我们看到一个新增的带有乘法器功能的整数ALU、第二个负载单元和一个大幅扩展的浮点/ SIMD,这就将计算容量提升了三倍之多。
三星从未真正对M2微体系结构公开,并且也没有与之相关的特定编译器机器模型,但在今天的披露中,我们看到的一个变化是三星进行了从96到100个条目(entries)的微小调整,重新排序缓冲。正如我们在1月份的第一次μarch披露中所提到的那样,M3大大扩展到最多228个条目,这使得μarch从这一方面看,与英特尔的核心设计更为相似(尽管我们无法直接进行不同ISA的密度比较,且随着指令的复杂性而变化)。
当Arm公布了A76的µarch细节,特别是128-entry ROB(这看起来比M3还小)。在他们看来,这是性能和面积/功耗之间的平衡。特别值得一提的是,ROB capacity增加了7%,但只带来1%的性能提升。
三星解释说,ROB capacity是一个选择,它与微架构的其余部分以及各种缓冲区和后端调度程序容量的设计密切相关 - μarch宽度和μarch宽度相互补充以提高性能,而一个如如M3这样的,更广宽度的μarch能够更快地填充ROB,从而从更大的容量中获得更强的性能。总的来说,考虑到提高性能和节省成本,M3采用了与M1 / M2不同的设计。
一个更大的前端
深入了解前端的更多细节,我们看到了分支预测器(branch predicto)和fetch单元的各种改进。M1的分支预测器与其他μarch的不同之处在于它能够在每个周期采用两个分支并且在后端具有两个分支端口。M3似乎保持这个宽度,但是将μBTB从64个增加到128个。mainBTB仍保留在4K条目中,但在采用了分支之后,延迟方面已有了明显提升。
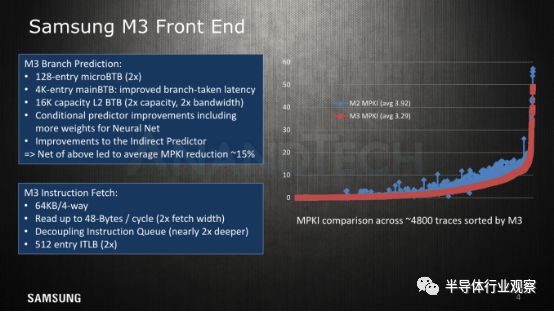
除此之外,分支预测器质量总体上也有了提升,这就使得错过分支平均减少了15%。有趣的是,三星实际上发布了一个实际的MPKI(Misses per kilo instructions)值,这是迄今为止Arm(或任何供应商?)都没有看到的东西。在这里,三星监控来自各种应用程序和用例的,不断扩展的4000-6000代码跟踪套件,以便在开发过程中验证其性能。
分支预测器和fetch单元分别供给decoupled address队列和decoupled instruction指令队列,这样做或者可以使得这些单元在实现中进行时钟门控。
fetch单元的带宽已加倍,现在每个周期最多可读取48个字节,相当于每个周期12个32b指令 ,这就让获取与解码容量的比率变为2:1,比1.5:1的比率有了明显增加( M1中的24B / c,4解码)。三星解释说,以应对更广泛的微架构上越来越大的分支泡沫问题,需要大幅增加这样的设计。他们承认,平均而言,所采用分支之间的距离小于12条指令,但较大的宽度对临时指令突发有很大帮助。
虽然这种变化具有很高的瞬时功率利用率,但是当指令队列(现在是深度的两倍)被填充得比解码单元解码还快时,因为它允许fetch单元被时钟门控,这就使得它对所使用的功率具有整体净正面影响,。在这里,整体能效与分支预测器质量更紧密相关,因为在获取指令时实际上并不重要。
指令缓存/ L1I为64KB。我们不确定这是否比M2增加,因为它很难测量,但它肯定是M1μarch的两倍。
指令转换后备缓冲区(ITLB)已从256个条目增加到512个条目。需要注意的是,三星正在采用三级层次结构,而不是我们在Arm的处理器中看到的结构。A75和A76分别具有第一级32和48条μITLB,其中mainTLB 共有1280个条目,包括1024个条目(页面最大为64KB)和一个辅助256条目表(页数> = 1MB)。
