

关于AI芯片的新动向分析和应用
电子说
描述
在人工智能(AI)领域,由于具有先天技术和应用优势,英伟达和谷歌几乎占据了AI处理器领域80%的市场份额,其他厂商,如英特尔、特斯拉、ARM、IBM以及Cadence等,也在人工智能处理器领域占有一席之地。最近几年,我国国内也涌现出了一批AI芯片公司,如地平线、深鉴科技、中科寒武纪等。
从应用场景看,AI芯片主要有两类,一是部署在以数据中心为代表的云端,其特点是高性能,功耗随之也偏高;另一个是部署在消费级和物联网的终端,其最大特点就是低功耗。
目前,AI芯片的大规模应用场景主要还是在云端。在云端,互联网巨头已经成为了事实上的生态主导者,因为云计算本来就是巨头的战场,现在所有开源AI框架也都是这些巨头发布的。在这样一个生态已经固化的环境中,留给创业公司的空间实际已经消失。
而在终端上,由于还没有一统天下的事实标准,芯片厂商可以八仙过海各显神通。目前,AI芯片在终端的应用场景主要还是手机,各大手机处理器厂商都在打AI牌,生怕错过了热点。
而随着5G和物联网的成熟,广阔的市场空间,为终端侧的AI芯片应用提供了巨大的机遇,而由于物联网终端数量巨大,应用场景繁多,而所有终端几乎都有一个共同的需求和特点,那就是低功耗,从而使其能长时间的稳定工作,不需要人为干预和维护,以降低运营维护成本。
云端AI芯片已经被各大巨头把控,而终端侧又有着巨大的发展空间,这使得产学研各界的众多企业和科研机构在最近两年纷纷投入人力和财力,进行低功耗AI芯片的研发,以期在竞争中占得先机。
VLSI 2018上的中国风
前些天,在美国檀香山召开的2018 国际超大规模集成电路研讨会(2018 Symposia on VLSI Technology and Circuits,简称 VLSI)上,我国清华大学Thinker团队发表了两款极低功耗AI 芯片(Thinker-II 和 Thinker-S)的相关论文,以及一种支持多种稀疏度网络和线上可调节功能的人工神经网络处理器STICKER。
之所以推出以上3款AI芯片,主要基于以下行业背景和需求:深度学习的突破性发展带动了机器视觉、语音识别以及自然语言处理等领域的进步,然而,由于深度神经网络巨大的存储开销和计算需求,功耗成为 Deploy AI Everywhere 的主要障碍,人工智能算法在移动设备、可穿戴设备和 IoT 设备中的广泛应用受到了制约。
为克服上述瓶颈,清华大学 Thinker 团队对神经网络低位宽量化方法、计算架构和电路实现进行了系统研究,提出了支持低位宽网络高能效计算的可重构架构,设计了神经网络通用计算芯片Thinker-II和语音识别芯片Thinker-S。Thinker-II 芯片运行在 200MHz 时,其功耗仅为10mW;Thinker-S芯片的最低功耗为141微瓦,其峰值能效达到90TOPs/W。这两款芯片有望在电池供电设备和自供能IoT设备中广泛应用。
Thinker-S
Thinker-S中设计了一种基于二值卷积神经网络和用户自适应的语音识别框架,同时利用语音信号处理的特点,提出了时域数据复用、近似计算和权值规整化等优化技术,大幅度优化了神经网络推理计算。Thinker-S 芯片采用 28nm 工艺,单次推理计算中每个神经元上消耗的能量最低仅为 2.46 皮焦。
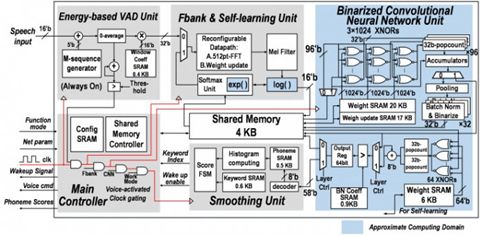
图:Thinker-S 芯片架构
Thinker-Ⅱ
该芯片中设计了两种二值/三值卷积优化计算方法及硬件架构,大幅降低了算法复杂度、有效去除了冗余计算。此外,针对由稀疏化带来的负载不均衡问题,设计了层次化均衡调度机制,通过软硬件协同的两级任务调度,有效提升了资源利用率。Thinker-II 芯片采用 28nm 工艺,通过架构和电路级重构,支持神经网络通用计算。
