

港中文和商汤研究员提出高效的三维点云目标检测新框架
电子说
描述
激光雷达在自动驾驶、无人机和机器人领域受到越来越多的关注,对于点云的分类、检测和分割的视觉任务也在高速发展。但由于激光雷达产生的点云十分稀疏且不规则,图像领域的方法无法有效地拓展到三维点云的分析和处理中。
为了有效处理这一问题,来自香港中文大学和商汤的研究人员们通过对目标的部分感知和聚合对点云特征进行抽取和分析,提出了可以精确预测目标内部相对位置并给出三维候选框的网络架构;同时利用可差分的ROI-aware池化和点云聚合网络对内部信息进行提取和聚合;最后在目标内部各部分空间相关信息的辅助下实现了高效的三维点云目标检测算法Part-A^2 Net (Part-Aware and Aggregation)。
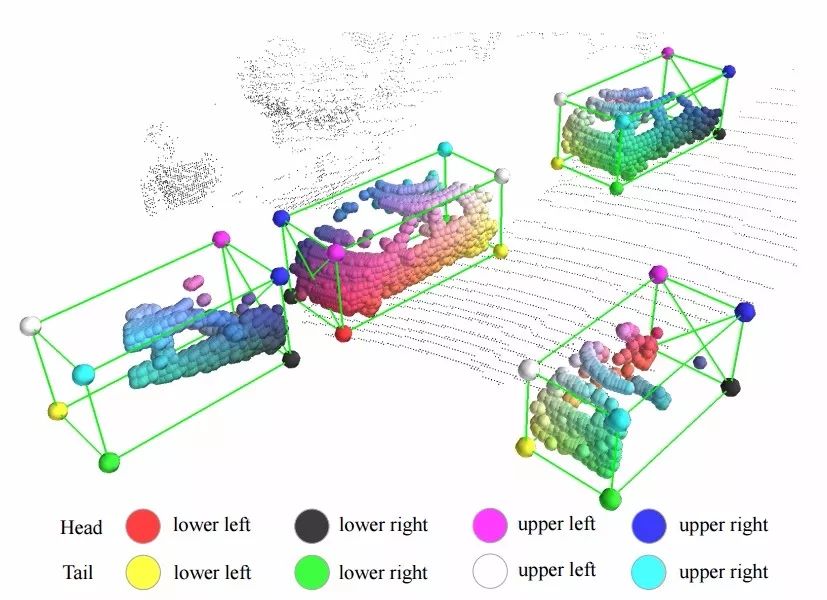
图中可以看到预测出的结果不仅包含了每个框的坐标,目标内部点的颜色还表示了每个点的相对位置,对于提高目标检测的性能十分重要。
目前的三维检测算法主要集中在以下几个方法。
一类方法将点云投影到鸟瞰视图下并利用2D的卷积网络进行特征抽取从而实现三维目标检测;
另一类方法则将三维空间划分为规则的体素,并利用三维(稀疏)卷积进行特征抽取;
还有的方法利用点云与图像结合,在二维图像中检测出目标bbox随后利用PointNet基于2D结果对点云进行裁剪和处理并获取三维框。
但这些方法都会受到来自投影过程、体素量化过程或2D目标检测器造成信息损失的影响,无法精确有效地进行三维点云的目标检测。为了更有效地处理三维点云,研究人员们开始尝试直接从点云中抽取特征生成3D候选框,利用三维bbox标注直接生成对前景和背景进行有效分离的标签。在此过程中研究人员发现三维bbox不仅提供了分割的标签,同时还精确地给出了目标内部各部分精确的相对位置。
与二维图像中会相互遮挡的物体不同,三维点云中的物体都是天然分离的,使得三维目标内部各个部分的相对位置可以精确获取,这些方法将有效提高目标检测方法的性能。基于这样的观察结果,研究人员提出了一个部分感知和聚合的网络结构来进行三维点云目标检测。