三星也有一级数据和指令TLB,但没有透露L1 ITLB的大小。
Middle-Machine:更广泛的解码,重命名和发送
来到Middle-Machine(解码器,重命名,调度),我们看到了1.5倍宽的解码单元的这个事实。三星在此处未披露任何细节,但它改进了指令/μOP融合功能。重命名和调度吞吐量匹配解码宽度; 这里,重要的是不要尝试过多地解读它并将其与Arm的CPU内核进行比较,因为我们正在谈论不同供应商之间的不同μOP类型。在这里,三星μarch支持自M1以来的多调度形式; 解码器发出一个μOP,可以同时调度到多个调度程序,但在ROB中,他们仍然只将其计为一个调度和一个条目。

在整数核心中,我们看到两个额外的调度器,因此M3现在能够发出9μOps,而不是前代产品的7μOps。其中一个新端口是具有乘法功能的附加ALU单元,使MUL吞吐量加倍,并将简单整数算术吞吐量提高25%。
辅助附加端口是第二负载AGU,其能够使核心的负载带宽加倍。
浮点单位“野兽”
在浮点核心中,我们看到了一个与先前的μarch非常不同的“野兽”。在这里,三星增加了第三条管道,增加了在FPU中发送(dispatched)和发布(issued)的μOP。就简单的浮点能力而言,M3通过3个128b FMAC / FADD单元,使乘法和算术吞吐量增加了三倍。这意味着吞吐量直接从从3 FLOPS(1x FMAC(2)+ 1x FADD(1))增长到6 FLOPS(3x FMAC(2))。
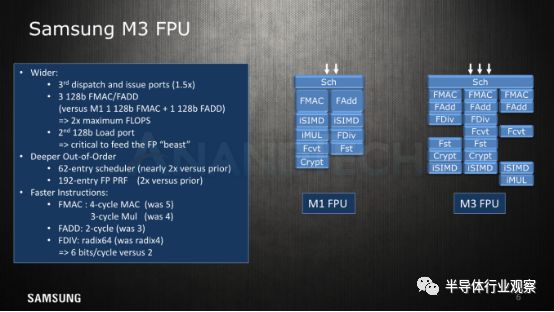
因为执行吞吐量的急剧增加,所以必须扩展调度程序和物理寄存器文件,也就是说将调度程序从32增加到62,将FP PRF从96增加到192个。
三星一直在努力减少执行延迟,这也适用于浮点流水线。在这里,乘法单元已经将周期从4个周期削减到3个周期,这也有利于FMAC从5个周期下降到4个周期。简单的浮点添加将周期从3降到2,与此同时,FDIV能升到Radix-64单元,且显著减少了分区延迟。
在这里稍微提一下,我记得Arm已经在A76中大肆宣传其新的浮点管道已有好几年了,他们为新核心的“最先进”VX数据路径感到非常自豪。但三星似乎在击败了Arm,因为M3具有相同的浮点延迟,同时具有更高的执行吞吐量以及更低的延迟ASIMD功能。当我们可以并排测试硅产品时,我们将来会更详细地比较这些。
新负载/存储单元
在加载/存储单元中,由于增加了第二个128b的负载端口,我们再次看到读取带宽加倍。这里的负载使用延迟在4个周期内保持不变。存储带宽同样有相应的提升。这一代M3具有双带宽优势,因为它的两个LD单元工作在128b /周期,而A75则为64b /周期。

总体而言,LD / ST调度程序的容量已经增加,在存储缓冲区方面,尽管我们没有确切的值,但可以看到也大概增加了一倍。为了更好地服务于更广泛的μarch,L1数据高速缓存上的outstanding misses已从8增加到12,这意味着在高速缓存misses期间,该单元可以提供多达12个并发数据请求,而核心/系统从更高层次获取数据缓存级别或内存。考虑到M3μarch的机器宽度(machine width),这看起来似乎很低 。Arm没有公开披露A75以及此前产品在这方面的规格,但他们将MLP /内存级并行性作为A76披露的一个重点,这里L1D提供多达20个outstanding misses。这比M3可以做的更多。
在这里,三星的预取器需要具有最高质量,以避免任何内存瓶颈,并实现最佳完美cache-hit操作的目标,实际上他们说新的“混合”(hybridized)预取器已经有所增强。在这里hybridized本质上意味着会有更多的预取者,或者单个预取器能够处理不同类型的内存模式。