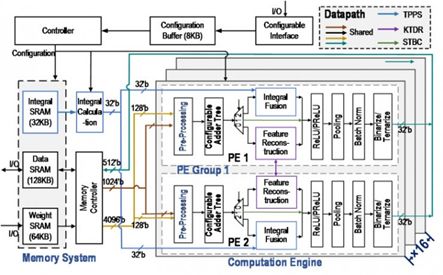
图:Thinker-II 芯片架构
STICKER神经网络加速器
通过动态配置人工智能芯片的运算和存储电路,实现了对不同稀疏度神经网络的自适应处理,大幅提升了人工智能加速芯片的能量效率。该论文作为人工智能处理器分会场的首篇论文,得到了本届VLSI技术委员会的高度认可,一同入选的论文还包含了IBM, Intel, Renesas等公司的相关工作。
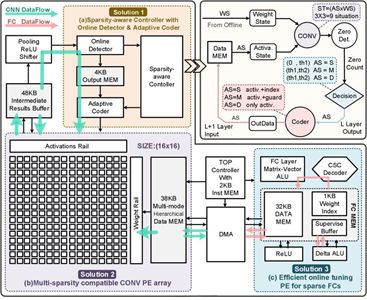
图:STICKER神经网络加速器硬件架构
据悉,STICKER是世界首款全面支持不同稀疏程度网络,且同时支持片上网络参数微调的神经网络加速芯片。通过片上自适应编码器、多模态计算单元以及多组相连存储架构技术,实现了针对不同稀疏程度神经网络的动态高效处理,大幅提升能量效率,并减少芯片面积。针对传统神经网络加速器无法片上调整网络参数以适应物联网应用场景中目标及环境多变的问题,首次使用了片上微调稀疏神经网络参数的技术,以极低的开销实现片上神经网络参数的自适应调整。相比于传统加速器,该工作极限能效高达62.1 TOPS/W(为目前有报道的8bit人工智能处理器的最高值)。

图:Sticker芯片照片
KAIST的DNPU
韩国科学技术院KAIST的Dongjoo Shin等人在ISSCC 2017上提出了一个针对CNN和RNN结构可配置的加速器单元DNPU,除了包含一个RISC核之外,还包括了一个针对卷积层操作的计算阵列CP和一个针对全连接层RNN-LSTM操作的计算阵列FRP,DNPU支持CNN和RNN结构,能效比高达8.1TOPS/W。该芯片采用了65nm CMOS工艺。
ENVISION
比利时鲁汶大学的Bert Moons等在2017年IEEE ISSCC上提出了能效比高达10.0TOPs/W的、针对卷积神经网络加速的芯片ENVISION,该芯片采用28nm FD-SOI技术,包括一个16位的RISC处理器核,1D-SIMD处理单元进行ReLU和Pooling操作,2D-SIMD MAC阵列处理卷积层和全连接层的操作,还有128KB的片上存储器。
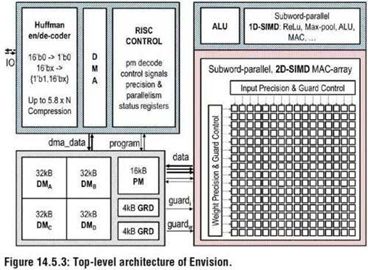
SCALLDEEP
普渡大学的Venkataramani S等人在计算机体系结构顶级会议ISCA 2017上提出了针对大规模神经网络训练的人工智能处理器SCALLDEEP。
该论文针对深度神经网络的训练部分进行针对性优化,提出了一个可扩展服务器架构,且深入分析了深度神经网络中卷积层,采样层,全连接层等在计算密集度和访存密集度方面的不同,设计了两种处理器core架构,计算密集型的任务放在了comHeavy核中,包含大量的2D乘法器和累加器部件,而对于访存密集型任务则放在了memHeavy核中,包含大量SPM存储器和tracker同步单元,既可以作为存储单元使用,又可以进行计算操作,包括ReLU,tanh等。
论文作者针对深度神经网络设计了编译器,完成网络映射和代码生成,同时设计了设计空间探索的模拟器平台,可以进行性能和功耗的评估,性能则得益于时钟精确级的模拟器,功耗评估则从DC中提取模块的网表级的参数模型。该芯片采用了Intel 14nm工艺进行了综合和性能评估,峰值能效比高达485.7GOPS/W。
Myriad X
英特尔为了加强在人工智能芯片领域的实力,收购了机器视觉公司Movidius。