研究人员从三维标注数据获得的目标内部各部分的相对位置标签和分割标签来辅助三维候选框的生成过程,随后对每个候选框内的3D目标部分位置进行聚合来为bbox评分并对框的位置进行优化。这种方法为点云处理提供了新的视角,并帮助算法在目标检测中取得更好的结果。
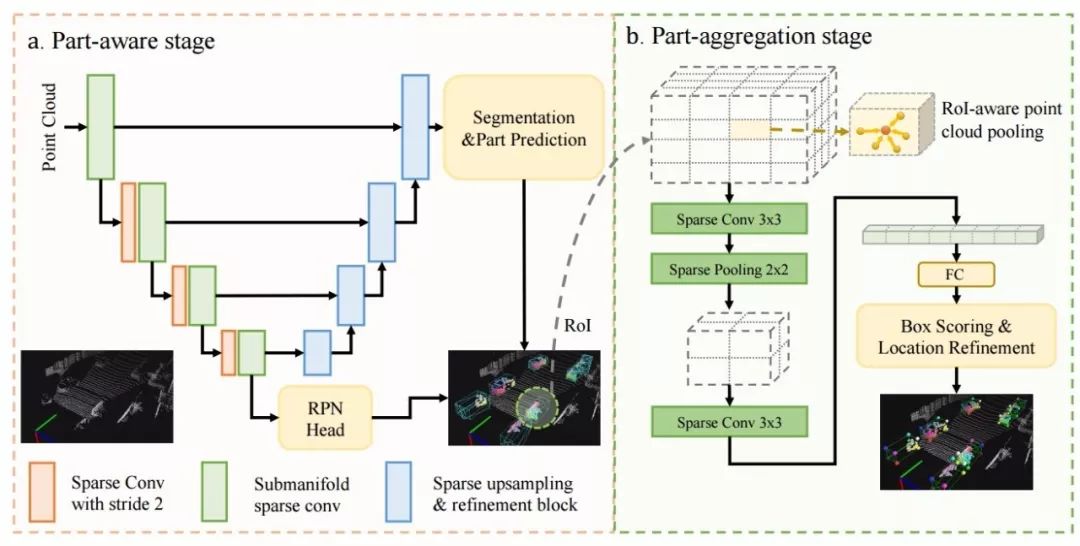
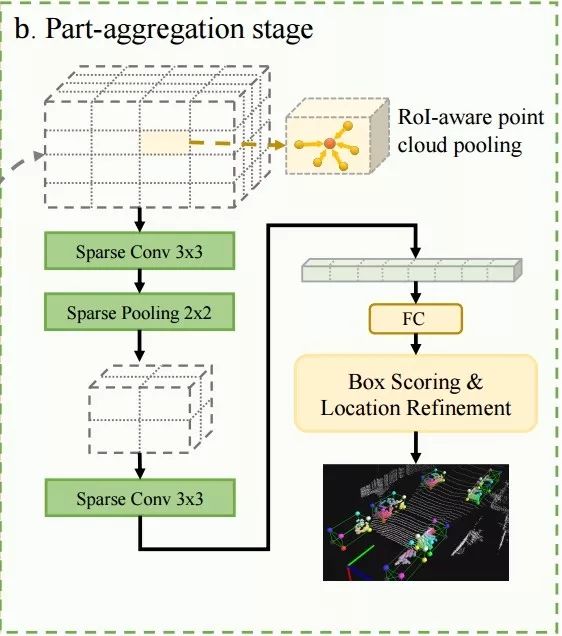
上图中可以看到算法分为了两个主要的部分,部分感知模块用于精确估计目标内部各个部分/点间的相对位置,同时给出三维的候选框;聚合部分针对每个候选框内的点进行ROI池化和分组,实现特征抽取;随后利用聚合网络来对框进行评测并给予内部的相对空间信息对位置进行优化。
估计对象内各部分的位置
为了有效分离出点云中的前景和背景并预测出对象内部各部分的相对位置,需要从点云中获取可分辨的逐点特征。
研究人员首先使用了体素化的三维空间并利用卷积对非空的体素进行特征抽取。每个体素的中心被视为一个新的点,这些点构成了一个与原始点云近似的新点云(体素大小5cm5cm10cm,空间大小70m80m4m)。在使用的KITTI数据中每个数据样本包含了大概16000非空的体素。
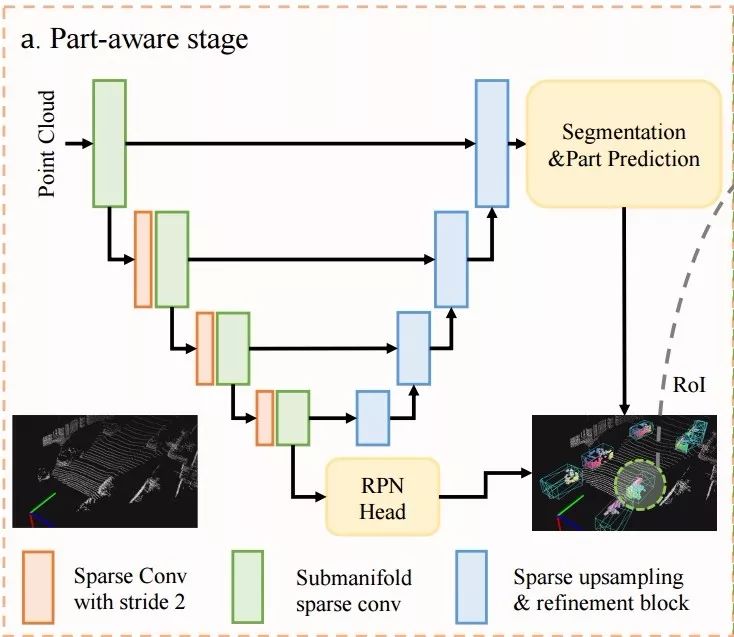
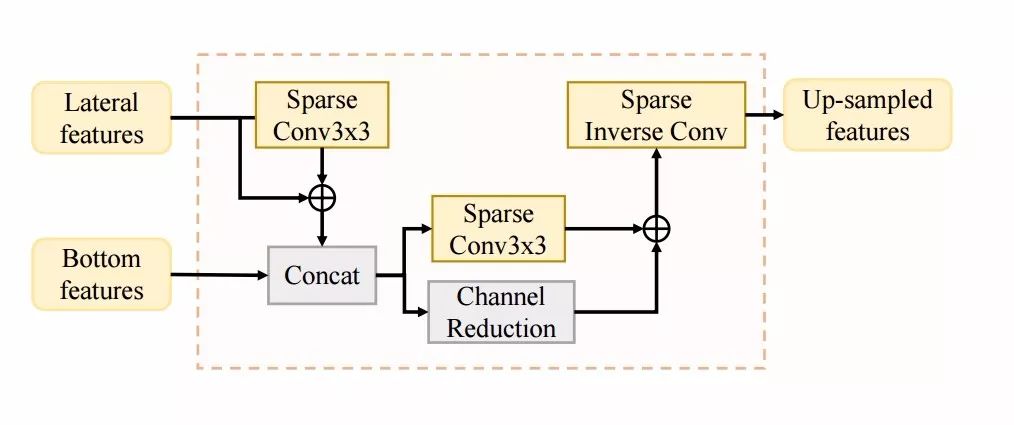
用于特征抽取额U-Net架构和对应的上采样模块
为了对稀疏的体素信息进行高效的处理,研究人员利用U-Net的架构对点云进行了下采样和特征抽取。为了得到前景分割和各部分位置的预测,还需要对进行上采样解码。模块中同时对隐含特征和底层特征进行融合,最后通过稀疏逆卷积实现下采样。