幻灯片再次提到了我们之前在指令方面描述的新TLB层次结构(hierarchy)。在数据方面,我们看到与M1相同的32-entry micro-DTLB,但是现在有一个全新的mid-level DTLB,它有512个条目。指令TLB和数据TLB现在都由增强的和更大的统一的具有4096个条目的L2 TLB服务,而前一代中只有1024个条目。
核心管道:一切都有成本
扩大微架构需要付出成本代价。与Exynos M1相比,M3在其管道深度上增加了两个周期,并添加了辅助调度阶段(secondary dispatch stage),以及用于寄存器读取(second stage)的第二阶段。通常CPU流水线深度计为从预测/分支到寄存器回写的阶段,在这种情况下,M3在17 stages,而M1为15 stages,A75和A76则为13 stages。

Branch misprediction penalty是16个周期,因为有一个驱动周期(drive cycle)回到前端,再次比M1上的14c penalty多2个周期。如果μarch在各阶段之间存在任何其他快速路径,可以减少关键情况下的延迟,那么三星也不会谈论。M3和M1的缺点是它的Arm对应物位于3对2级取指和解码单元(+2级),2对1级寄存器重命名单元(+1),以及需要第二个调度阶段(+1)。
三星承认,虽然这是一个负面因素,但为了让更大的μarch按计划完成,这是一个必要的“”恶魔,虽然机器在分支误预测方面做得很好,但这是新μarch的一个大成本。
总的来说,三星的微体系结构选择实际上并没有在实际产品中体现出很大的时钟速度优势。这似乎只是让他们在物理设计和限制关键路径方面做得更好,以便在合理的电压下实现更高的频率。
一个新的3级缓存层次结构
远离CPU核心本身,我们正在研究新的L2 / L3缓存层次结构。与A75和A76一样,M3引入了新的私有L2缓存作为核心和共享最后一级缓存之间的中间级别。新的私有L2包含较低的数据缓存,每个核心的容量为512KB。与共享L2相比,M1中的访问延迟从22个周期减少到12个周期。三星在这里的表现,与Arm的A75相比处于劣势,因为据后者的数据显示,其L2 hit 延迟只有8个周期。值得注意的是,在实际物理实现的硅片中,由于RAM和物理布局中的设计选择,这个数字可能会上升。实际上,Snapdragon 845在2.8GHz时的L2延迟测量为 ~4.4ns,而2.7GHz Exynos 9810的数据约为4.6ns。
L2缓存的带宽也增加了一倍,现在实现了32B /周期,而M1则为16B /周期。作为对比,A75从L2读取带宽16B /周期,写入带宽则为32B /周期。
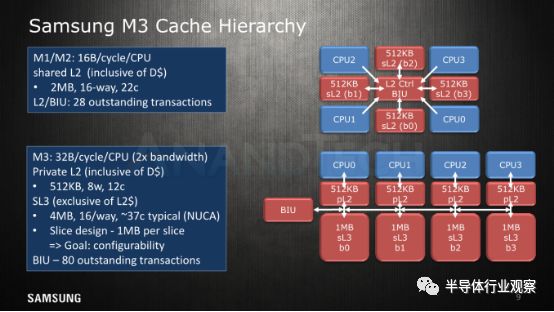
当三星最初公布其Exynos 9810的L3缓存是如何工作的时候,我们感觉是有点混乱的但。最终我们得到了澄清,那就是Arm实际上并没有允许第三方核心插入其DynamiQ集群/ L3系统,也就是说新SoC的硅实现与Arm的对应物无任何关系。
在这里,我们看到以NUCA((Non-uniform cache architecture:非统一缓存架构)方式实现的大型4MB缓存。总共有4个1MB的片(slice),每个“片”位于CPU核心的对面。由于布局不均匀,核心与切片之间的访问延迟并不相同。核心访问相邻切片有32个周期的延迟,但在CPU和最远切片之间的访问则有44个周期的延迟。三星在典型模式中引用了37个周期平均延迟的数据。
在这里,与Arm的方案相比,M3似乎更弱。