Movidius在2017年推出了Myriad X,这是一款视觉处理器(VPU,visionprocessing unit),是一款低功耗的SoC,用于在基于视觉的设备上加速深度学习和人工智能——如无人机、智能相机和VR / AR头盔。

Myriad X是全球第一个配备专用神经网络计算引擎的片上系统芯片(SoC),用于加速设备端的深度学习推理计算。该神经网络计算引擎是芯片上集成的硬件模块,专为高速、低功耗且不牺牲精确度地运行基于深度学习的神经网络而设计,让设备能够实时地看到、理解和响应周围环境。引入该神经计算引擎之后,Myriad X架构能够为基于深度学习的神经网络推理提供1TOPS的计算性能。
百花齐放
一些传统AI服务厂商将自己的服务进行垂直拓展,比如的自然语音处理厂商云知声从自己的传统语音业务出发,开发了UniOne语音AI芯片,用于物联网IoT设备。
相对于语音市场,安防更是一个AI芯片扎堆的大产业,如果可以将自己的芯片置入摄像头,是一个不错的场景,也是很好的生意。包括云天励飞、海康威视等厂商都在大力开发安防领域的AI嵌入式芯片,而且已经完成了一定的商业化部署。
AI芯片发展趋势
在计算机体系结构顶级会议ISSCC 2018,“Digital Systems: Digital Architectures and Systems”分论坛主席Byeong-GyuNam对AI芯片,特别是深度学习芯片的发展趋势做了概括,去年,大多数论文都在讨论卷积神经网络的实现问题,今年则更加关注两个问题:一,如果更高效地实现卷积神经网络,特别是针对手持终端等设备;二,关于全连接的非卷积神经网络,如RNN和LSTM。
为了获得更高的能效比,越来越多的研究者把精力放在了低精度神经网络的设计和实现上,如1bit的神经网络。这些新技术使深度学习加速器的能效比从去年的几十TOPS/W提升到了今年的上百TOPS/W。有些研究者也对数字+模拟的混合信号处理实现方案进行了研究。对数据存取具有较高要求的全连接网络,有些研究者则借助3D封装技术来获得更好的性能。
总之,AI芯片在终端侧的发展潜力巨大,且应用场景众多,品类也多,这就更适合众多初创的、中小规模AI芯片企业的胃口。相信随着5G和物联网的大面积铺开,低功耗AI芯片将是未来的主要发展方向,只要相关标准能够确定,则商机无限。
-
从2014中国(成都)电子展看测试测量行业新动向2014-05-21 1520
-
【书籍评测活动NO.64】AI芯片,从过去走向未来:《AI芯片:科技探索与AGI愿景》2025-07-28 55381
-
从IIC-China管窥电子制造与测试测量新动向2008-06-13 4210
-
电池韩国KC认证法规新动向2019-03-01 1685
-
AI芯片格局最全分析 精选资料分享2021-07-23 2974
-
【工信部人才培养工程第一期】资深行业分析师解读AI领域动向与就业机会2022-03-15 6333
-
电磁线产品及工艺的新动向2009-06-12 1195
-
技术新动向微生物细菌驱动的电池!2009-10-28 960
-
梳理了部分企业筹划2018年新能源汽车的最新动向2018-01-19 4738
-
我国信息消费新动向与新趋势应用研究分析2021-03-19 1000
-
数字服贸 智启未来 服贸会透露高水平开放新动向2022-09-05 2112
-
2023世亚数博会,世亚软博会|聚焦全球数字科技创新发展新动向2023-06-21 1644
-
国内无线产品核准法规新动向2024-07-23 1500
-
全球芯片市场传来新动向2024-10-17 1638
-
【免费送书】AI芯片,从过去走向未来:《AI芯片:前沿技术与创新未来》2025-07-29 1351
全部0条评论

快来发表一下你的评论吧 !