对象内各部分的相对位置信息是网络对目标进行识别和检测的保证。例如车辆的侧面几乎是垂直于地面的,而轮子是与地面相接触的。通过学习和估计前景分割和目标内部各个点的相对位移关系将使得网络可以学会推理出目标的位姿和形态,提高检测性能。在U-Net主干网络的基础上,模型通过两个分支分别进行前景分割和目标内部个部分的位置预测。针对目标内部的点,需要先将全局的三维坐标转换为局部的坐标进行分析。在三维点云的bbox中天然的包含了框中每一个点在对象内部的坐标。研究人员通过将目标内部的点转换到框原点坐标系中并利用框的w,l.h来归一化,得到了内部点在内部坐标系下的新表示,并作为预测内部各部分点相对位置的标签。网络将通过优化二值化的交叉熵来实现对于每一个对象内部点相对位置的预测。
最后为了生成三维候选框来聚合各个目标内部的位置信息,研究人员在U-Net的特征图位置补充了一个RPN(regional proposal network)结构,通过对1/8下采样的特征图和不同高度融合的鸟瞰特征图进行处理生成3D候选区域。
具有ROI感知的点云特征池化
在得到目标内部各个的相对位置和一系列的三维候选框后,将要对box进行评分,并通过聚合同一候选框内的所有点的相对信息来实现候选框的位置优化。
为了避免池化带来了信息损失和模糊,研究人员提出了ROI感知的点云池化模块,将3D候选分配到固定大小(14*14*14)的均匀体素中去。体素中的特征通过(最大池化,均值池化)聚合内部点的特征来得到,并将空体素的特征设置为0。池化过程中联合编码空体素。这一过程将不同的三维候选框归一化到了相同的坐标系下,其中每个体素都编码了对应候选框中栅格特征。
内部位置的聚合与三维bbox的优化
研究人员通过聚合候选框内部所有三维点的内部相对位置来评价候选框的质量,并通过基于学习的优化方法来解决这一问题。
针对每个三维候选框,首先通过平均池化预测每个点的位置,通过最大池化获取每个点的特征。随后通过逐级处理的方式来最终预测最终的得分与优化后的bbox坐标。
结果
在实验过程中,研究人员结合了三部分的损失函数来对模型进行了训练,分别是复杂前景分割的focal损失,负责回归每个内部点相对位移的二进制交叉熵以及负责进行三维候选框生成的平滑L1损失。