Arm A75的L3 hit有25个周期的延迟。在实际中,我们看到Snapdragon 845达到~11.4ns,而Exynos 9810则测得 11ns到20ns之间。虽然DSU较低的最大时钟可能是一个缺点,但实际上它在相反情况下也是一个优势; 当CPU核心的时钟频率降低时,他们仍然可以利用快速运行的DSU / L3缓存及其较低的延迟。相反,M3的缓存层次结构与其CPU内核一起减慢。
M1 / M2的总线单元处理多达28个outstanding misses,而M3处理多达80个未完成的utstanding misses-,如果这应用到L3或者如果在某个方面L2块包含在该图中,则缺乏清晰度。Arm从不谈论A75的功能,但详细说明A76能够处理L2缓存上的46个outstanding misses,在DSU的L3上有94个outstanding misses。
L3切片之间的数据分区由address hash决定,并且所有切片同时通电。相比之下,较大的SoC中的DSU默认使用两个片实现,其中每个片可以是一半断电 -,在断电能力方面给出L3的1/4的粒度。我不确定SD845是如何在这里实现的。
最后,三星解释说,这种切片设计旨在为高端移动设备之外的不同设计实现更好的可配置性,当然这仍然是最优先考虑的因素。但S.LSI在汽车领域也在努力。
对于缓存层次结构总体,三星承认最终产品并未达到他们真正想要的水平。最终产品就像这样,因为必须进行权衡才能获得为这一代实现的3级缓存层次结构。在这里,我认为我们将更加关注下一代M4。
物理布局:理解硅片
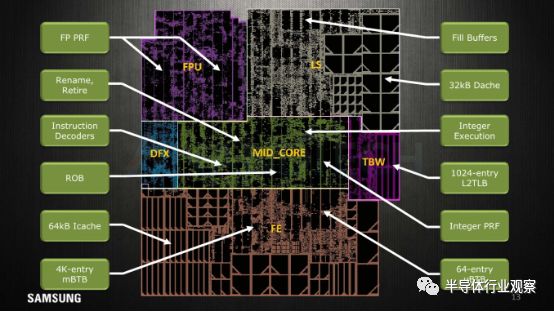
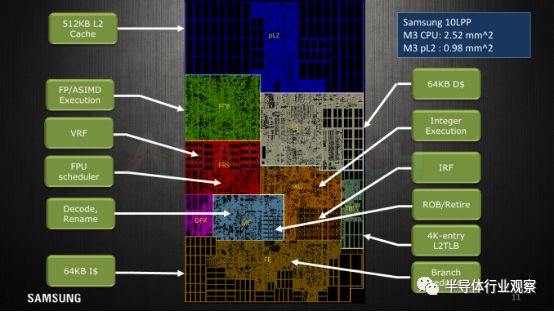
三星今年披露了其芯片的核心平面图,我们很乐于见到这个,以下是对这些术语的一些简短说明:
pL2: Private L2 cache, here we see the 512KB cache implemented in what seems to be two banks/slices.
FPB: Floating point data path; the FP and ASIMD execution units themselves.
FRS: Floating point schedulers as well as the FP/vector physical register file memories.
MC: Mid-core, the decoders and rename units.
DFX: This is debug/test logic and stands for “design for X” such as DFD (Design for debug), DFT (Design for test), DFM (Design for manufacturability), and other miscellaneous logic.
LS: Load/store unit along with the 64KB of L1 data cache memories.
IXU: Integer execution unit; contains the execution units, schedulers and integer physical register file memories.
TBW: Transparent buffer writes, includes the TLB structures.
FE: The front-end including branch predictors, fetch units and the 64KB L1 instruction cache memories.

Exynos 9810平面图
与M1相比,M3中几乎所有功能单元的尺寸都大大增加,最终内核功能模块的面积为2.52mm²,另外还有0.98mm²的512LB L2缓存和逻辑。

Exynos 9810平面图
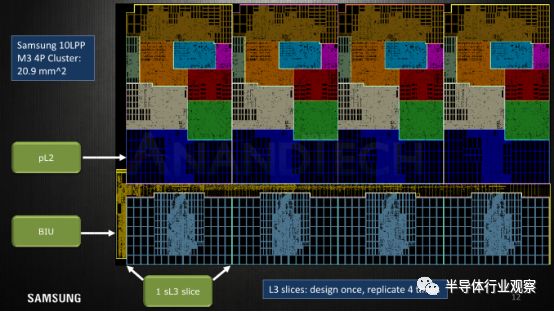
在这里,三星展示了整个集群平面图,再次标记了4个核心,它们彼此相邻排列,L2和L3幻灯片也有序地彼此相邻放置。这种布局似乎节省了一些布局工作,因为每个块设计一次然后简单地复制4次。
IPC提高59%
最后,三星谈了一下他们的性能分析基础架构以及它们如何通过RTL和模型模拟运行各种工作负载跟踪,以便评估设计选择、发现错误并对μarch进行微调。
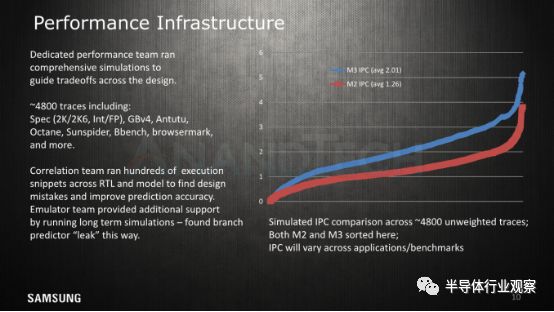
在这张幻灯片中,我们最终得到了核心IPC增长的官方数字:~59%。
正如我们在图表中看到的那样,所有工作负载的增长都不是线性的,切我们看到高ILP工作负载的增长仅有限25%,而MLP工作负载可能则几乎没有增加。另外,还有很多混合工作负载的IPC增加了> 80%。
性能和效率:三星的数据
接下来的幻灯片展示了M2,M3和A75的GeekBench4性能表现。代表产品则分别是Exynos 8895,Exynos 9810和Snapdragon 845。
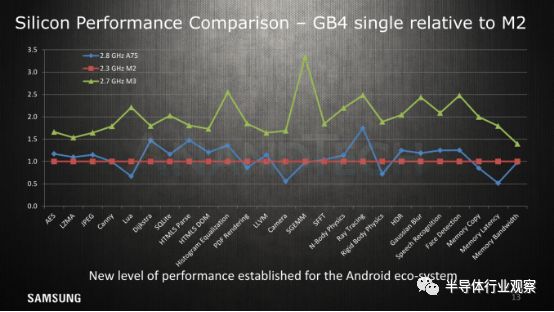
功率效率(Power efficiency)一直是M3的一个重要主题
正如我们在评测中所述,三星的2.7GHz高频率需要非常高的电压和功耗。虽然它展示了领先的性能,但最终效率却低于Exynos 8895的M2。这里的数字代表有源系统功率,这意味着在CPU,内存控制器和DRAM方面,就像我们在AT测量它一样。
将时钟降低到与M2相同的2.3GHz,根据三星的演示,我们在效率方面看到M3的领先。
下图则显示了完成工作负载套件的能源使用情况以及测试期间的平均功耗。左边的条形表示效率,条形越短(焦耳越小),平台效率越高。右边的条代表性能分数,条形越长,性能越好。
我还重新测试了M3的三个顶级频率的工作负载; 1794,2314和2704MHz,让我们更广泛地了解效率如何随性能而变化。
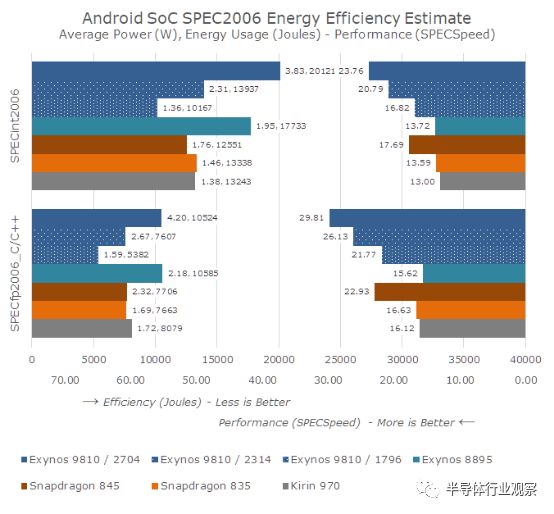
总体而言,M3提供了非常动态的结果范围。在(几乎)等效的峰值性能与这一代的A75竞争结果相比,M3能够发挥良好的效率优势。M3的低性能点仍然优于M2的2.3GHz最高性能 ,同时还具有显著的功率和能效优势。
时钟频率在2.3GHz的时候,M3的性能则明显优于A75。
最后在2.7GHz进一步拉大了性能差距,但效率却很高,比其他任何最新的SoC消耗更多的功耗。
三星的未来战略与结论
最后,三星更多地讨论了该项目的时间表以及如何开展工作。
正如我们在介绍中所说的那样,M3的计划在2014年第2季度开始,随着M1的完成,RTL也在2015年第1季度开始。在这里,三星改变了节奏和规划,将最初计划用于M3的一部分功能放入M2中。在这里,最初的M3计划进行了修订,以便在2016年第一季度实现更大的微架构性能推动。

RTL于2017年第一季度交付给SoC团队,用于Exynos 9810的第一个EVT0流片。值得注意的是,实际生产的硅片是EVT1,其tape-out在2017年中期发生。而最后商用的Exynos 9810在2018年3月上市。