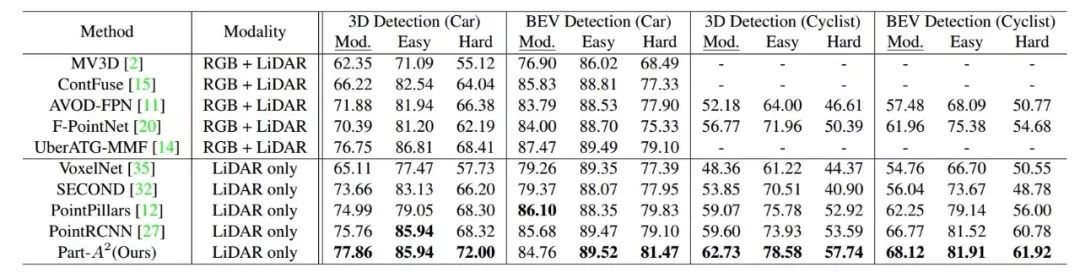
针对聚合阶段还包括了IoU回归的二进制交叉熵以及位置优化的平滑L1。研究人员在KITTI上进行了实现,下表显示了这一方法在平均精度上显著高于先前的解决方案。
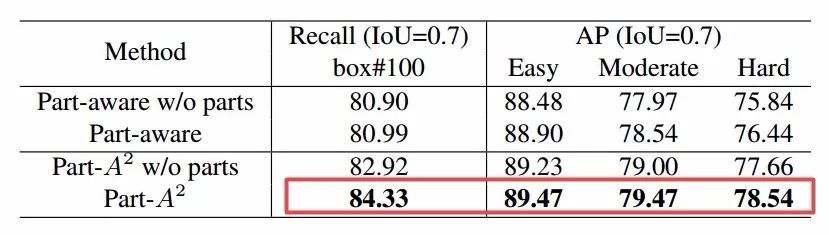
同时消溶性分析还显示这一方法通过对于特征的有效学习有效提高了召回率和精度。
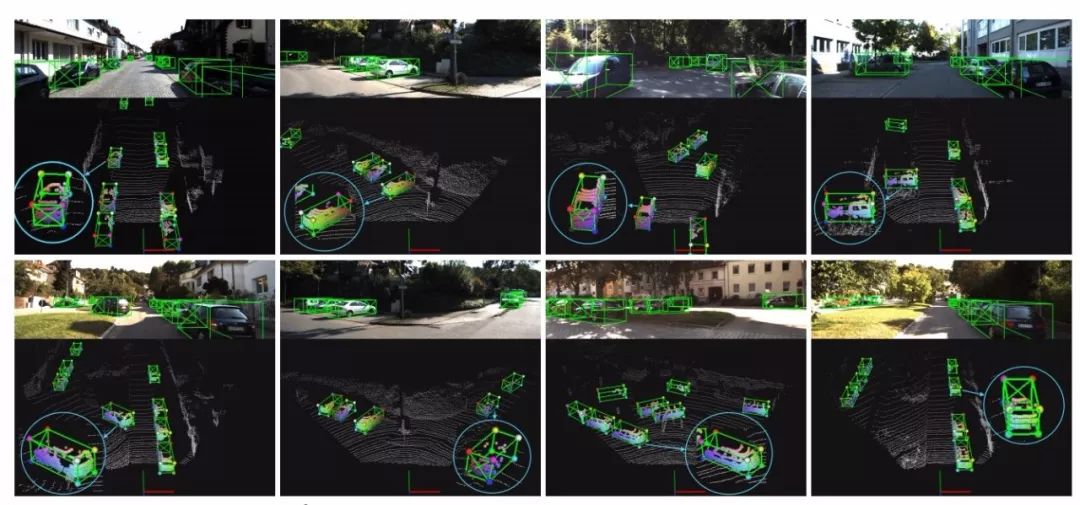
最终的结果可以看到对于场景中车辆的预测性能优异,而每个框内的部分位置也实现了较为精确的预测。
-
友思特方案 基于三维点云实现PCB装配螺丝视觉检测2024-08-28 1265
-
三维计算视觉研究分析2023-06-19 1699
-
基于深度学习的三维点云配准方法2022-11-29 2568
-
什么样的点可以称为三维点云中的关键点呢?2022-11-22 2735
-
三维点云数据的两种结构Kdtree和Octree2022-03-14 8999
-
基于三维激光点云的目标识别与跟踪研究2022-01-17 1244
-
点云的概念以及与三维图像的关系2021-08-17 8904
-
基于激光雷达点云的三维目标检测算法2021-05-08 2038
-
基于深度学习的三维点云语义分割研究分析2021-04-01 1497
-
一种基于概率框架的三维点云生成模型PointFlow2019-08-02 7640
-
三维快速建模技术与三维扫描建模的应用2018-08-07 4023
-
三维检测汽车零件 帮助汽车性能达标2017-08-21 2697
-
如何快速高效的完成汽车前盖板的三维检测?2017-08-11 4562
-
精密铸造+三维扫描=机械制造完美解决方案2017-08-09 3453
全部0条评论

快来发表一下你的评论吧 !