M3对于三星设计团队来说是一次相当大的突破工作,因为他们不得不经历一个近乎项目重构的规划,并且必须应对极端的时间压力。在截止日期前推出下一代产品。
由于时间限制,三星在这个产品上留下了很多的改进空间,特别是微体系结构中较弱的部分之一——缓存层次结构(cache hierarchy,),这是三星方面表示其并不满意的东西,这是推动设计团队努力继续前进的动力所在。
三星不愿意透露任何一种物理实现细节。由于HotChips是一个微体系结构论坛,因此披露信息保留在M3的μarch中。正如我们过去所看到的,当供应商以不同方式实施时,单个微体系结构的性能和功耗特性可能会大不相同。考虑到这一点,在测量最终产品时,很难将硅片的这些相互缠绕的方面分开。
M3看起来像一个整体坚实的微体系结构,感觉更像我们在桌面级产品中看到的。感觉三星在利用μarch的性能方面采取了更直接的方法 ,在许多方面它表现得比Arm更加“凶猛”, 这也解释了M3的硅尺寸比较大的原因。
在评估IP的效率时,查看更高级别的微体系结构是不够的,因为晶体管结构的实际电气工程方面和设计选择中的细节很容易超过任何明显的更高级别特性。况且,没有供应商真的会披露这些细节,更不用说它将远远超出公众读者的范围。
在这里,最后的幻灯片可能是最具启发性的披露,让我们一瞥三星未来的战略:
据说SARC设计团队现在每年都会有强劲的年度发布节奏和持续改进。事实上,当我在询问一些不同的设计选择和规格时,我在M3和A76之间进行比较时,三星提醒我,Arm的新核心的真正竞争将是明年的新款Exynos M4,而不是M3。
到目前为止,我们只发布了两代改进版,但M2和M3的IPC增长率分别为20%和59%,三星确实发布了虽然短暂但非常强劲的追赶轨迹。
就在几天前, Arm公开宣布其性能核心路线图至2020年,揭示了A76继任者Deimos和Hercules,承诺约15%和10%的代际收益。M3在预计性能方面似乎已达到或超过A76(至少在SPEC2006中),因此根据M4的功率效率,我们可能最终看到三星定制设计的竞争优势得到回报。
总的来说,我们感谢三星做了如今所见的微架构披露,作为超越Arm的产品,它们在这个秘密行业中是一个相当罕见的事件。
-
三星CPU架构细节曝光,挑战高通和华为的武器?2018-08-22 10583
-
三星自主CPU架构Exynos M1设计细节大曝光2016-08-30 2705
-
三星面板介绍2009-05-24 4480
-
【讨论】韩独检组批捕三星太子李在镕 会对三星经济造成影响吗?2017-01-20 4461
-
分析:三星芯片业务助推Q3利润创新高2017-10-13 4556
-
大量回收三星高通CPU2020-10-31 1210
-
高价收购三星字库2021-02-23 1215
-
大量回收三星高通CPU 回收三星高通CPU2021-03-10 1516
-
大量回收三星高通CPU 回收三星高通CPU2021-04-14 1593
-
东莞收购三星ic 专业回收三星ic2021-04-28 1476
-
高价回收三星芯片,专业收购三星芯片2021-07-06 1168
-
回收三星ic 收购三星ic2021-08-20 1852
-
专业收购三星芯片 高价回收三星芯片2021-09-03 2035
-
专业收购三星ddr 长期求购三星ddr2021-10-26 1334
-
三星cpu和台积电怎么看_台积电和三星怎么区别_台积电和三星哪个好2018-01-08 8006
全部0条评论

快来发表一下你的评论吧 !
